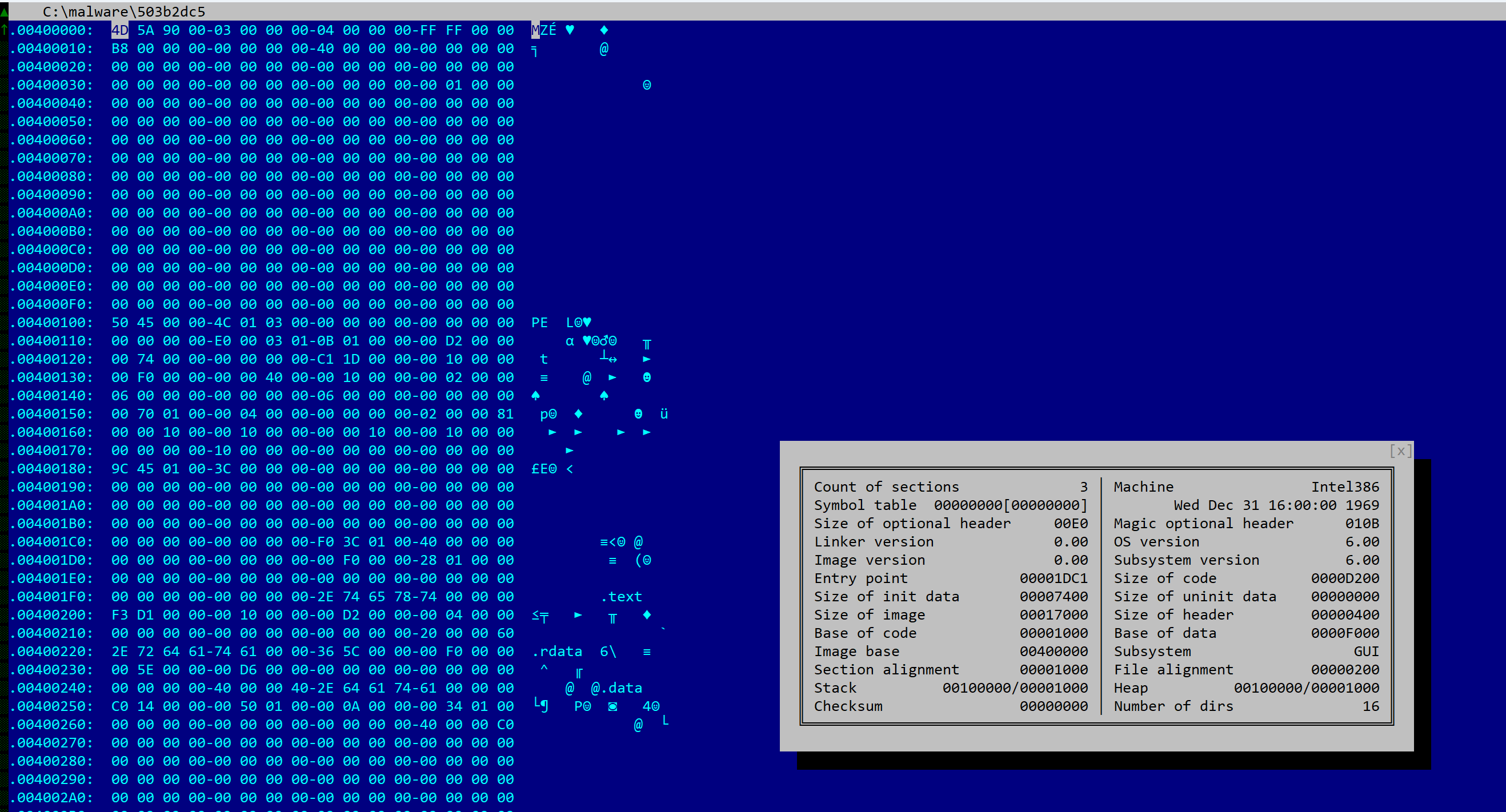
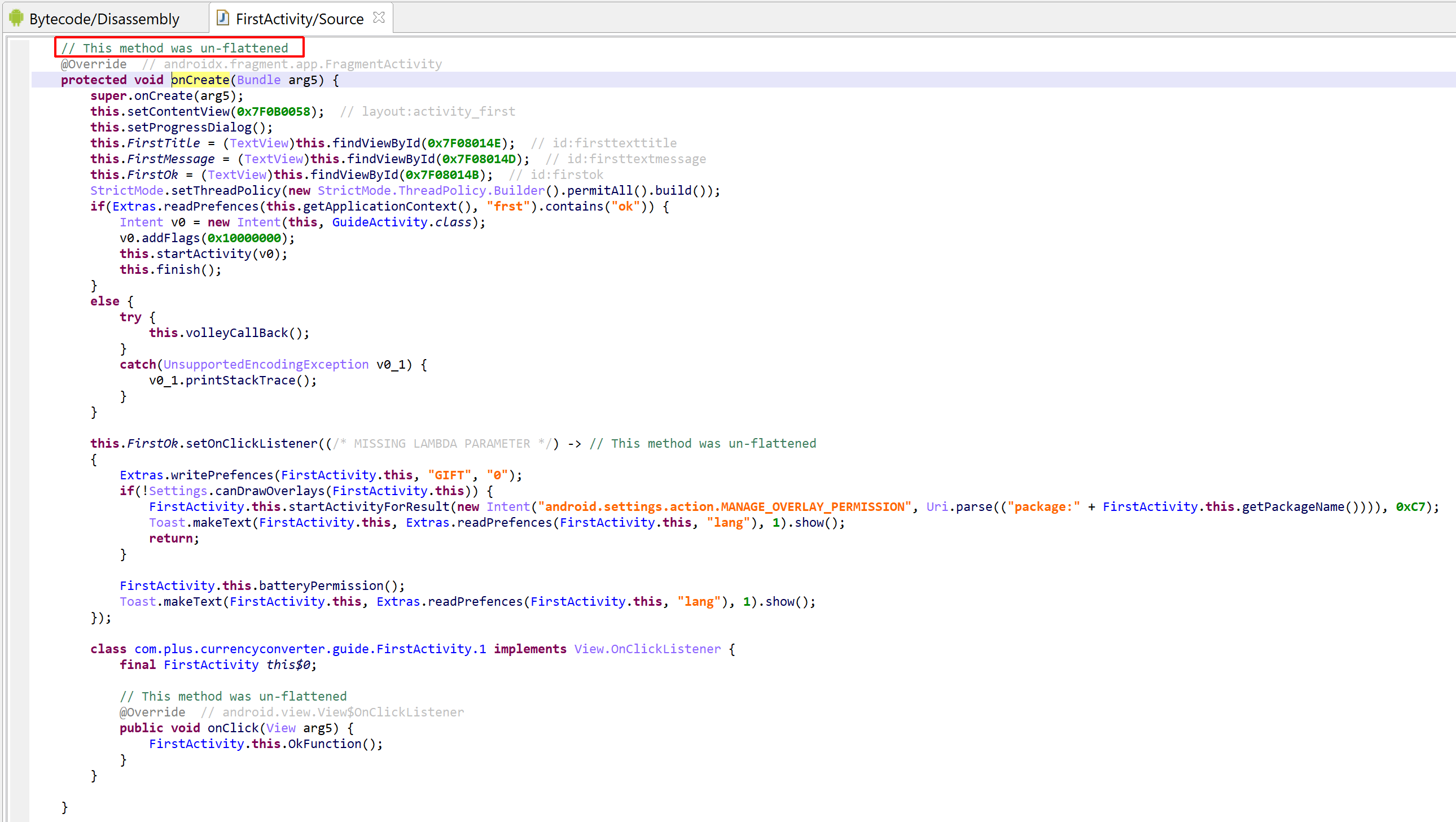
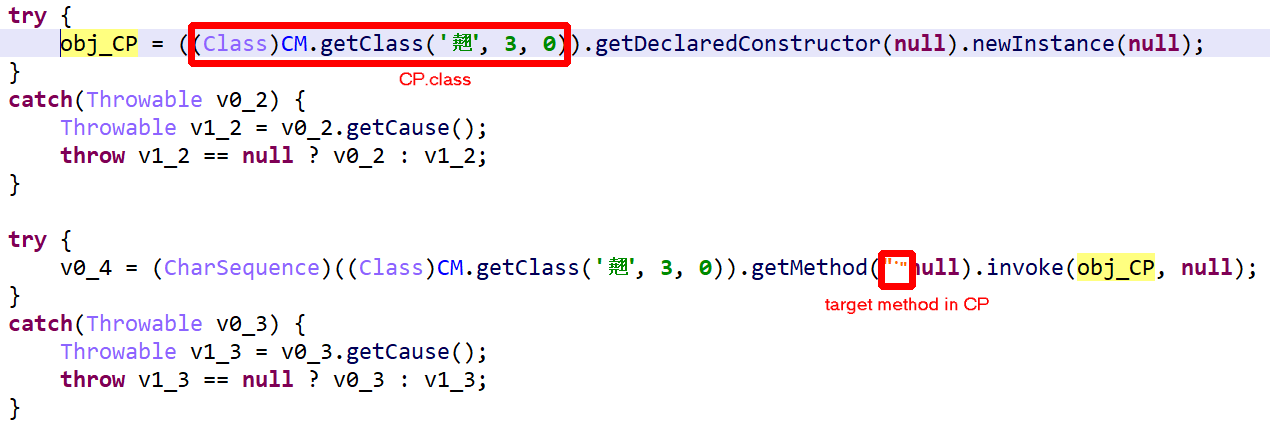
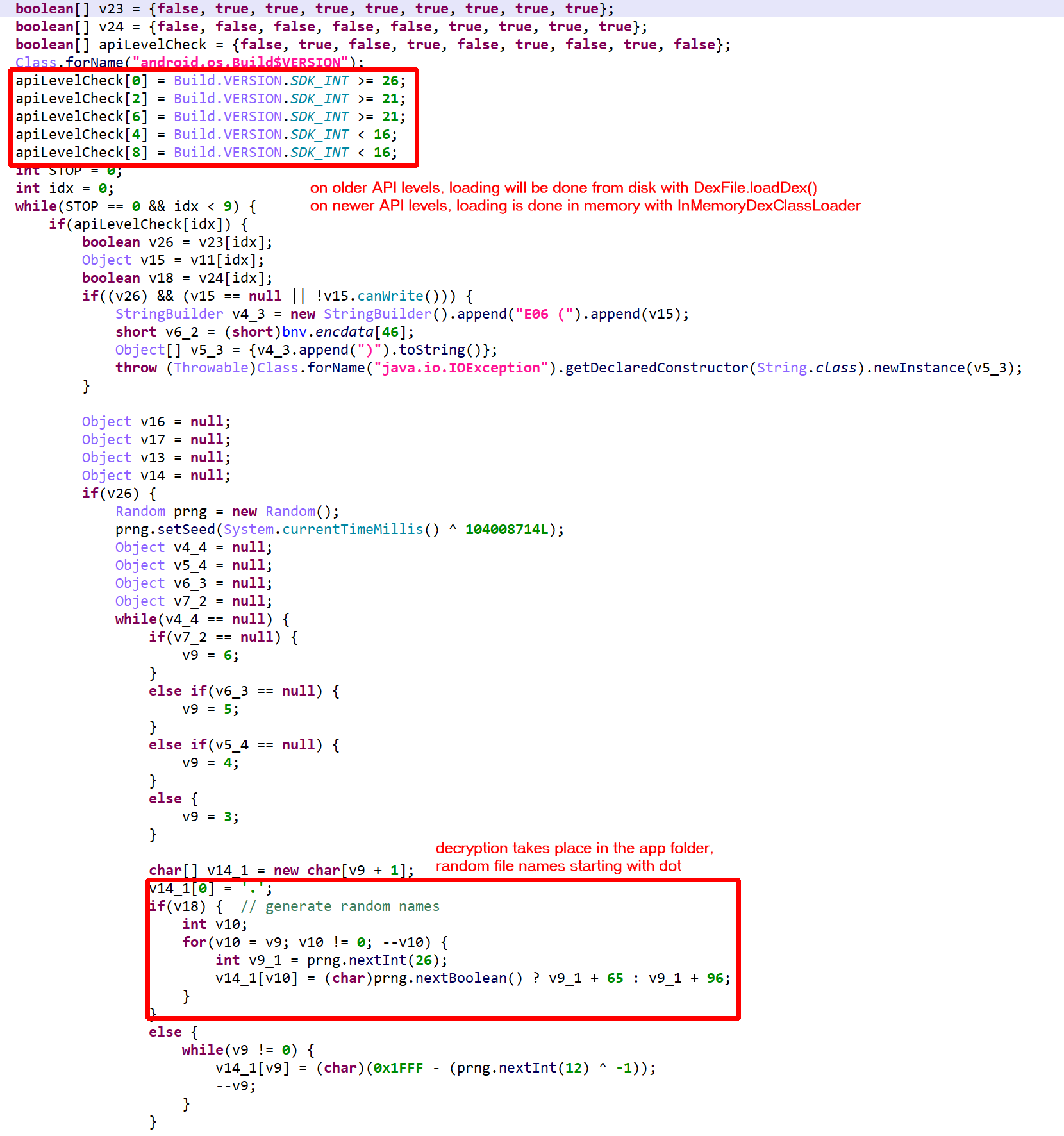
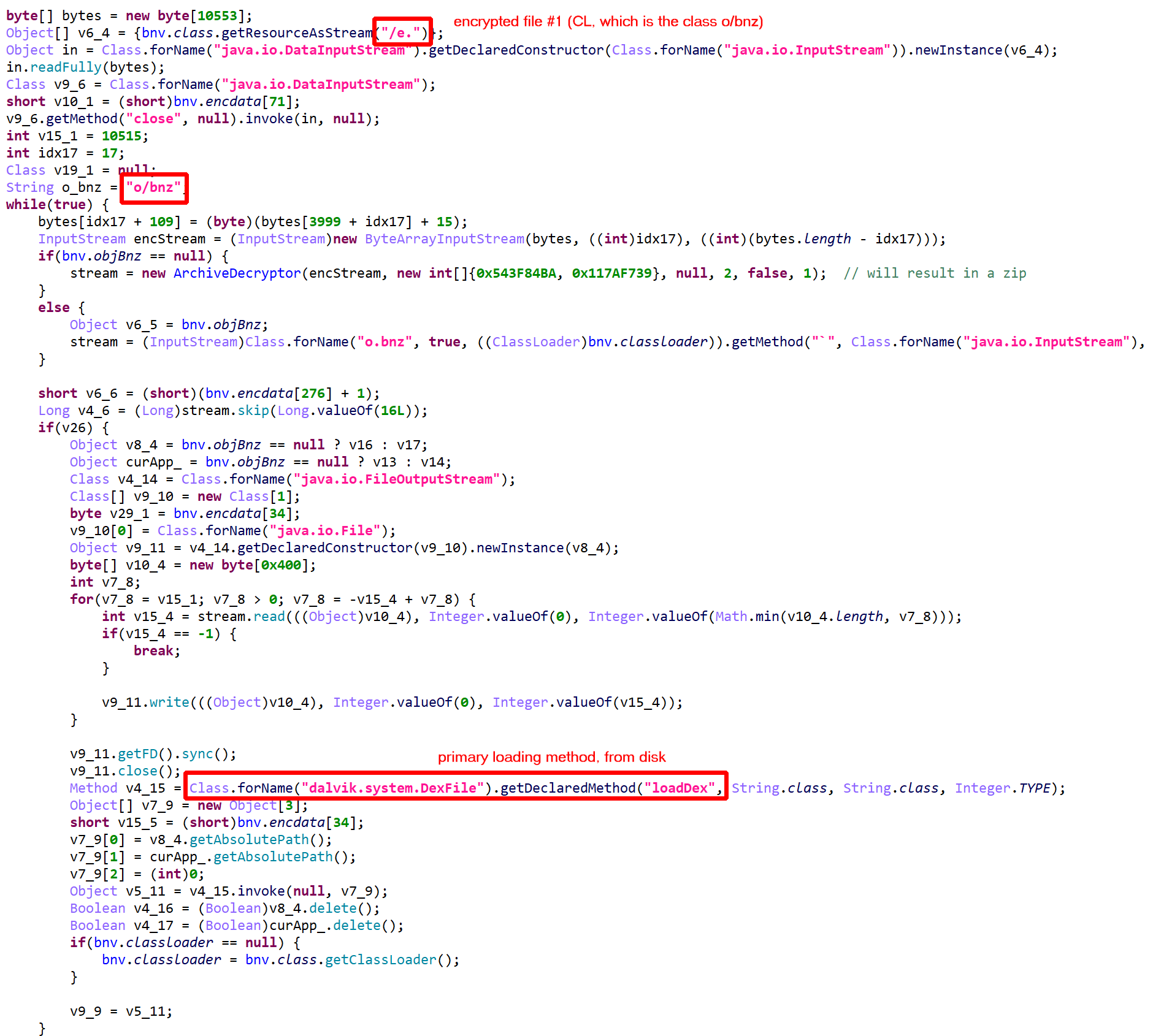
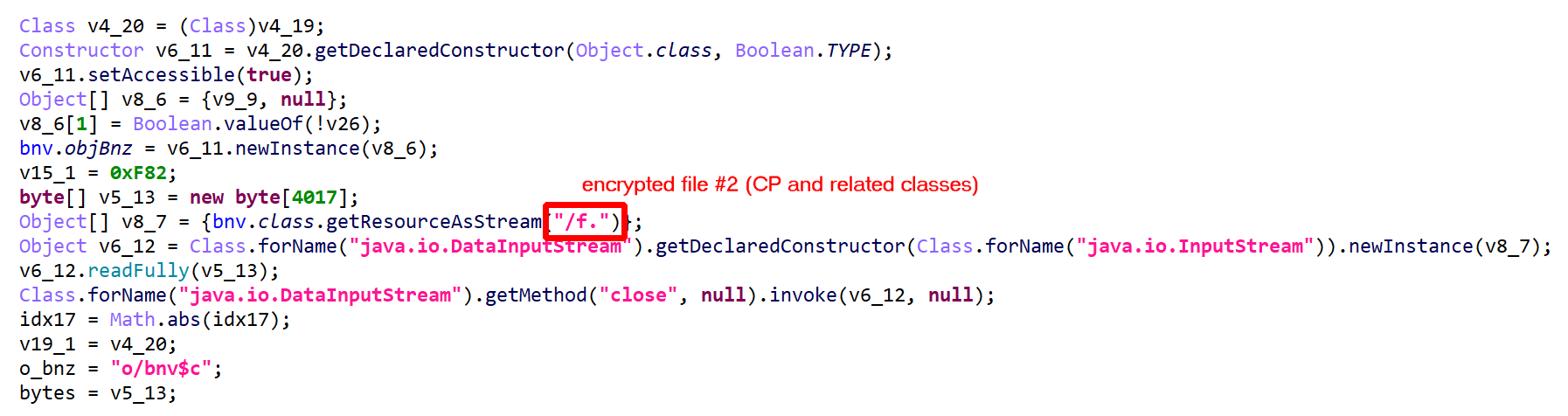
In this post, we are having a quick look at a relatively novel protection techniques found in the wild. The class we are looking at is com.X (SHA256: a519e4a20586807665d82ea28892e2ede184807868552f23210bf10c05727980).
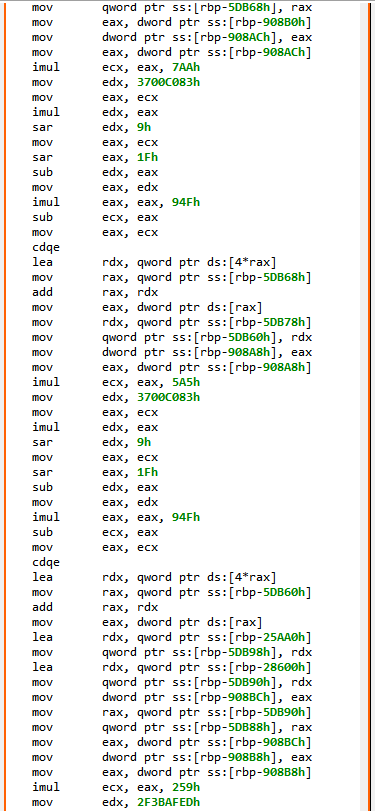
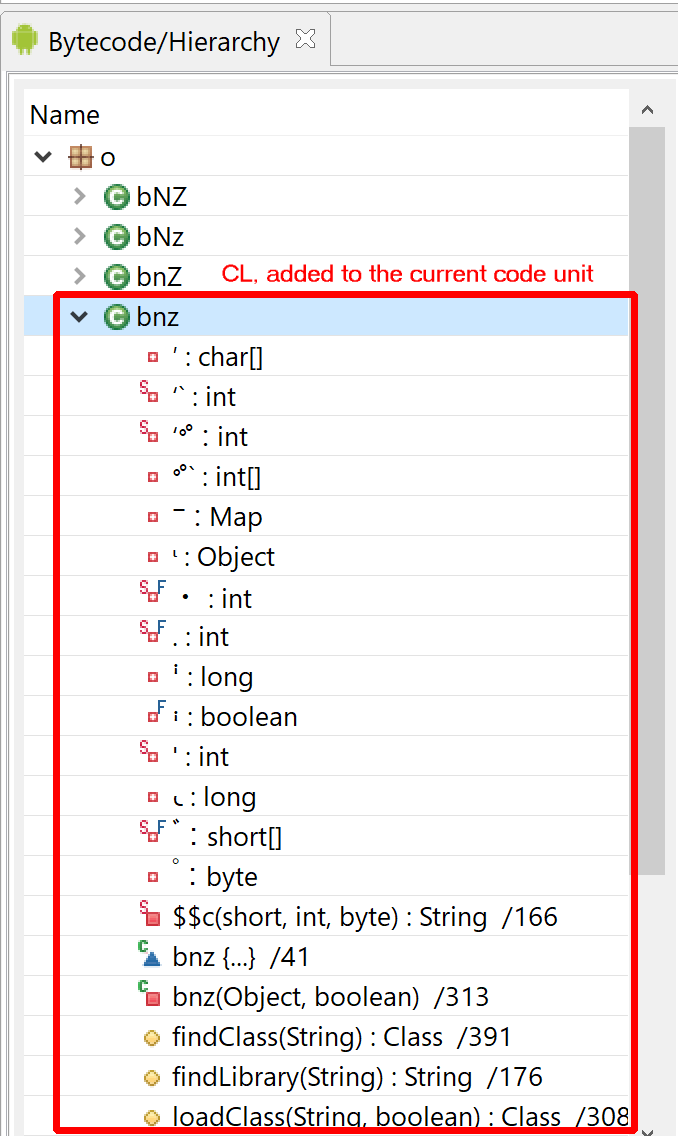
Have a look at the decompiled code, with standard JEB options. It was auto-deobfuscated and thoroughly cleaned by dexdec, JEB’s Dalvik decompiler:
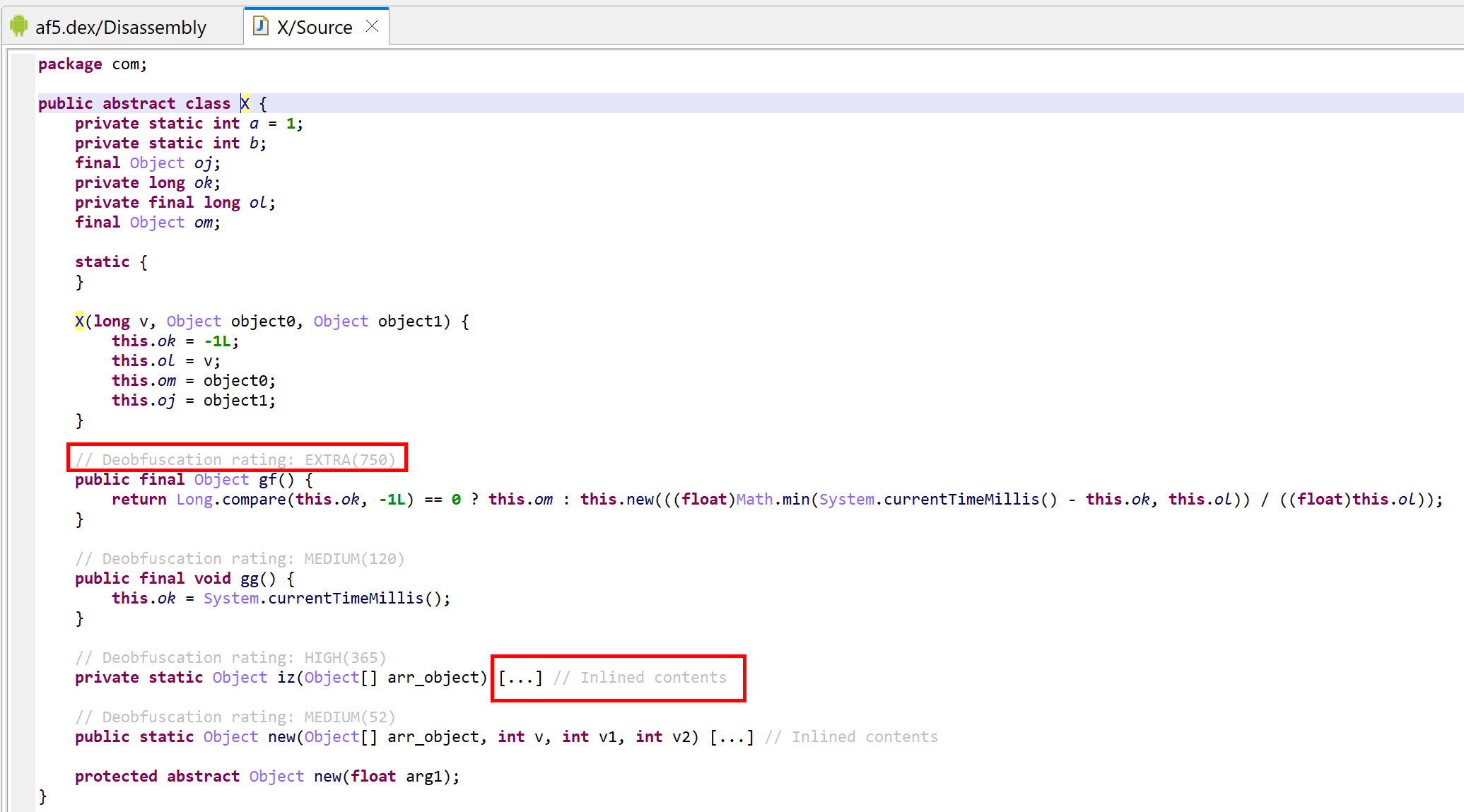
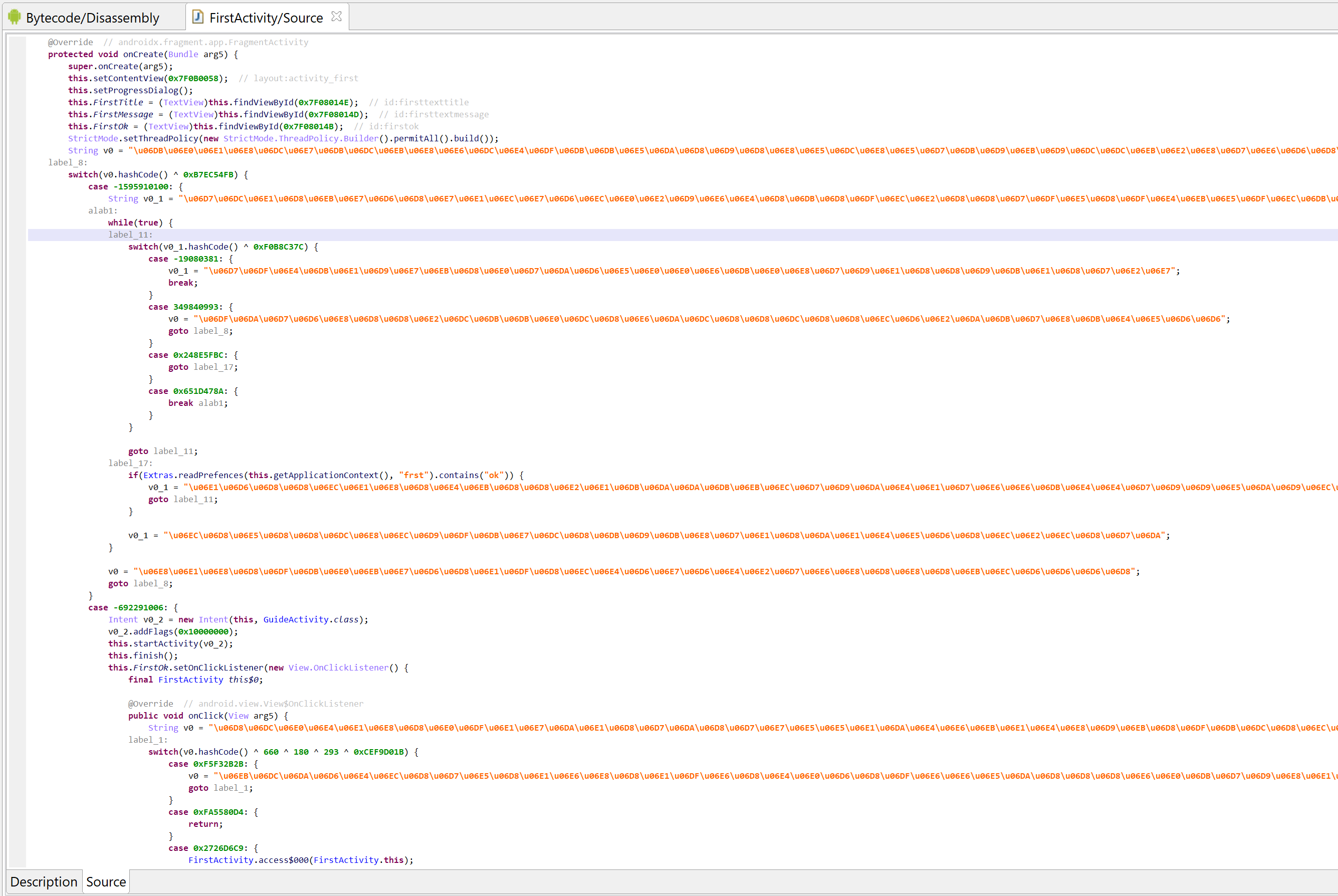
Decompilation of com.X with standard options (it’s been deobfuscated, and JEB is letting you know about it by providing deobfuscation ratings or scores as method comments)
A note on deobfuscation ratings
Two items to notice:
Some methods outputs are collapsed: their direct output was deemed useless because their code were inlined in corresponding callers. You may re-expand them with the Dash (-) action key, or via the Action menu, Collapse/Expand command.
Some decompiled methods have an auto-comment specifying a deobfuscation rating and score. This score is calculated from the result of IR optimizers tagged as DEOBFUSCATOR. If the score reaches a threshold, the rating (LOW – not shown-, MEDIUM, HIGH, EXTRA) is specified in the decompilation output, to give a hint to the user that the low-level code is protected, and that the high-level decomp was deobfuscated and cleaned.
The deobfuscation ratings for several methods of com.X are high. It looks like this class received a significant amount of protection. However, after clean-up, the meaningful code consists of two one-liner methods: one storing a timestamp (method gg), the other one calculating an elapsed time (method gf).
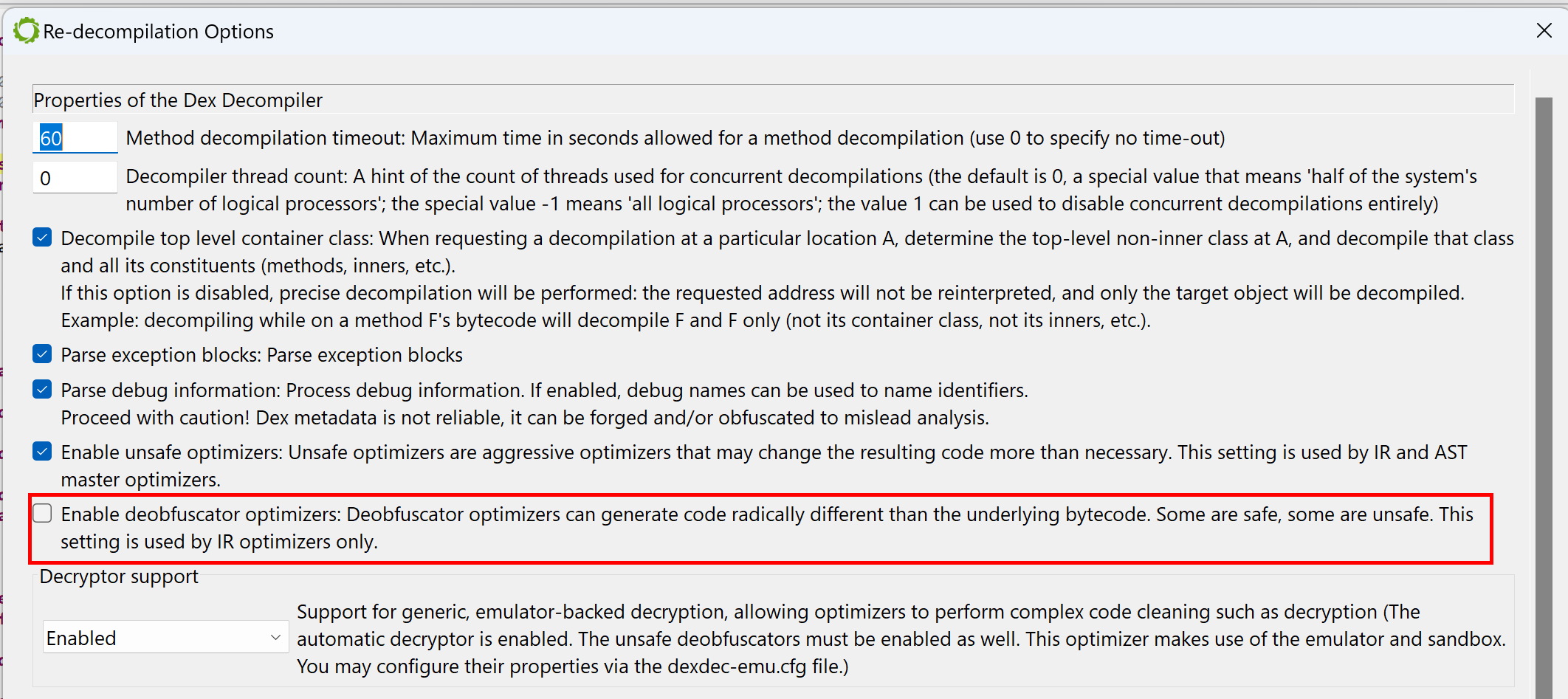
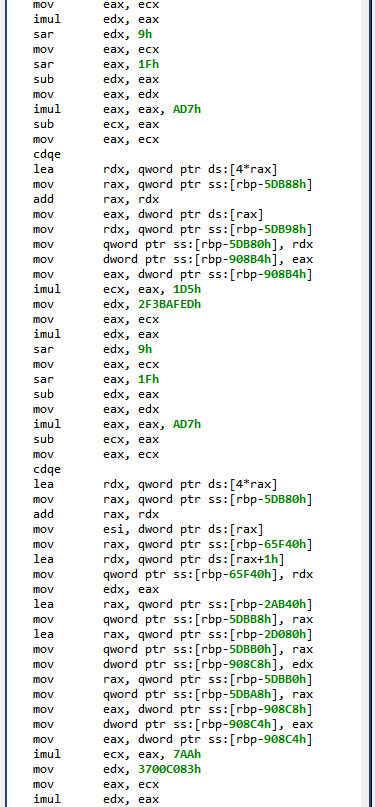
Let’s have a look at the decompiled code with deobfuscators disabled: Redecompile the code with CMD1+TAB (Action menu, Decompile with Options…), and untick “Enable deobfuscator optimizers”.
dexdec options when redecompiling with Action, Decompile with options…
The re-decompilation result is as follows:
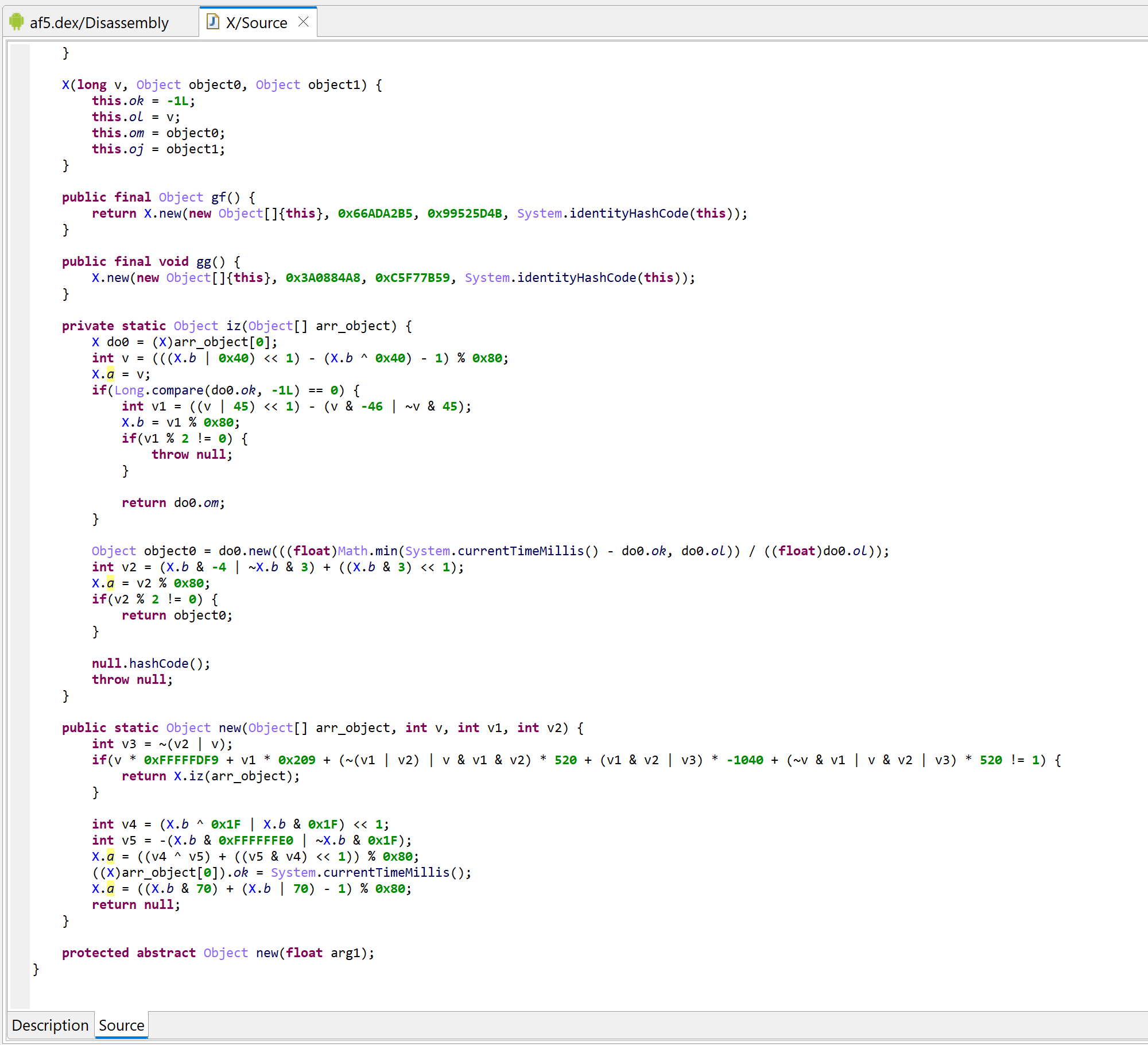
Decompilation of com.X with deobfuscators disabled
There is quite a lot to look at here, mainly, the fat routines and the opaque predicates.
Inlining “fat” functions
We see that gf calls new with a set of fixed integer (v, v1) as well as the identityHashCode of itself (v3, essentially a pseudo-random number). Similarly, gg also redirects to new, with a different set of arguments.
The methods gf() and gg() are wrappers calling the method new() with various keys
A quick examination of new shows that two code paths may be executed, based on the values of the provided triplet (v, v1, v2):
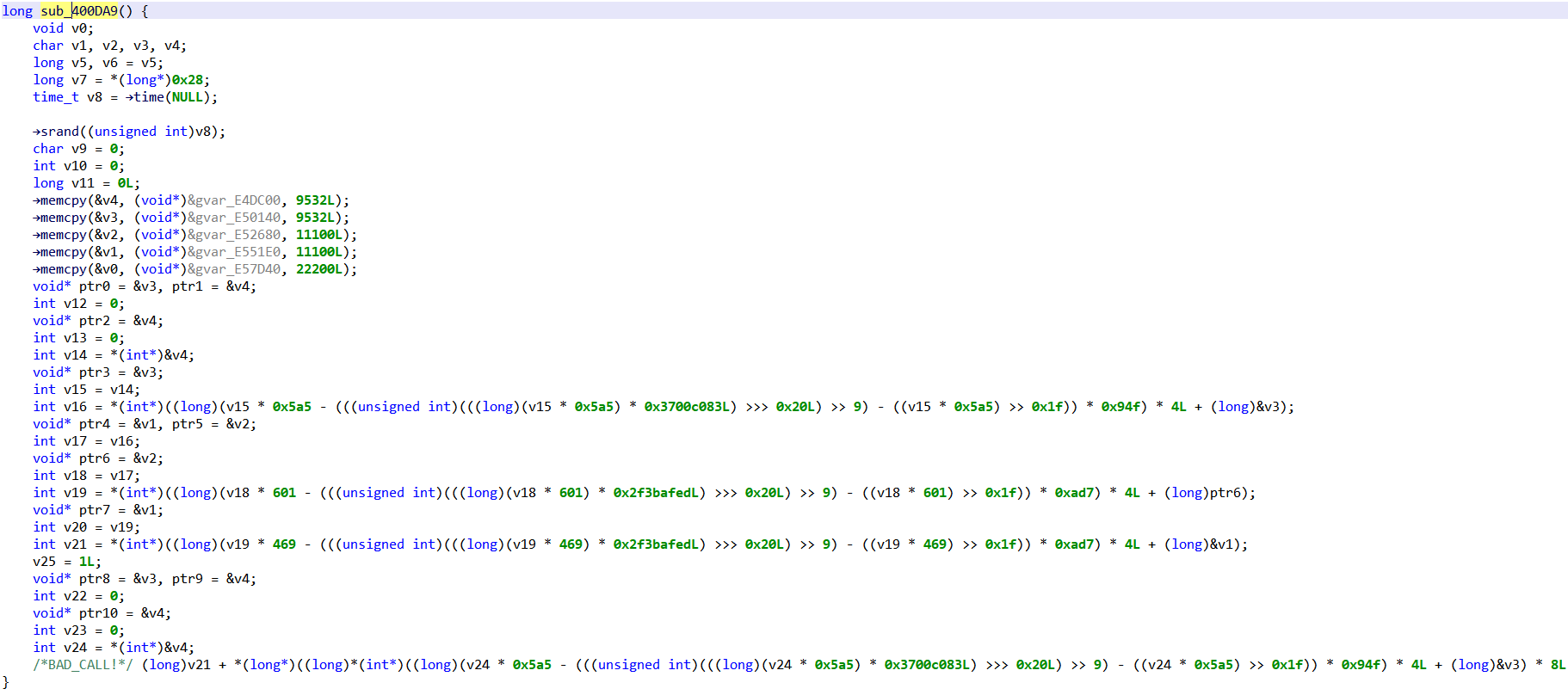
Decompilation of the synthetic “fat” function new, holding the real code of gf and gg
So, what happened? The protection of class com.X consisted of taking the bodies of code of gf and gg, merge them into a single method new (hence the name “fat”), and change the codes of gf and gg to trampoline into new with selectors to execute the proper code.
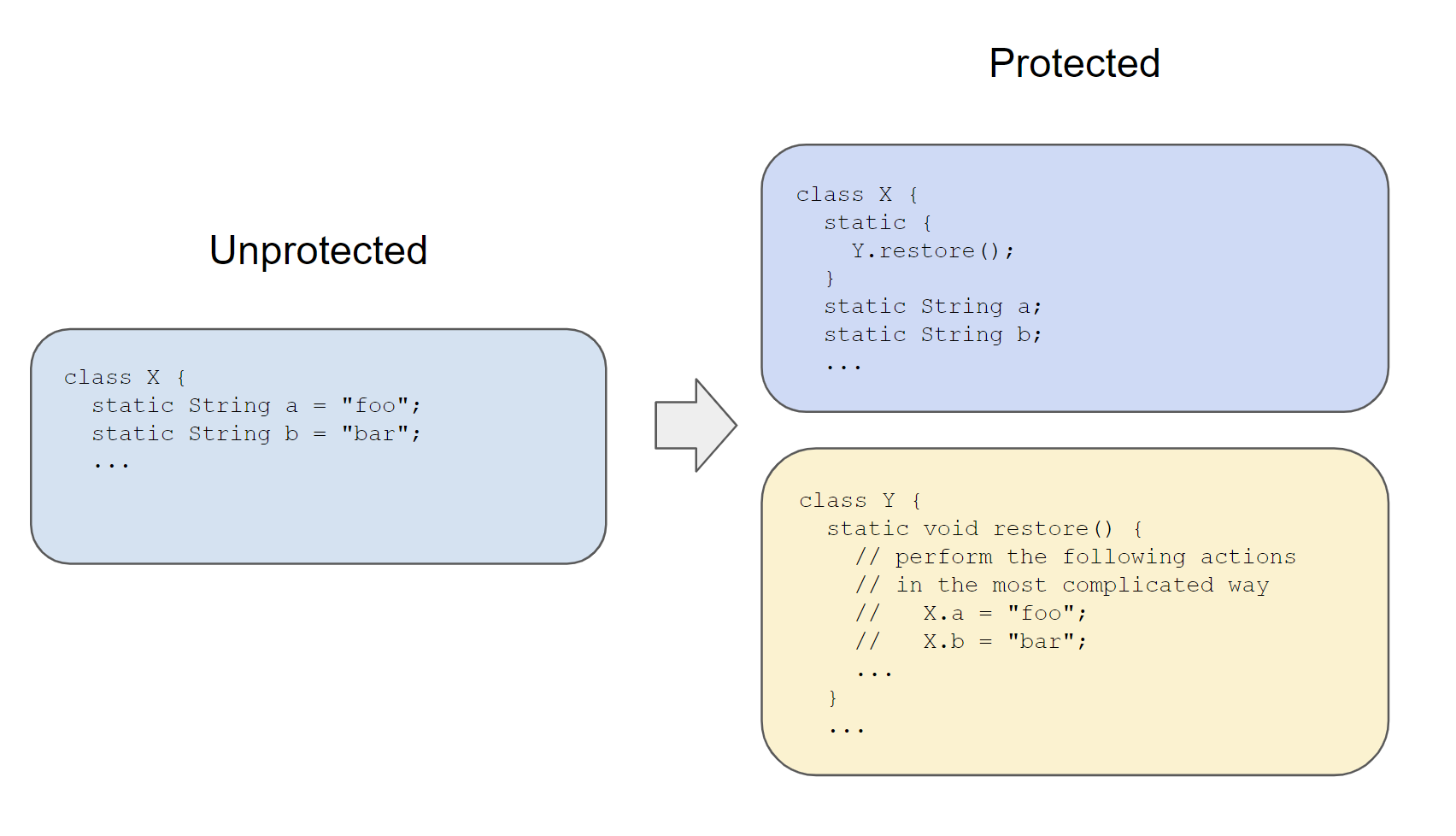
Here is an easier representation of that process, with a single selector (instead of a triplet):
// UNPROTECTED CLASS C
class C
int fld1;
int f1(int x) {
return 25 + x;
}
int f2() {
return 31 * fld1;
}
}
// PROTECTED CLASS C
class protected_C
int fld1;
int f1(int x) {
return (int)fat_routine(new Object[]{this, x}, 1);
}
int f2() {
return (int)fat_routine(new Object[]{this}, 2);
}
static Object fat_routine(Object[] params, int selector) {
if(selector == 1) {
return 25 + (int)params[1];
}
else if(selector == 2) {
return 31 * ((C)params[0]).fld1;
}
throw new RuntimeException(); // should not happen
}
}
Although the above code is trivial, we can use it to highlights two complications the decompiler will face when dealing with the more complex implementations made by the a real code protection system:
When to decide to inline, i.e. how to detect fat functions? (that question is outside the scope of this blog, and would not be of much interest to most readers)
What about complex selectors, such as a triplet with a pseudo-random int?
If JEB’s dexdec were to inline the calls to new as it is, we’d end up with the following decomps – not quite what we saw at the beginning of this article!
Decompilation the deobfuscators re-enabled, however the opaque predicate breaker was disabled
Resolving opaque predicates
Let’s look at method gf. We can see that the pseudo-random selector, after inlining, is used to calculate a predicate that will determine which path to take, i.e. do we execute the actual code for gf, or the code for gg?
Internally, JEB does quite a bit to simplify it, and ultimately, when all fast reductions and simplifications are applied, it will use the well-known Z3 SMT solver to break the predicate. In this case, regardless of the value of X, the predicate is true. Therefore, gf will be simplified to:
return X.iz(arr_object);
(Note that method iz is itself a candidate for inlining! At the end, the cleaned-up code shown in the introduction of this article will be generated.)
The use of Z3 and other external theorem provers that may be used by JEB and its plugins can be disabled in the option (see “Enable predicate breaker”):
The external predicate solver can be disabled in the options
Conclusion
We hope this quick note will shed some light on some newer features or recent upgrades that went into dexdec. Many of those were already present in gendec, the generic decompiler used for anything non-Dalvik, and it was about time to add those advanced clean-up passes into the Dalvik decompiler as well. In a sense, dexdec has caught up and even gone further than gendec on these aspects.
Which leads me to say there will likely be a Part 2 or at least an update for this blog, to highlight another complex deobfuscating task: the simplification of arithmetic operations consisting of bitwise operations and mixed boolean/arithmetic (MBA) expressions.
Stay tuned! Thank you to all our users and readers of this blog 🙂 Do not hesitate to reach out through the usual channels (Slack, email, X).
This is the second entry in our series showing how to use JEB and its well-known and lesser-known features to reverse engineer malware more efficiently. Part 1 is here.
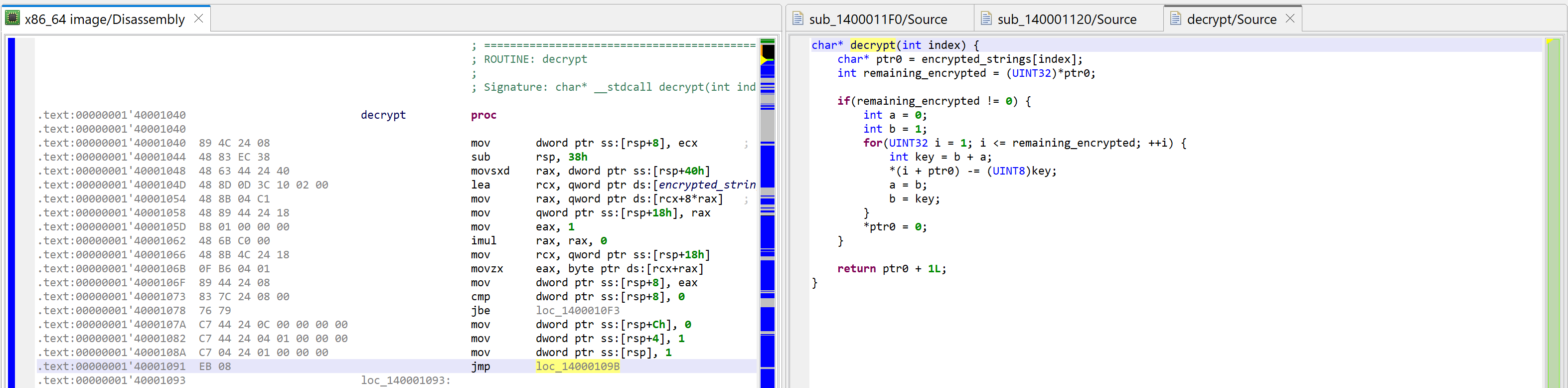
Today, we’re having a look at an interesting portion of a x86-64 Windows malware that carries encrypted strings. Those strings happen to be decrypted on the fly, the first time they’re required by some calling routine.
SHA256: 056cba26f07ab6eebca61a7921163229a3469da32c81be93c7ee35ddec6260f1. The file is not packed, it was compiled for Intel x86 64-bit processors, using an unknown version of Visual Studio. The file is dropped by another malware and its purpose is reconnaissance and information gathering. Let’s load it in JEB 5.8 and do a standard analysis (default settings).
Initial decompilations
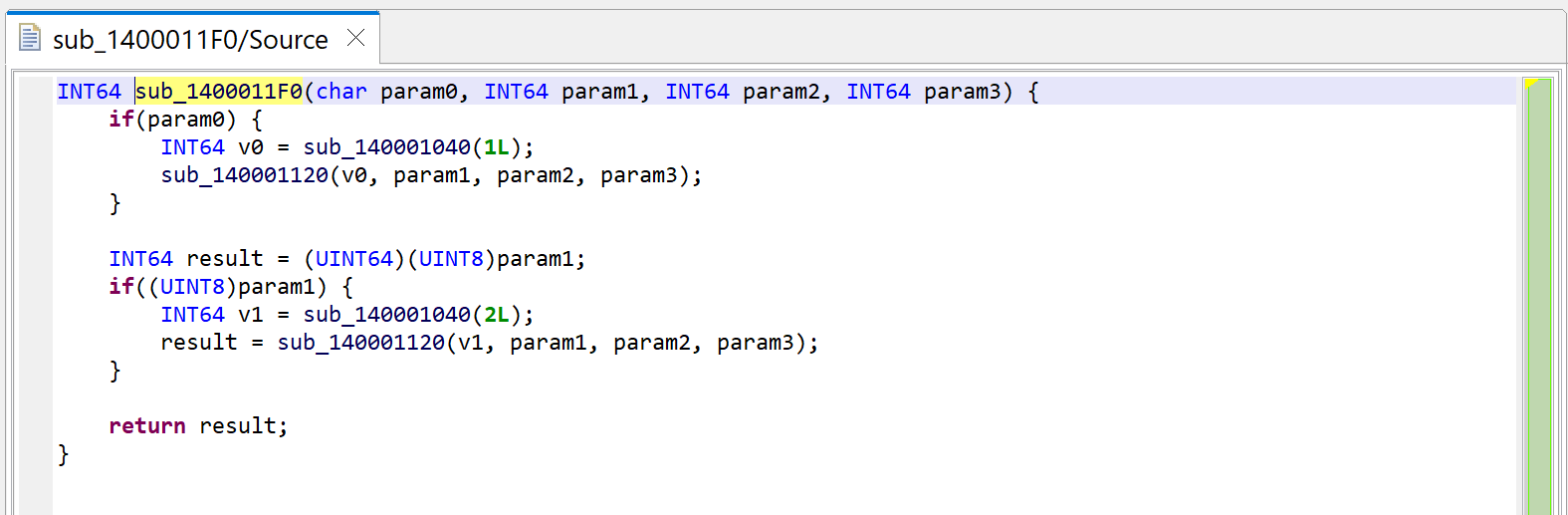
For the sake of showing what mechanism is at play, we’re first looking at sub_1400011F0. Let’s decompile it by pressing the TAB key (menu: Action, Decompile…).
Raw decompilation of sub_1400011F0, before examining its callees.
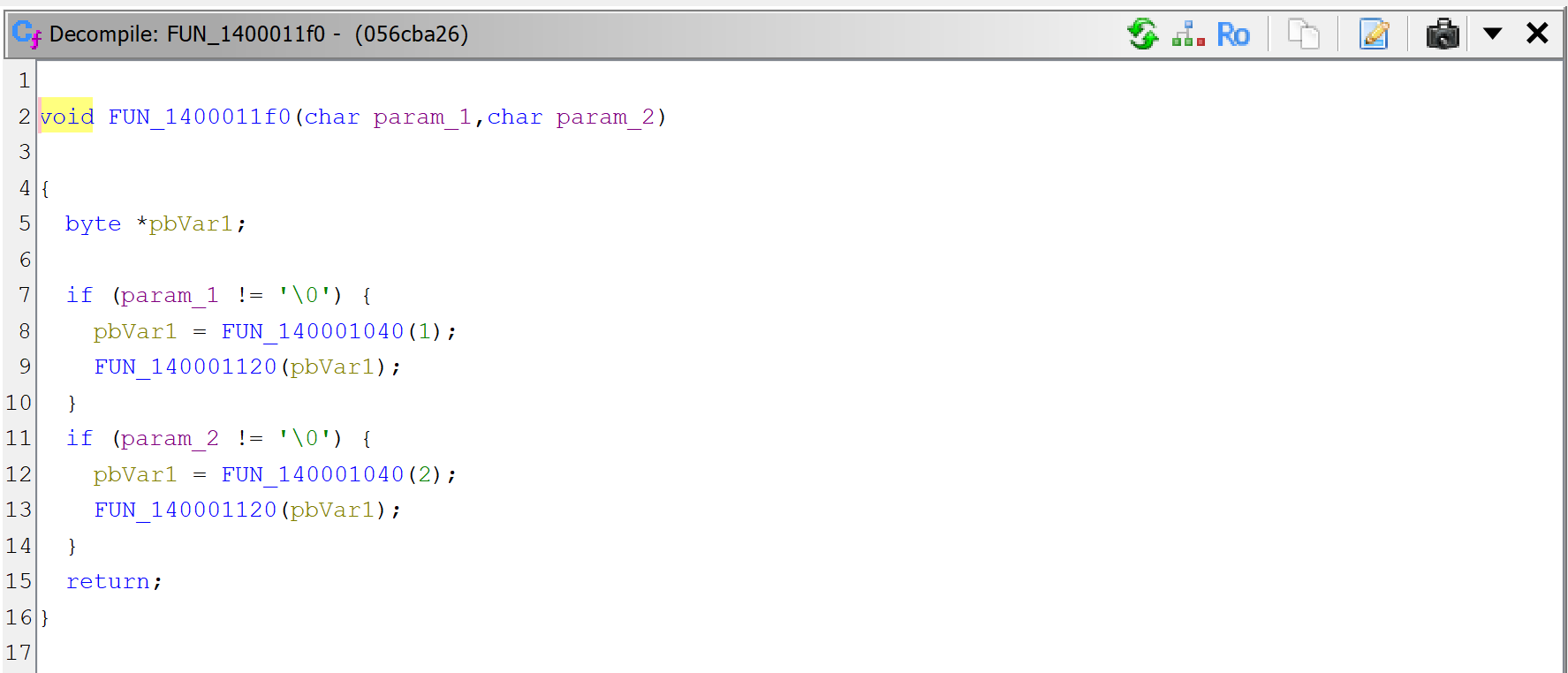
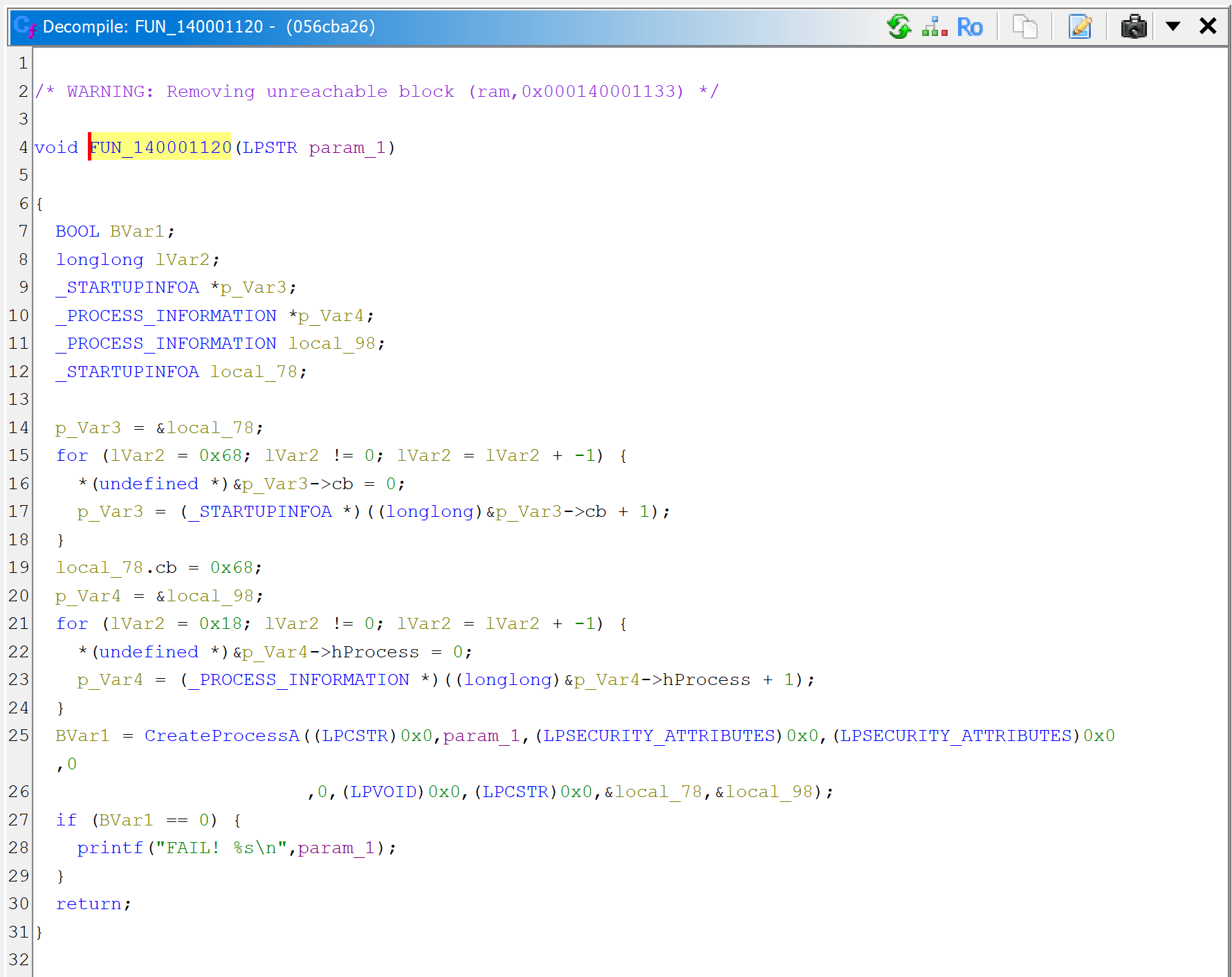
Then, let’s decompile the callee sub_140001120.
JEB can now thoroughly look at the routine and refines the initial prototype that was applied earlier, when the caller sub_1400011F0 was decompiled. It is now set to: void(LPSTR).
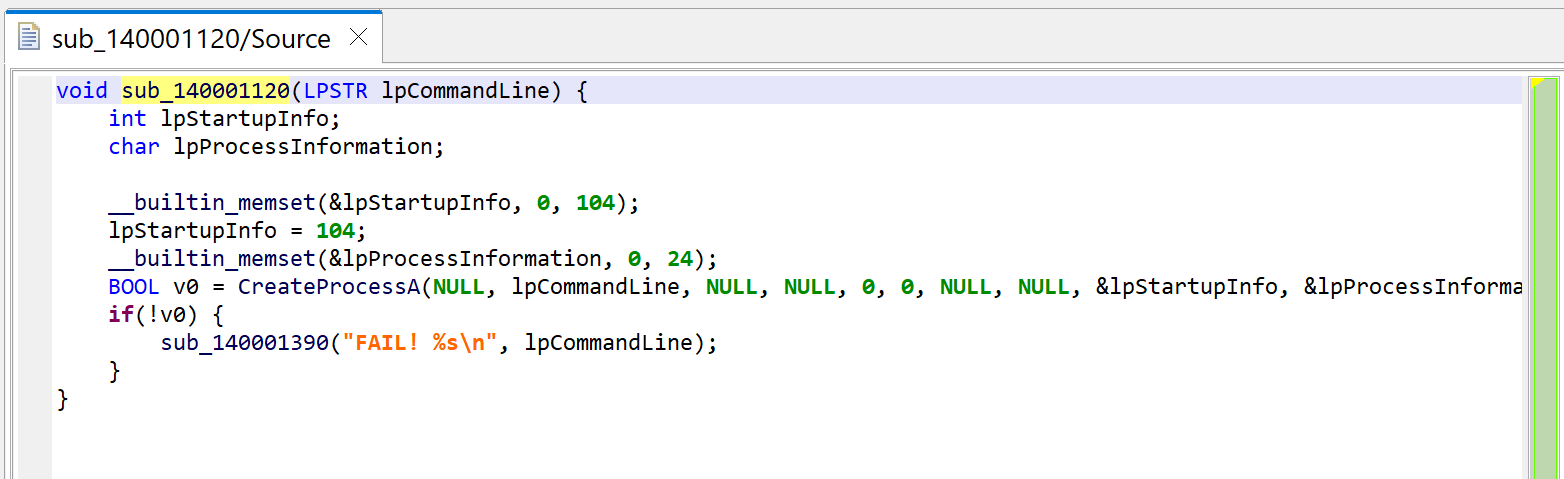
The code itself is a wrapper around CreateProcess; it executes the command line provided as argument.
sub_140001120 executes a command-line with CreateProcess. Note the refined prototype, void(LPSTR).
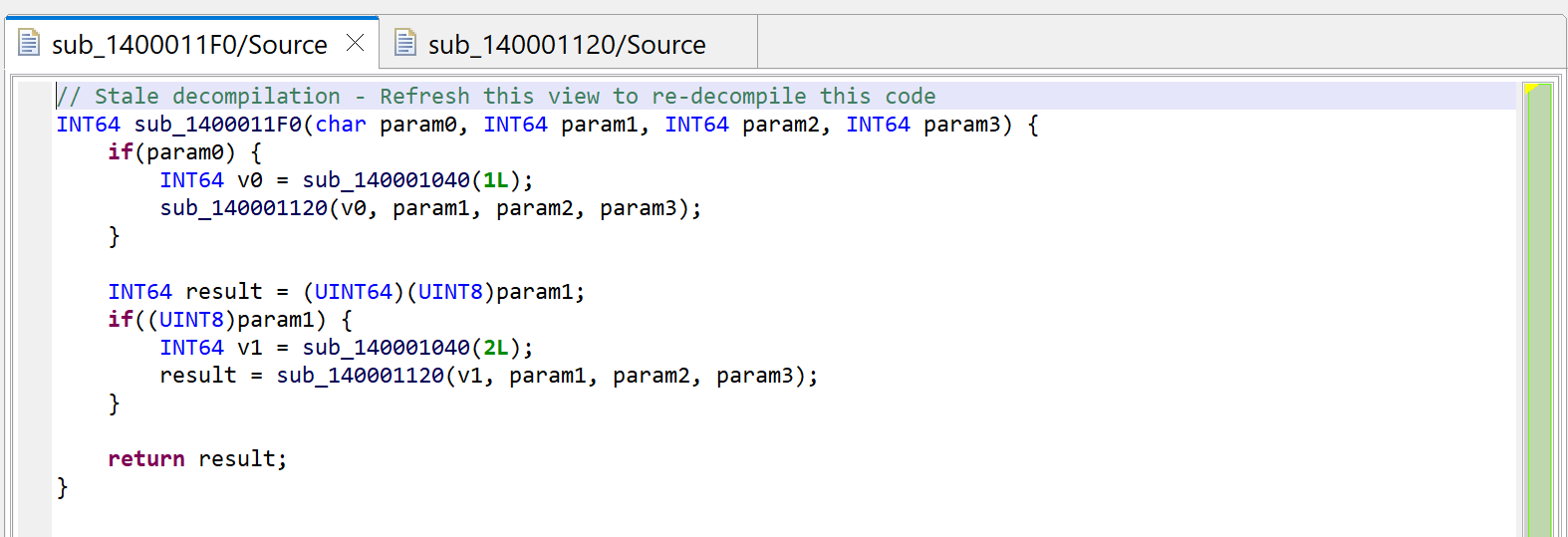
Press escape to navigate back to the caller, or alternatively, examine the callers by pressing X (menu: Action, Cross-references…) and select sub_1400011F0. You will notice that JEB is now warning us that the decompilation is “stale”.
The initial decompilation of sub_1400011F0 is stale after the decompilation of sub_140001120 yielded a better prototype.
Second decompilation
The reason is that the prototype of sub_140001120 was refined by the second decompilation (to void(LSPTR)), and the method can be re-decompiled to a more accurate version.
Let’s redecompile it: press F5 (menu: Window, Refresh). You can see that second decompilation below. What happened to the calls to sub_140001040?
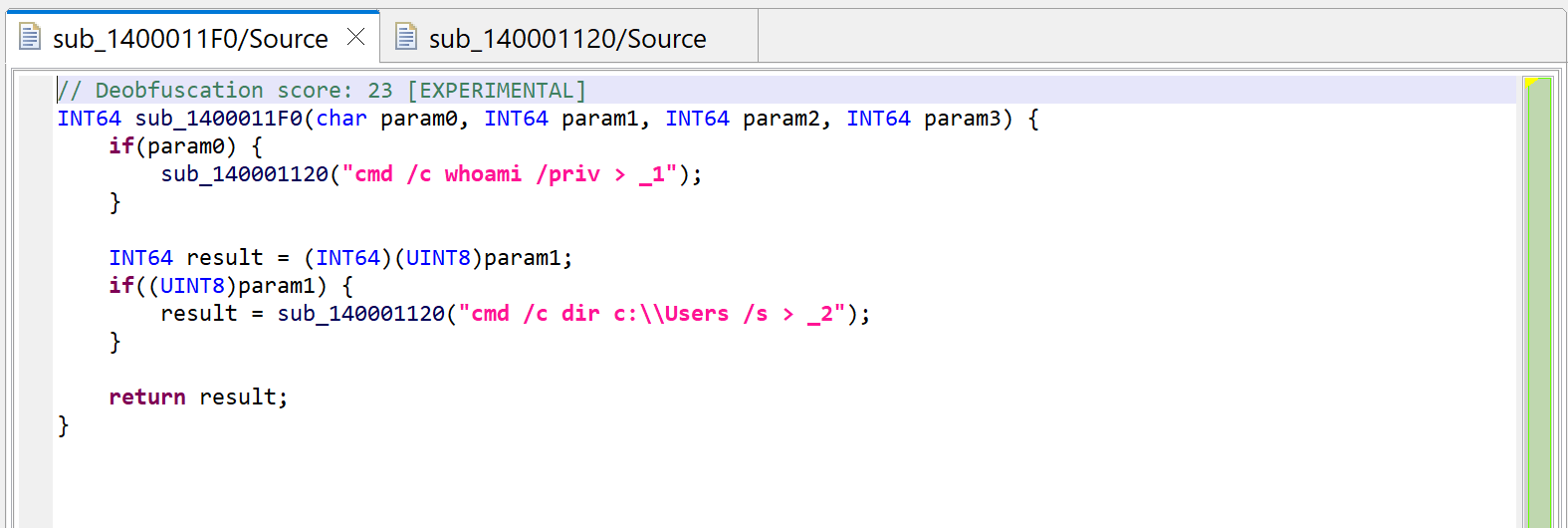
Second decompilation of sub_1400011F0, showing some decrypted strings instead of calls to sub_140001040.
String auto-decryption
Notice the following:
A “deobfuscation score” note was added as a method comment (refer to part 1 of the series)
The calls to sub_140001040 are gone, they have been replaced by dark-pink strings
JEB also notified us in the console:
Notifications about decrypted strings replace in decompiled code.
Dark-pink strings represent synthetic strings not present in the binary itself. Here, they are the result of JEB auto-decrypting buffers by emulating the calls to routine sub_140001040, which was identified as a string provider. Indeed, the decompilation of sub_140001120 helped, since the inferred parameter LPSTR was back-propagated to the callers, which in that case, was the return value of sub_140001040.
Auto-decryption can be very handy. In the case of this malware, we can immediately see what will be executed by CreateProcess: shells executing whoami and dir and redirecting outputs to files in the local folder. However, if necessary, this feature can be disabled via the “Decryptor Options” in the decompiler properties:
Menu: Options, Back-end properties… to globally disable this in the future, except for your current project
Menu: Options, Specific Project properties… for the current project only
Or you may simply redecompile the method with CTRL+TAB (menu: Action, Decompile with options…) and disable string decryptor for specific code
The string auto-decryptor may be enabled or disabled in the options
The decryptor routine
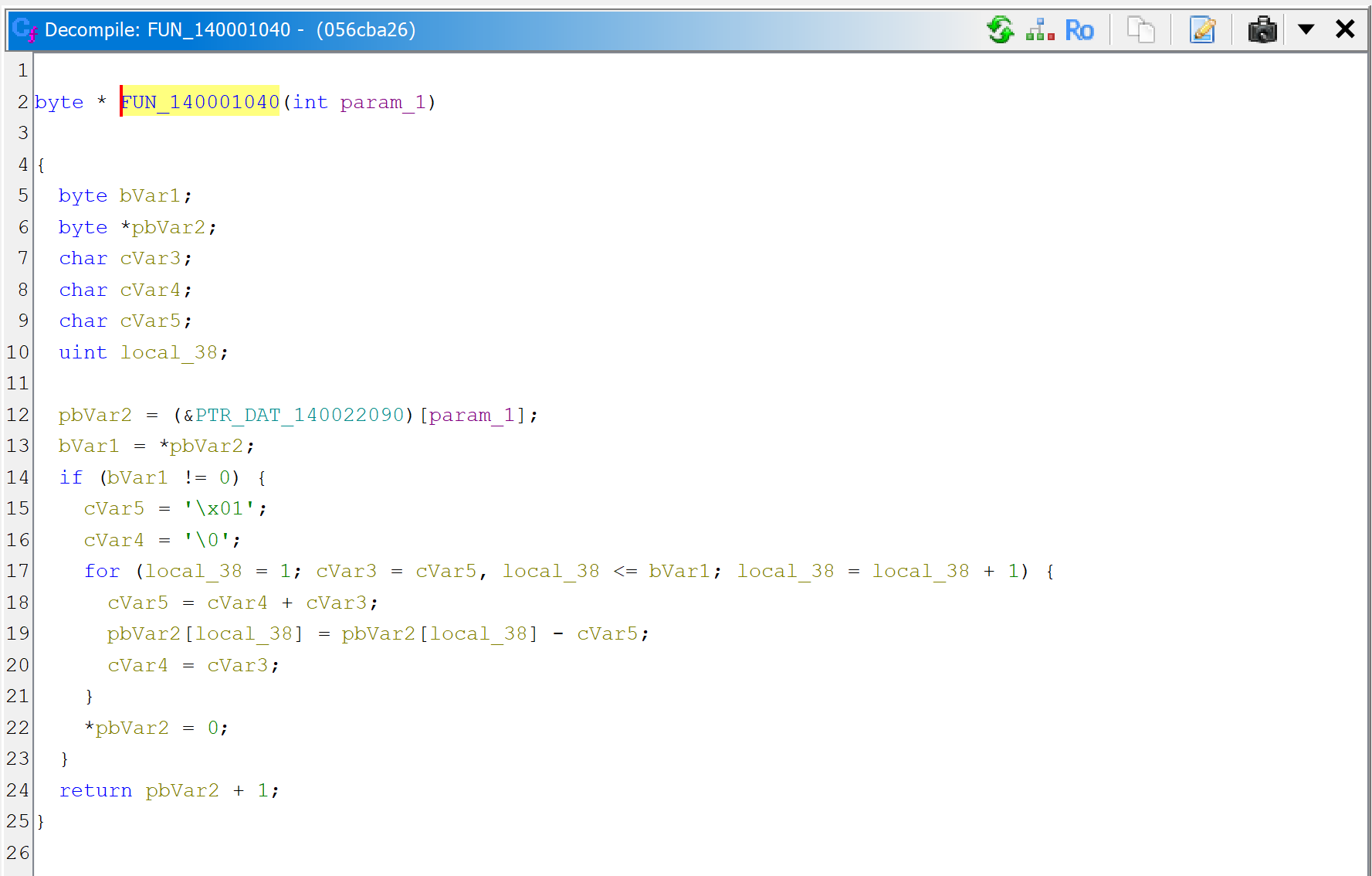
What is sub_140001040 anyway? Let’s navigate to the routine in the disassembly and decompile it.
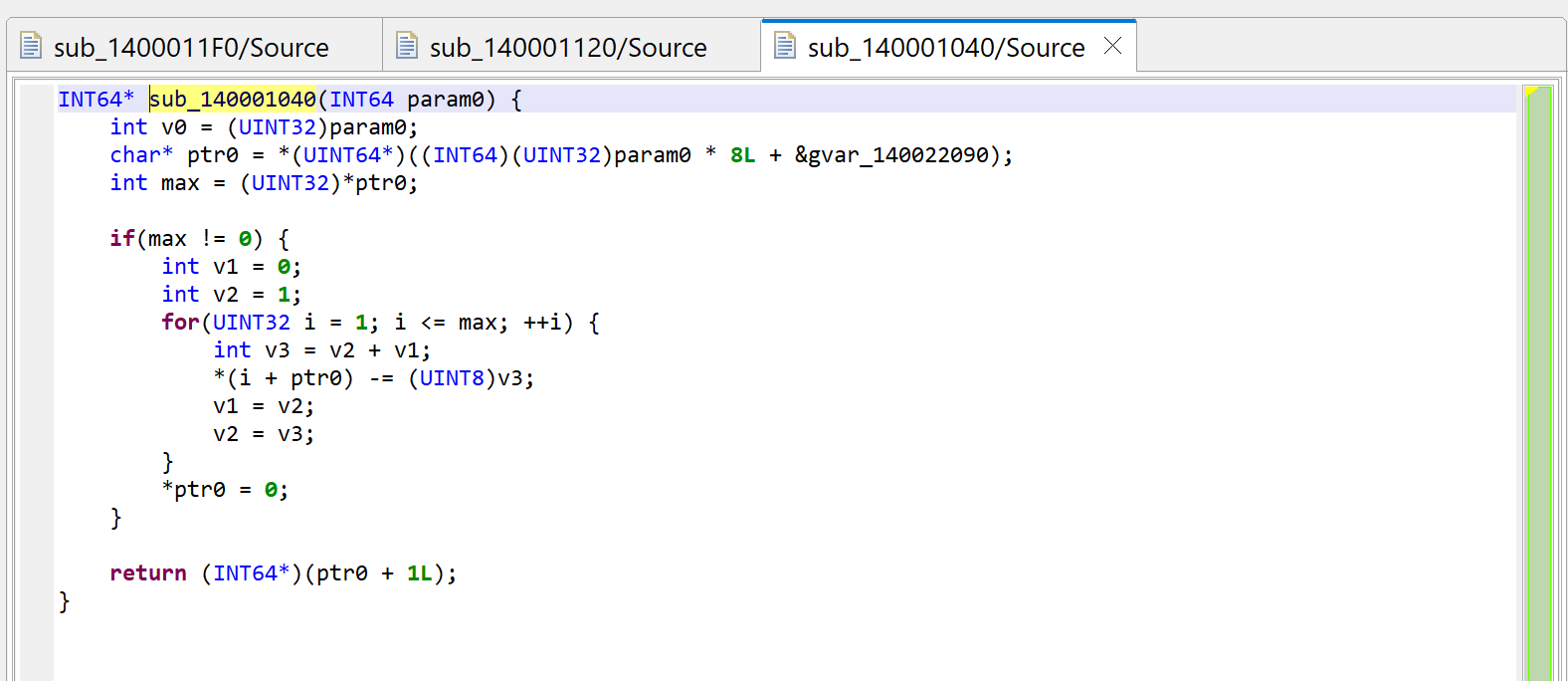
A raw decompilation of the decryptor code, sub_140001040
After examination of the code, we can adjust things slightly:
The global gvar_140022090 is an array of PCHAR (double-click on the item; rename it with N; change the type to a PCHAR using Y; create an array from that using the * key).
The prototype is really PCHAR(int), we can adjust that with Y.
The first byte of an entry into encrypted_strings is the number of encrypted bytes remaining in the string; if 0, it is fully decrypted and subsequent calls will not attempt to decrypt bytes again.
The key variable is v3 is the key; let’s rename it with N. Note that the key at (i) is the sum of the previous two keys used by indices (i-1), (i-2); the initial tuple is (0, 1). This looks like a Fibonacci sequence.1
The decryptor (sub_140001040) after analysis.
Comparison with GHIDRA
For comparison sake, here are GHIDRA 11 decompilations.
The caller (sub_1400011F0) decompiled by GHIDRA 11.0.The decryptor (sub_140001040) decompiled by GHIDRA 11.0.The CreateProcess wrapper (sub_140001120) decompiled by GHIDRA 11.0. Notice that the low-level structure initialization code adds quite a bit of confusion.
Conclusion
JEB decompilers2 do their best to clean-up and restore code, and that includes decrypting strings when it is deemed reasonable and safe.
That concludes our second entry in this “How to use JEB” series. In the next episodes, we will look at other features and how to write interesting IR and AST plugins to help us further deobfuscate and beautify decompiled code.
As always, thank you for your support, and happy new year 2024 to All 😊 – Nicolas
–
Interestingly, the JEB assistant (call it with the BACKTICK key, or menu: Action, Request Assistant…) would like to rename this method to “fibonacci_sequence“! Not quite it, but that’s a relevant hint!) ↩
Note the plural: dexdec – the Dex decompiler – has had string auto-decryption via emulation for a while; its users are well-accustomed to seeing dark-pink strings in deobfuscated code! ↩
We’re kicking off a malware analysis series explaining how to use JEB Decompiler to perform reverse engineering tasks ranging from out-of-the-box actions to complex use cases requiring scripts or custom plugins.
In this first entry, we look at a Windows malware compiled for x86 32-bit targets. The malware is an Ethereum cryptocurrency stealer. It monitors and intercepts clipboard activity to find and replace wallet addresses by an address of its own — presumably, one controlled by the malware authors to collect stolen ether.
Quick look at the malware
The file has a size of 81Kb, is compiled for x86 platforms. Although it does not appear to be packed, most metadata elements of the PE header were scraped. There is no rich data or timestamp.
If you are familiar with JEB, its terminology, and the organization of its UI elements, you may skip the next section and go directly to “Examining the code”.
Opening the file in JEB
Let’s fire up JEB. Any recent build (5.7+) with the x86 analysis modules and decompiler will do, i.e. JEB Community Edition or JEB Pro.
We open the file and keep the default settingsA view of the GUI after the initial analysis (from top-left, clockwise: project explorer, main workspace, and code hierarchy)
Project and units
The top-left view shows the project, along with a single artifact (the input file) and the analysis units created by JEB:
The artifact file has a blue-round icon
The top-level unit is a winpe unit
It has one child unit at the moment, named “x86 image”, of type x86.
The bottom-left view shows a list of code routines resulting from the analysis of the file.
Disassembly
By default, the main panel shows the disassembly window.
You may press the SPACE bar to switch to a graph view of the code (menu: Action, Graph…). In the graph view, only a single method is rendered at a time.
CFG (control flow graph) view of a disassembled routine
PE unit
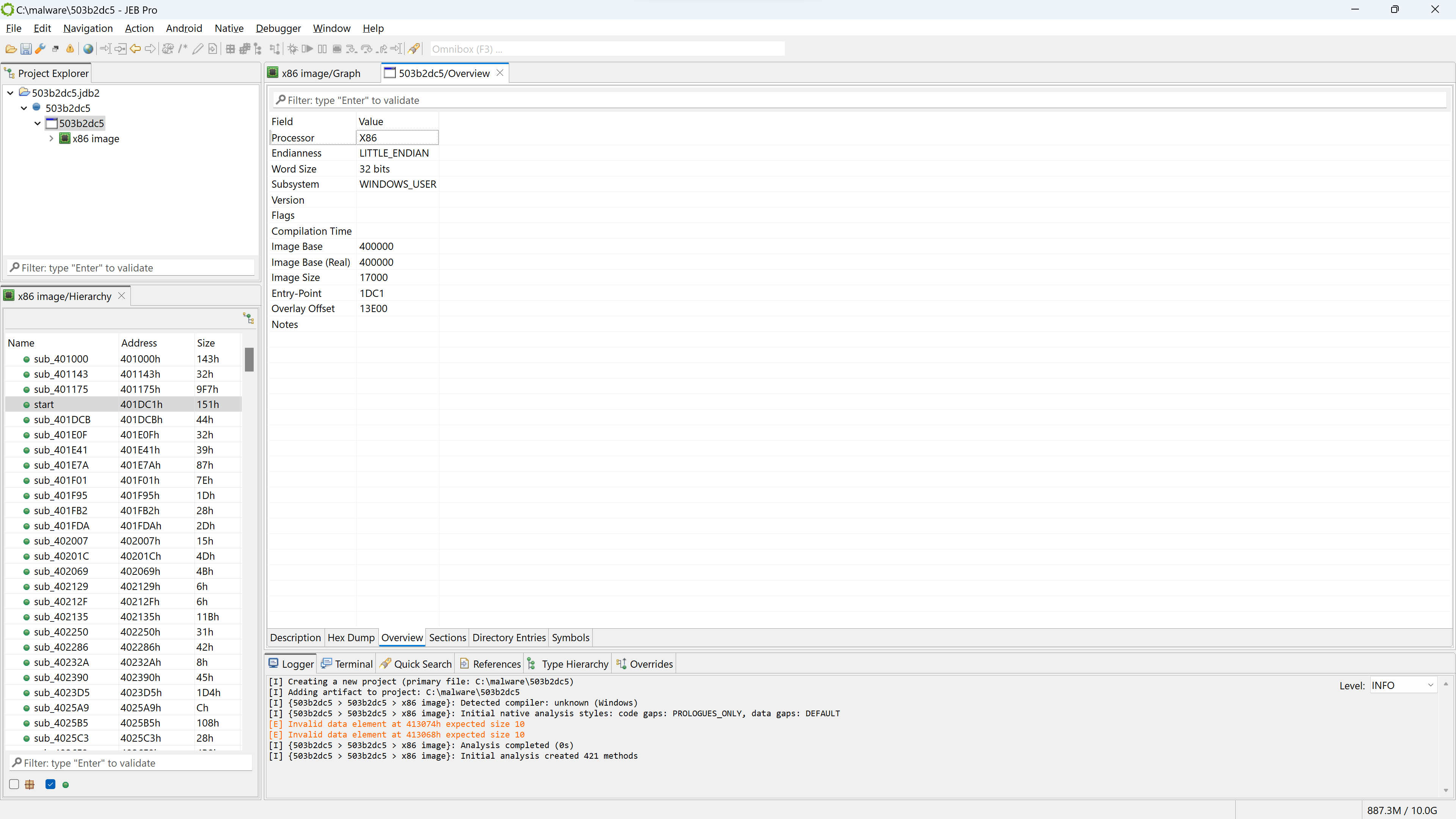
If you wish to have a look at the PE file in more details, open the winpe unit. Double-click the corresponding node in the project hierarchy.
View of a winpe unit’s “Overview” fragment
The winpe unit view provides several information, organized in fragments that can be seen below the unit view: Description, Hex Dump, Overview (the default fragment), Sections, Directory Entries, Symbols, etc.
Note that if the PE had not been stripped, we would probably see a compilation timestamp as well as additional sub-units detailing the Rich Header data. For Windows executables, that data is important to perform fine-grained compiler identification.
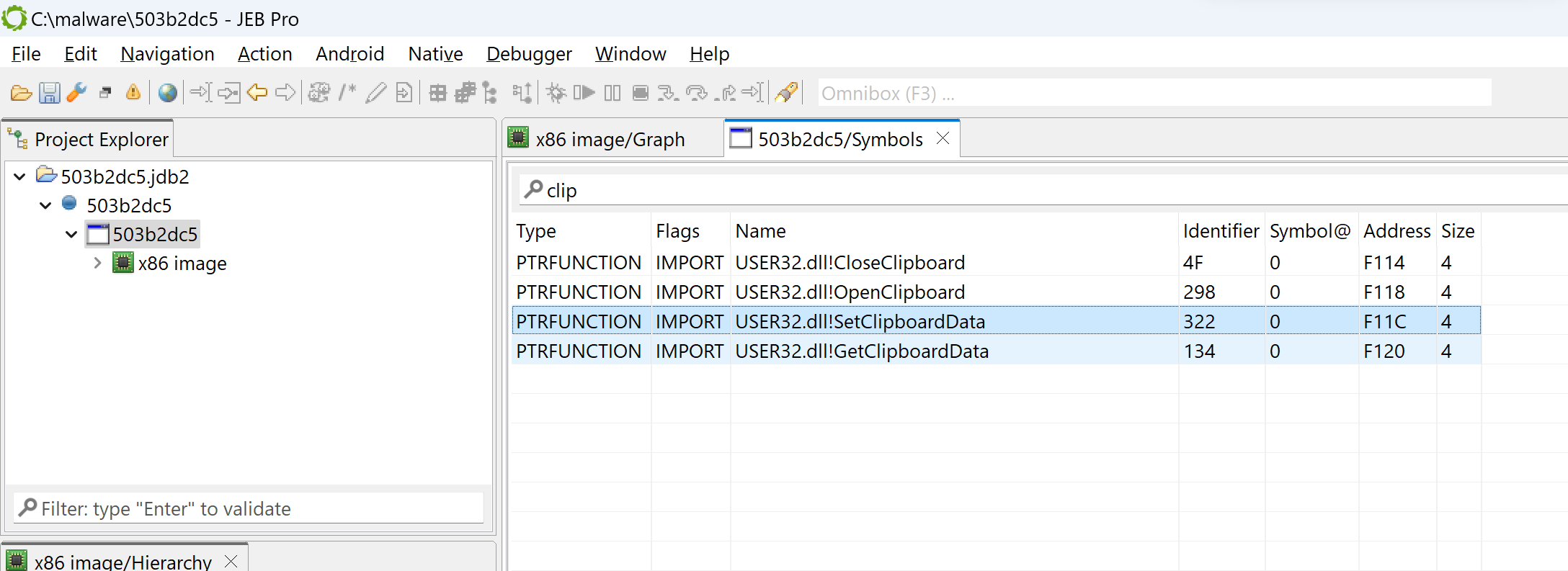
The Symbols tab lists all symbols advertised by the PE, including imported and exported routines. For example, if you filter on “clip”, you can see multiple win32 routines relating to clipboard access, such as OpenClipboard or SetClipboardData:
The Symbols fragment of the winpe unit view, with a filter applied (“clip”)
Examining the code
Let’s go back to the disassembly offered by the x86 unit. First, notice that the code hierarchy view does not seem to contain well-known methods (static code), typically standard library routines linked at compile-time.
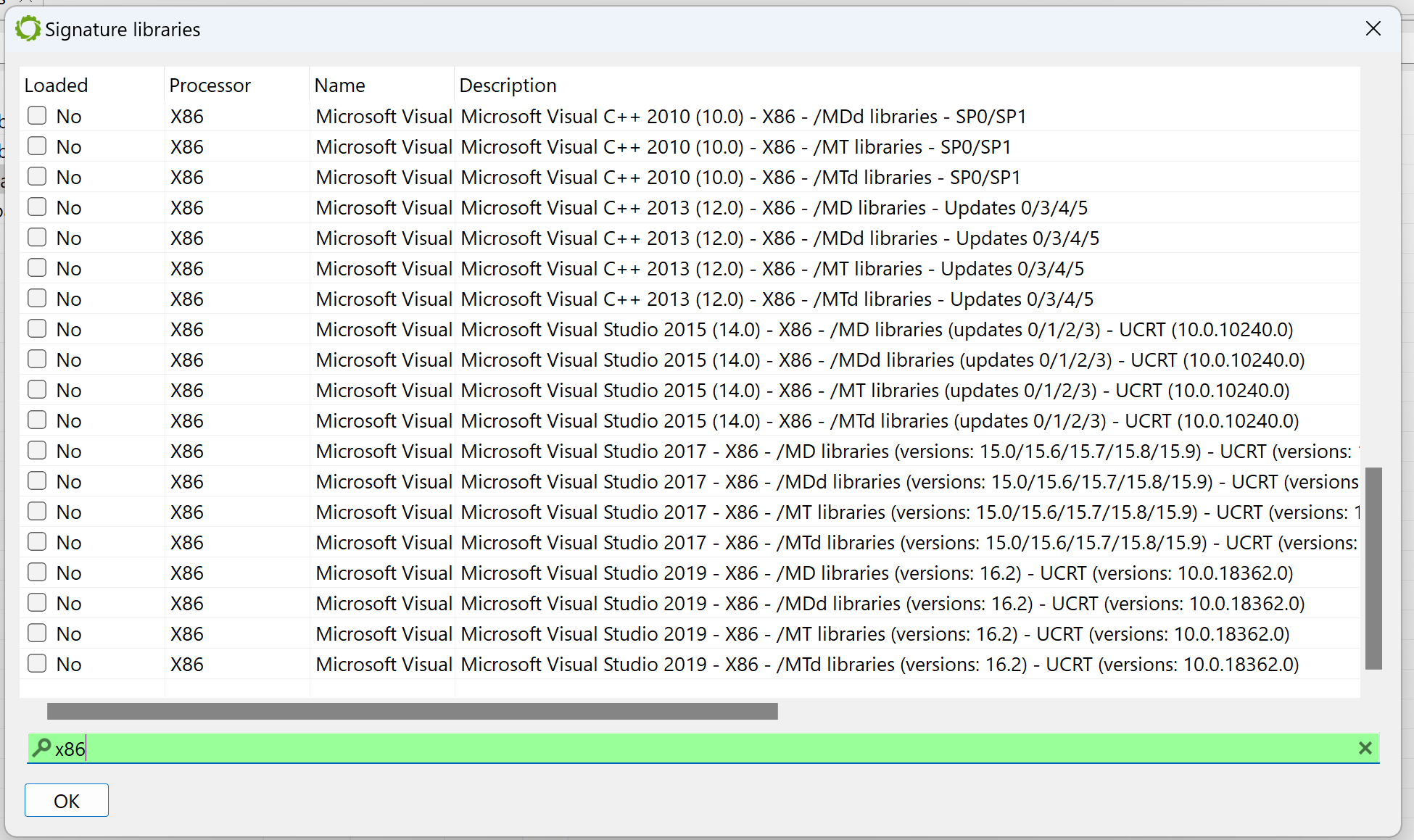
Let’s see why by looking at which siglibs (signature libraries) were applied during the initial analysis (menu: Native, Signature Libraries…). It looks like none were loaded:
The Signatures Libraries dialog
Library code identification
Normally, when JEB performs the initial auto-analysis of the code, compiler identification is used to determine whether well-known signature libraries of static code (siglibs) should be loaded and applied to the binary. In this case, compiler identification failed because all header data had been discarded. JEB decided to not load and apply signatures.
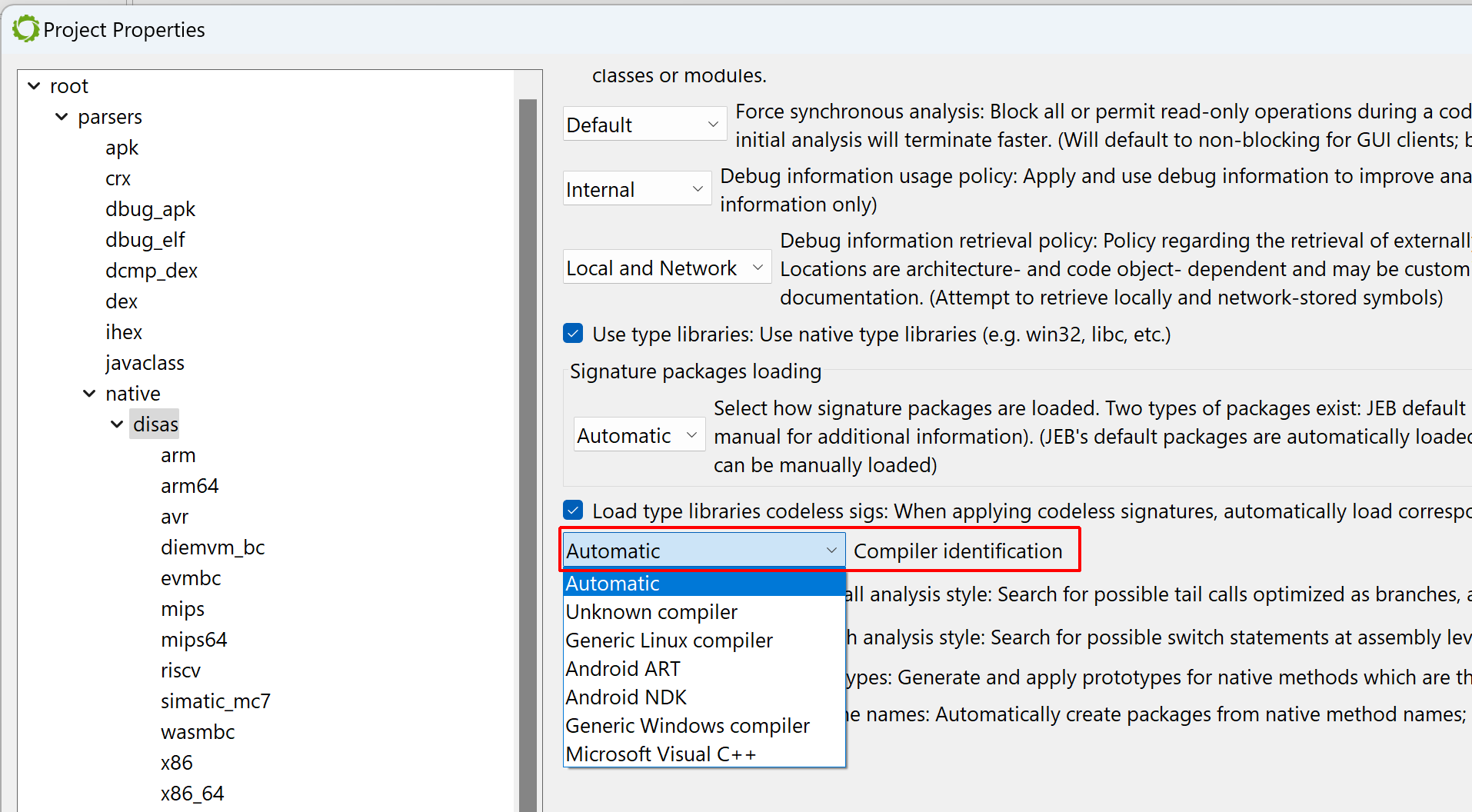
To apply them manually, tick the “MSVC x86” boxes. (An alternative is to let JEB know that the file was compiled with MSVC before the analysis starts: when opening the artifact, when the Options panel is displayed, the user may decide to force the compiler to a set-value.)
Forcing a compiler setting before the initial analysis
After doing either of the above ((a) file re-analysis with a compiler identification pre-set; or (b) manual siglibs application), several methods are identified as MSVC code:
Light-blue areas mean the code was matched against well-known signatures
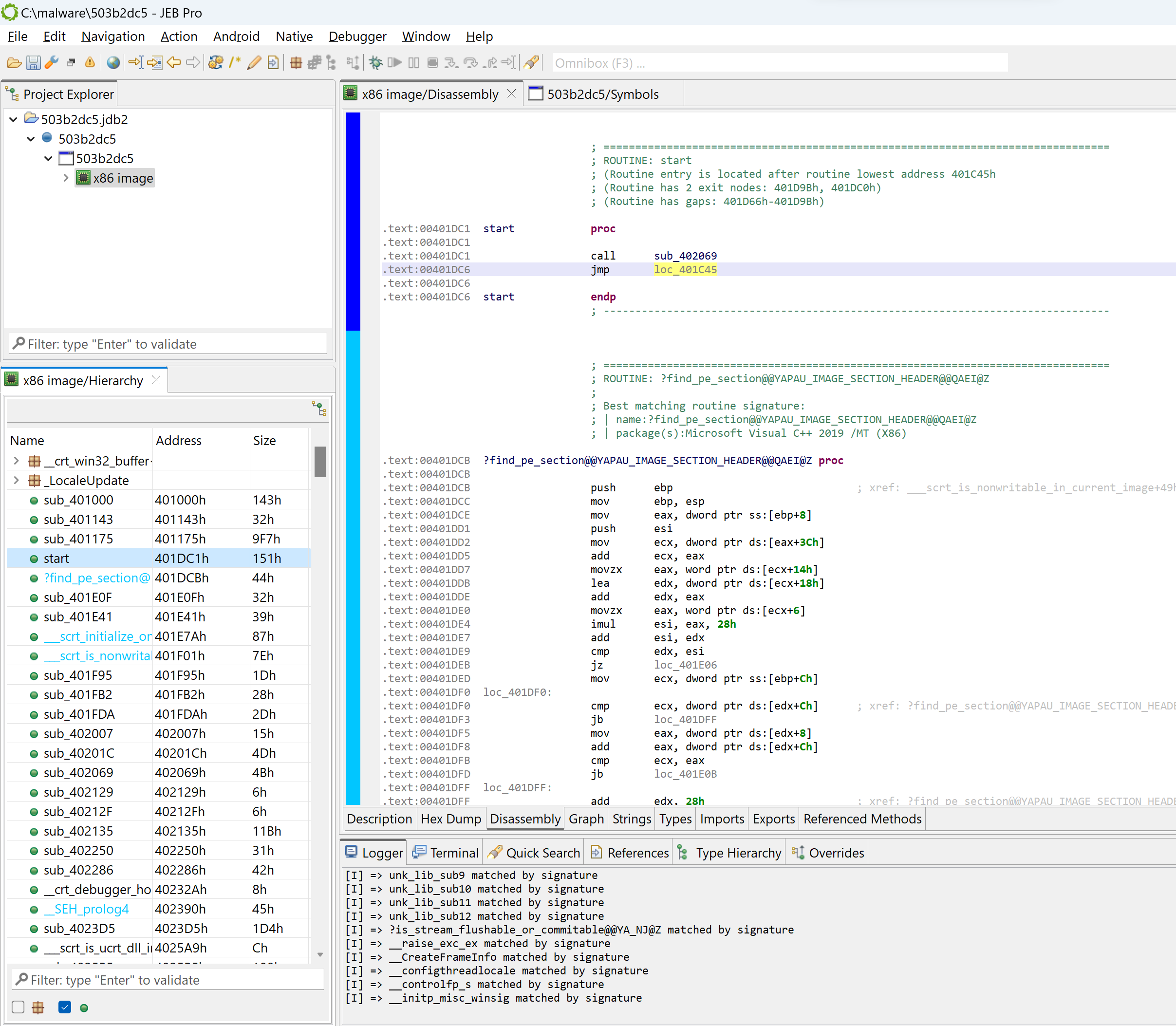
Entry-point and WinMain
Navigate to the executable entry-point (menu: Native, Go to entry-point…).
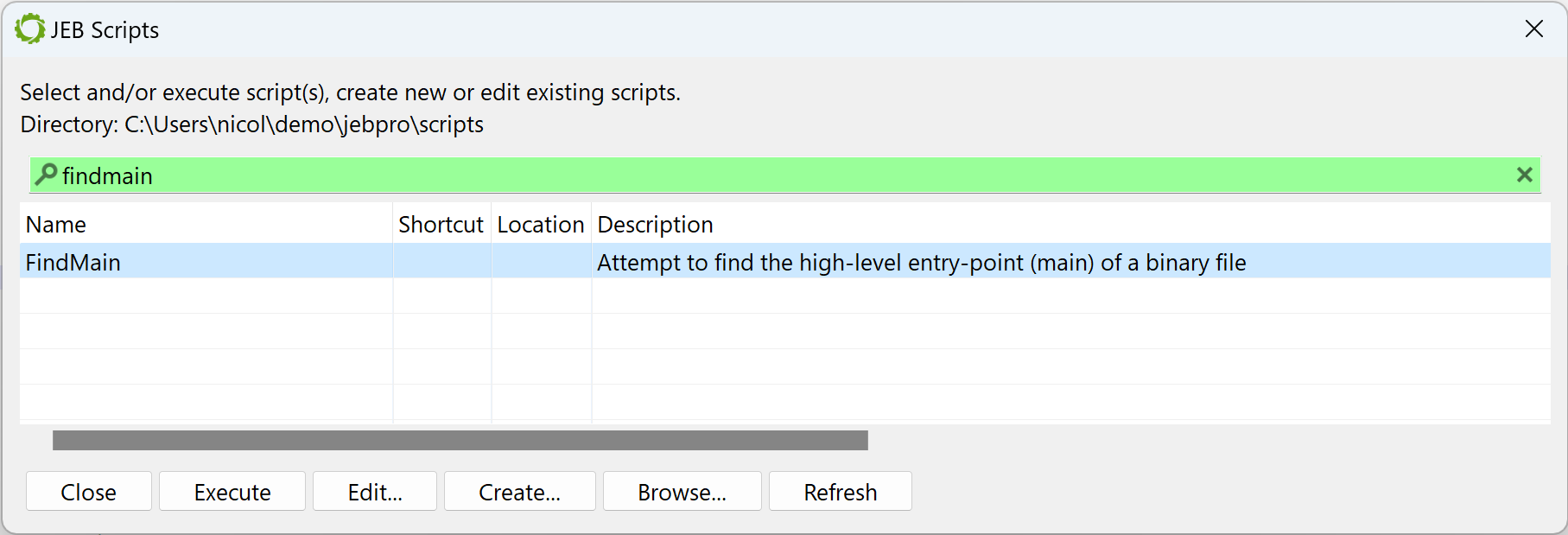
In the general case, the entry-point of a Windows PE compiled with MSVC is not the high-level entry-point that will contain meaningful code. Although it is relatively easy to find WinMain with a bit of experience, there is a JEB script to help you as well, FindMain.py (available in the samples-script folder, also available on GitHub). Open up the script selector with F2 (menu: File, Scripts, Script selector…).
Run a JEB Python script inside the GUI client
Select the desired script and execute it. The result is displayed in the console:
...
Found high-level entry-point at 0x401175 (branched from 0x401D38)
Renaming entry-point to 'winmain'
...
The code at 0x401175 was auto-renamed to winmain (menu: Action, Rename…).
Initial decompilation
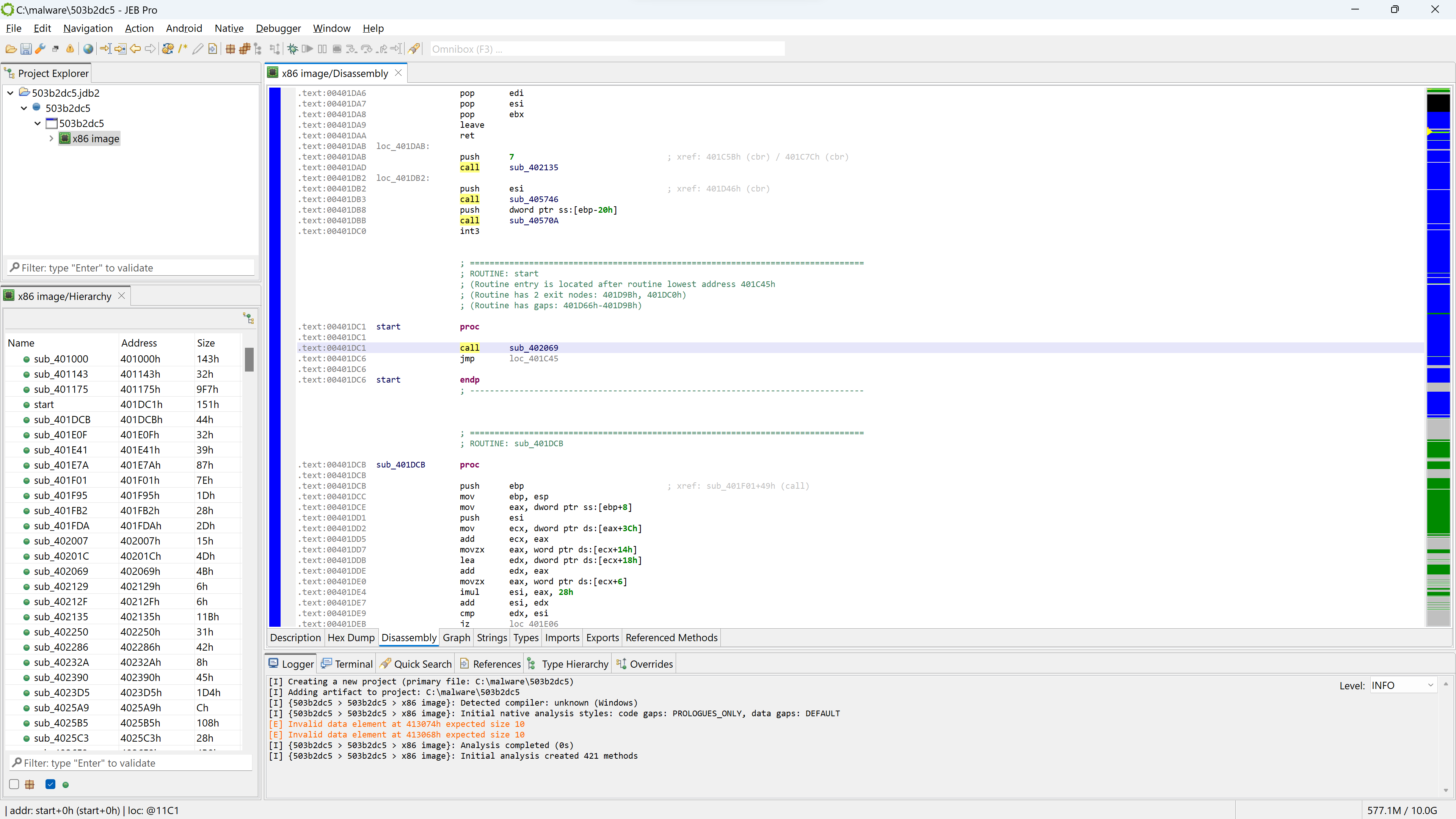
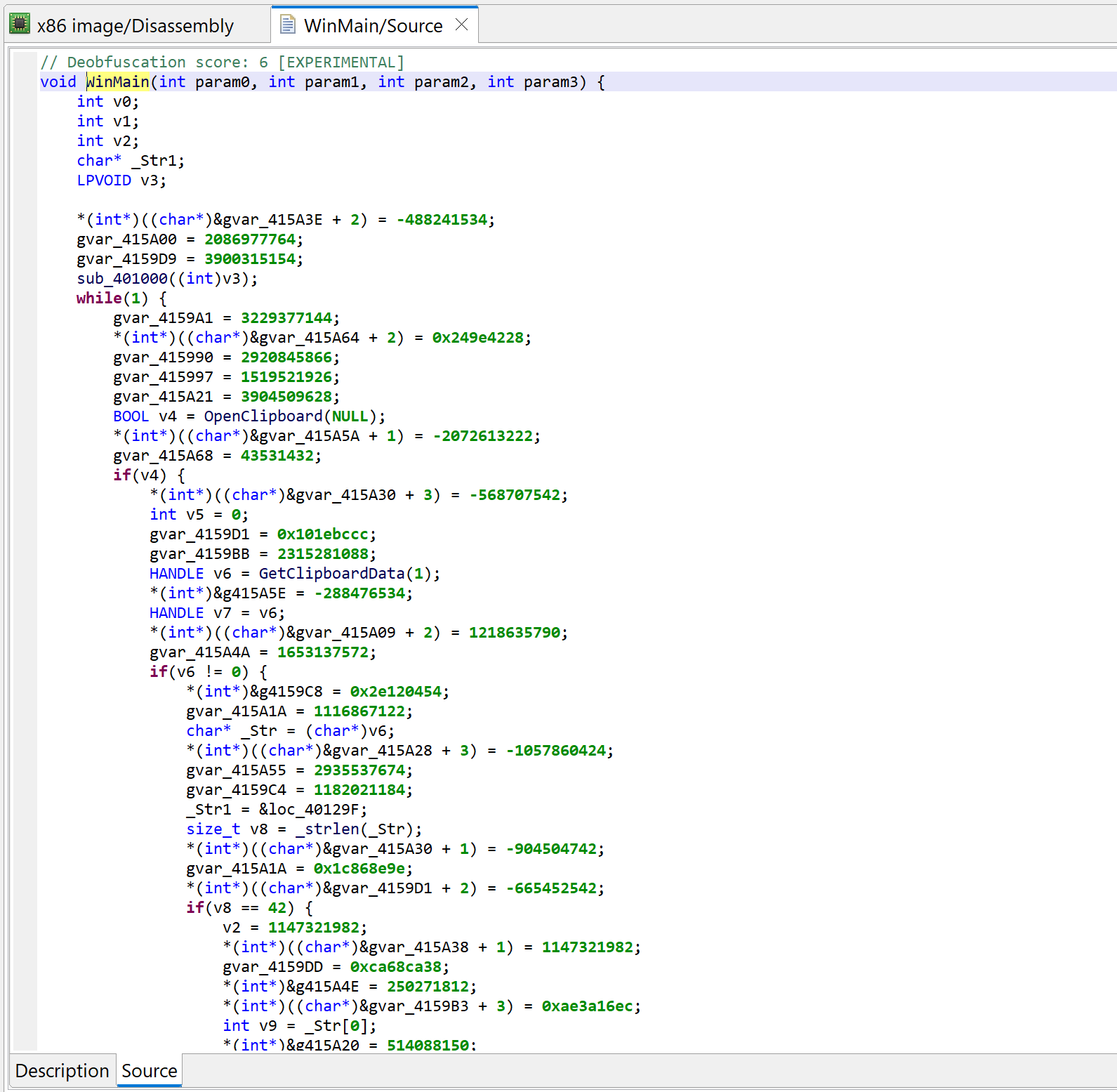
Let’s decompile that method by pressing the TAB key (menu: Action, Decompile…).
Initial decompilation of WinMain
Two items of interest to note at this point:
There is lots of code that appears to be junk or garbage
There is a note about some “deobfuscation score”
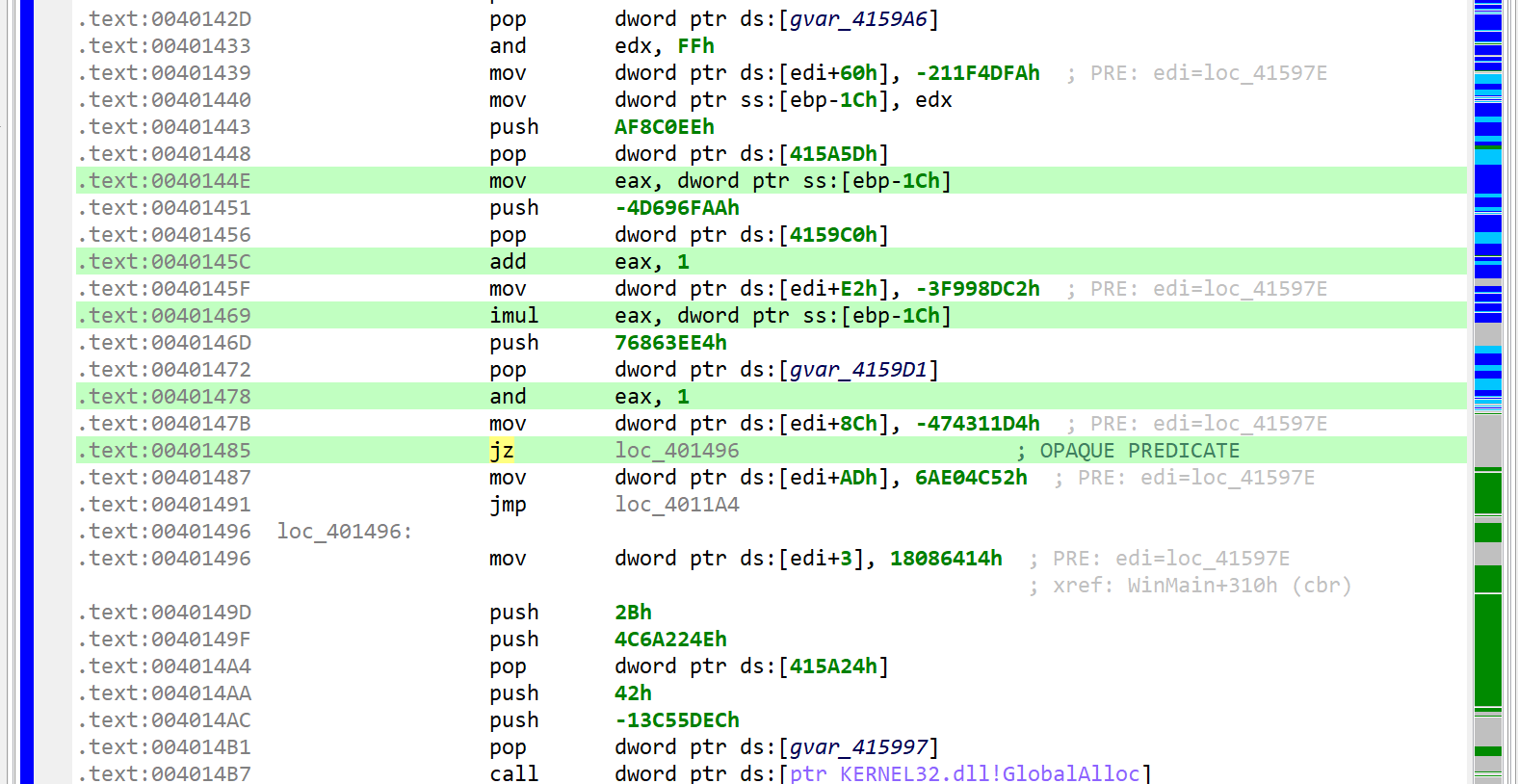
Junk code
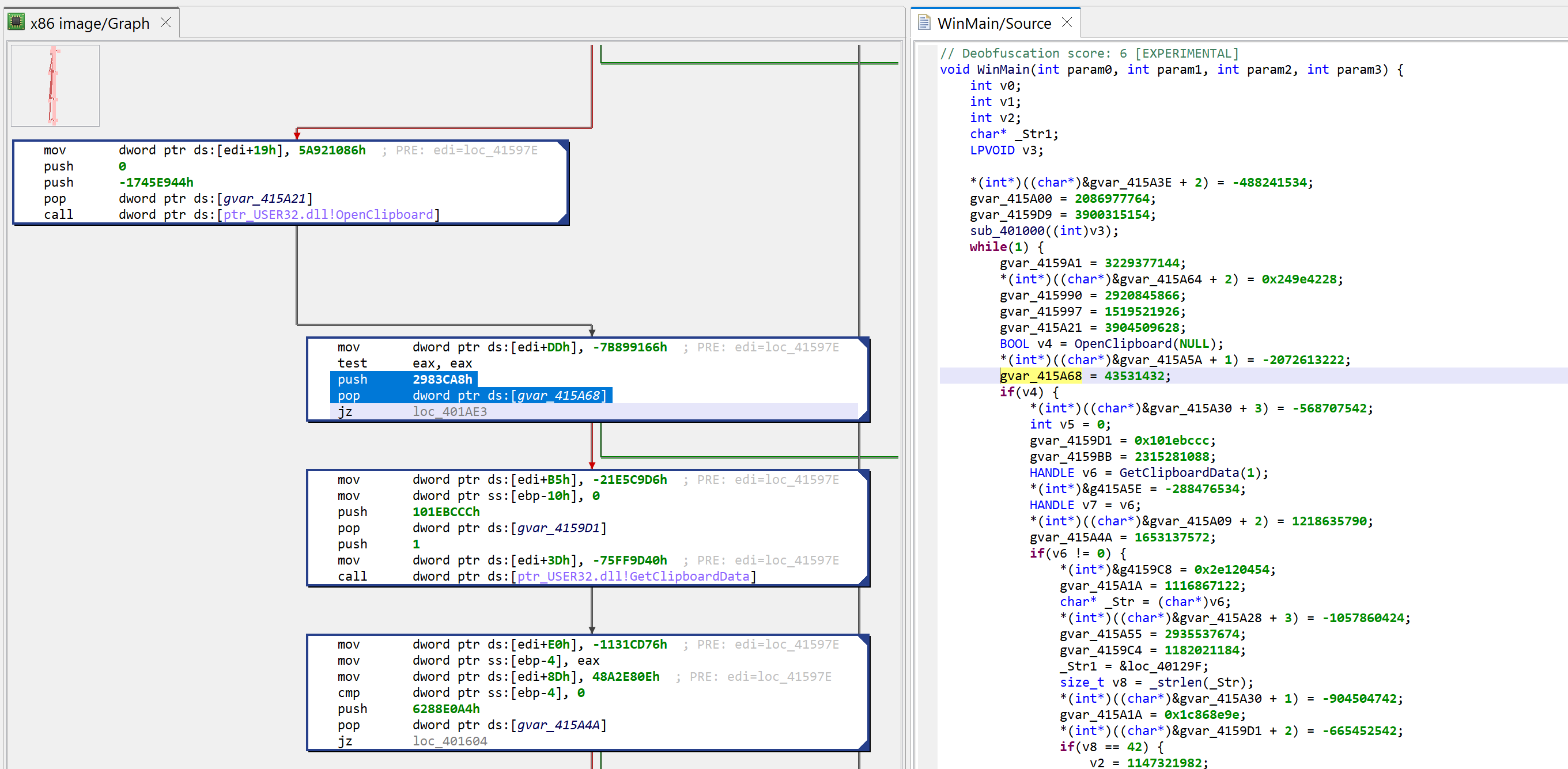
The decompiled WinMain method is about 300 lines of C code. A lot of it are assignments writing to program globals. At first glance, it looks like it could be some sort of obfuscation. Let’s look at the corresponding assembly code:
Press TAB to go back from a decompilation to the closest matching machine code disassembly line
The snippets have the following structure: push GARBAGE / pop dword [gXXX]
Or that, assuming edi is callee-saved: mov edi, gXXX / ... / mov dword [edi+offset], GARBABE
Later on, we will see how to remove this clutter to make the analysis more pleasant.
Deobfuscation score
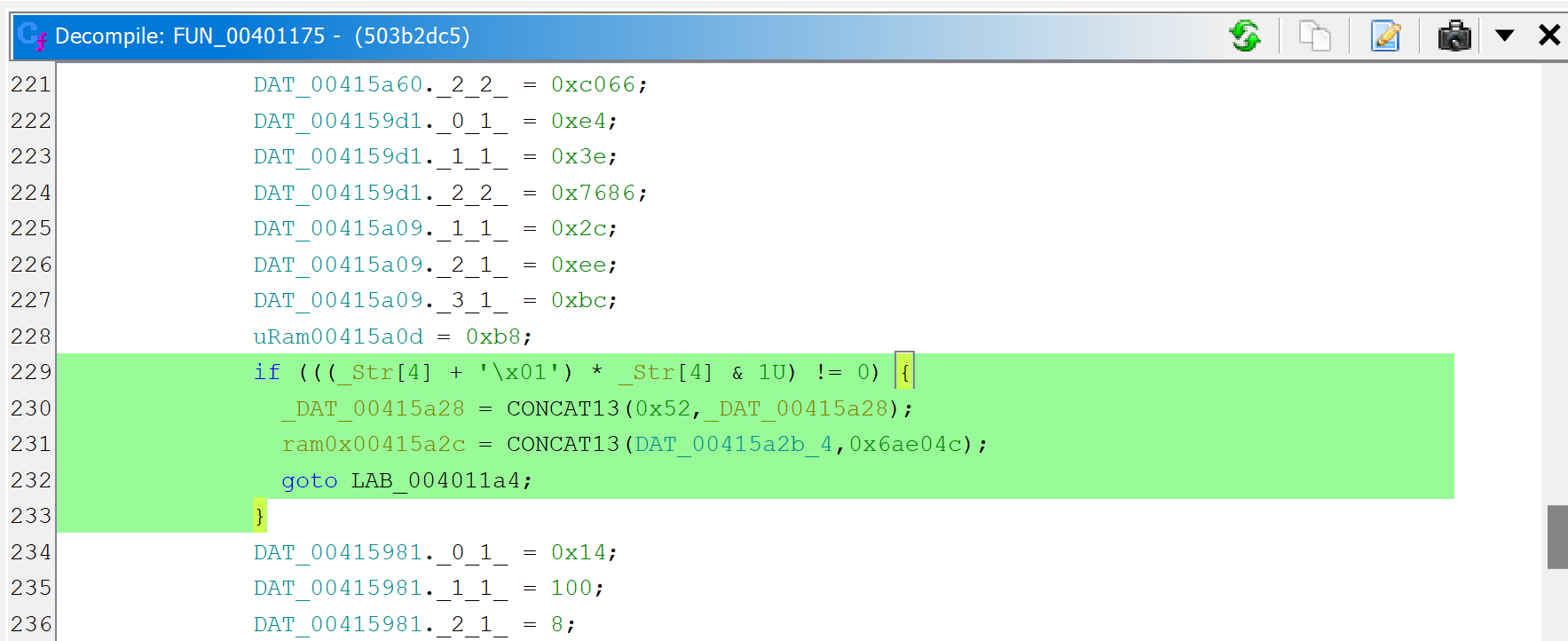
A note “deobfuscation score: 6” was inserted as a method comment. That score indicates that some “advanced” clean-up was performed. In this case, a careful examination (as well as a comparison against a decompilation with UNSAFE optimizers turned off, which you can do by redecompiling the method with CTRL+TAB (menu: Action, Decompile with Options…)) will point to this area of code:
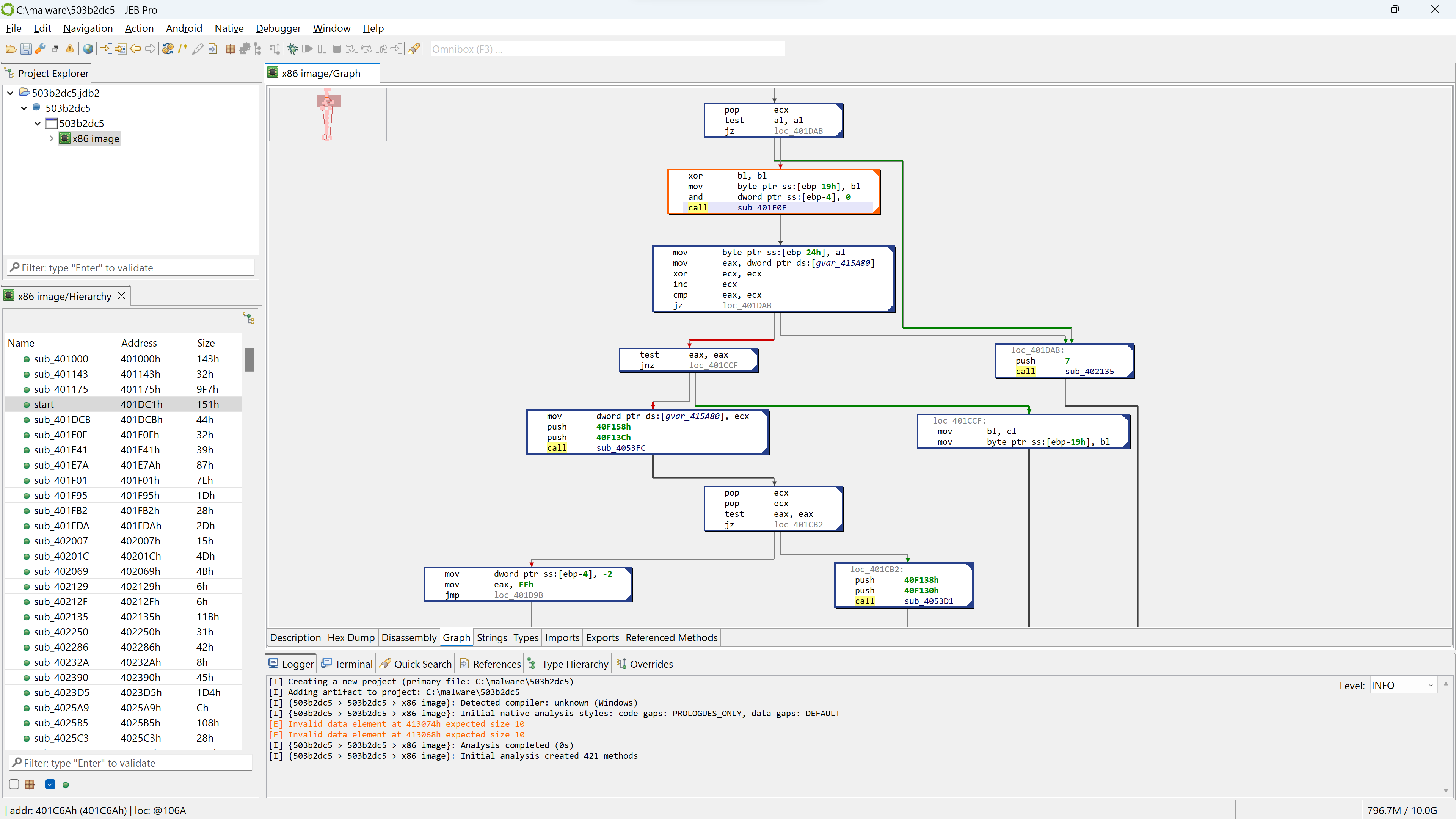
The opaque predicate calculation is highlighted in green using CTRL+M (menu: Action, Toggle Highlight…)
This predicate looks like the following: if(X*(X+1) % 2 == 0) goto LABEL.
With X being an integer, X*(X+1) is always even. Therefore, the predicate will always evaluate to true. JEB cleaned this up automatically. (While this particular predicate is trivial, truly opaque predicates will also be attempted to be broken up by JEB, using the Z3 SMT solver.)
Comparison with GHIDRA
For a point of comparison, you may have a look at the same method decompiled by GHIDRA 10.4 here (default settings were used, just like we did with JEB). The predicate is not cleaned-up adequately, extra control-flow edges are left over, leading to AST structuring confusion.
Cleaning up the code
Let’s start with decluttering this code. First of all, why couldn’t the decompiler clean it up on its own? If the globals written to are never read with meaningful intent, then they could be discarded.
The issue is that this is very hard to ensure in the general case. However, in specific cases, sometimes involving manual review, some global written-to memory range may be deemed useless, as it is the case here. How do we provide this information to the decompiler? Well, as of version 5.7, we cannot! 1 What we can do though is write a decompiler plugin to clean-up the offending IR, and in the process, generate clean(er) code.
IR cleaner plugin
The decompiler accept several types of plugins, including IR Optimizers (they work on the Intermediate Representation of a routine, as it moves up the decompilation pipeline), and AST optimizers (to clean-up or reformat the generated abstract syntax tree of the pseudo-code). In most cases, IR optimizers are well-suited to perform code clean-up or deobfuscation tasks (refer to this blog post for a detailed comparison).
We will write the plugin in Java (we could also write it in Python). It will do the following:
Examine each IR statement of a CFG
Check if the statement is writing an immediate to some global array: *(array + offset) = value
If so, check the array name. If it starts with the prefix “garbage”, consider the statement useless and replace it by a Nop statement
Writing IR plugins is out-of-scope in this post; we will go over that in details in a future entry. In the meantime, you can download the plugin code here. Dump the Java file in your JEB’s coreplugins/scripts/ folder. There is no need to close and re-open JEB; it will be picked up at the next decompilation.
public class GarbageCleaner extends AbstractEOptimizer {
@Override
public int perform() {
int cnt = 0;
for (BasicBlock<IEStatement> b : cfg) {
for (int i = 0; i < b.size(); i++) {
IEStatement stm = b.get(i);
if (stm instanceof IEAssign && stm.asAssign().getDstOperand() instanceof IEMem
&& stm.asAssign().getSrcOperand() instanceof IEImm) {
IEMem dst = stm.asAssign().getDstOperand().asMem();
IEGeneric e = dst.getReference();
// [xxx + offset] = immediate
if (e.isOperation(OperationType.ADD)) {
IEOperation op = e.asOperation();
if (op.getOperand1().isVar() && op.getOperand2().isImm()) {
IEVar v = op.getOperand1().asVar();
IEImm off = op.getOperand2().asImm();
if (v.isGlobalReference()) {
long addr = v.getAddress();
INativeContinuousItem item = ectx.getNativeContext().getNativeItemAt(addr);
// logger.info("FOUND ITEM %s", item.getName());
if (item != null && item.getName().startsWith("garbage")) {
long itemsize = item.getMemorySize();
if (off.canReadAsLong() && off.getValueAsLong() + dst.getBitsize() / 8 < itemsize) {
logger.info("FOUND GARBAGE CODE");
b.set(i, ectx.createNop(stm));
cnt++;
}
}
}
}
}
}
}
}
if (cnt > 0) {
cfg.invalidateDataFlowAnalysis();
}
return cnt;
}
}
Note that by design, the plugin is not specific to this malware. We will be able to re-use it in future analyses: all global arrays prefixed with “garbage” will be treated by the decompiler as junk recipients, and cleaned-up accordingly!
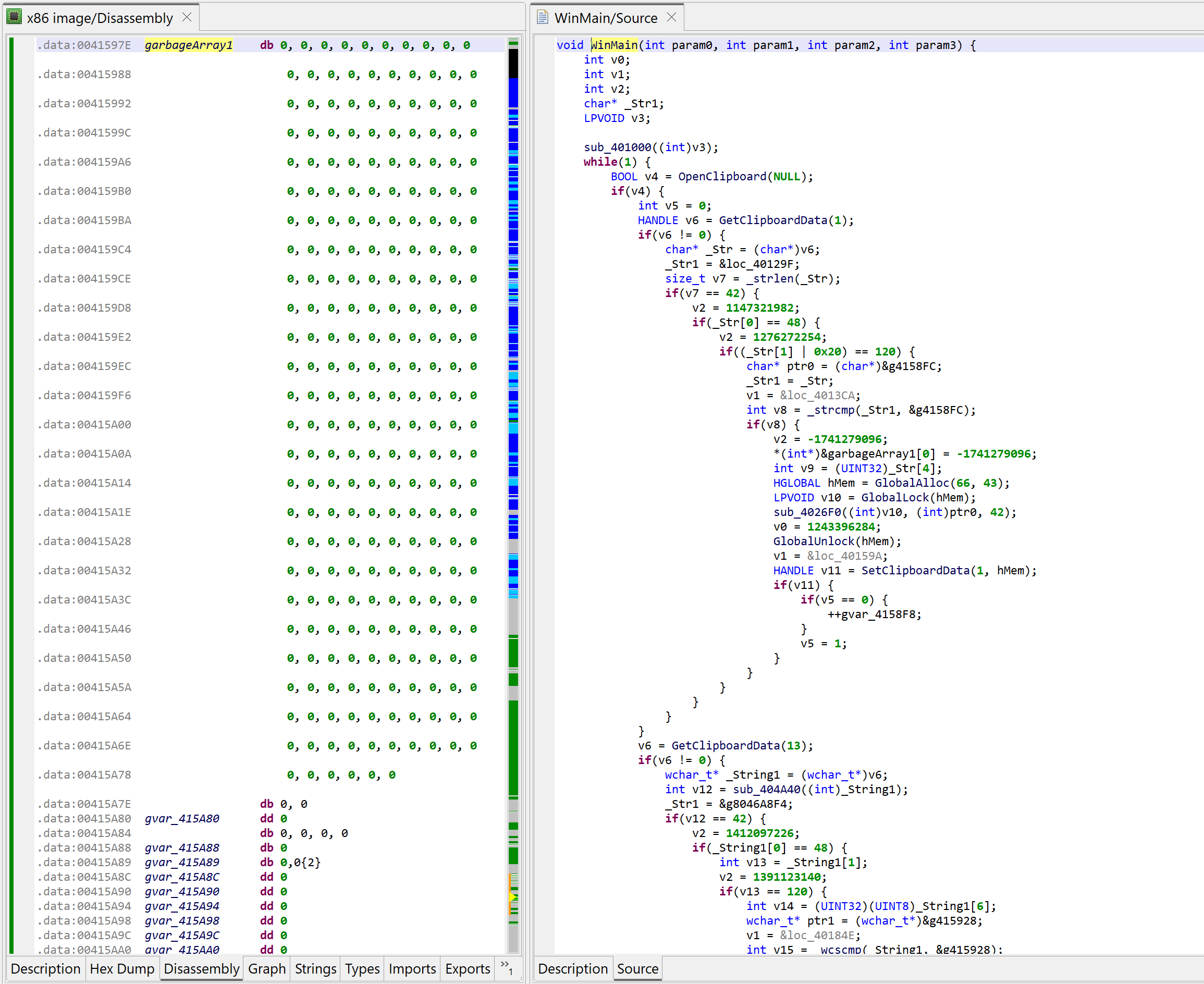
Defining the garbage array
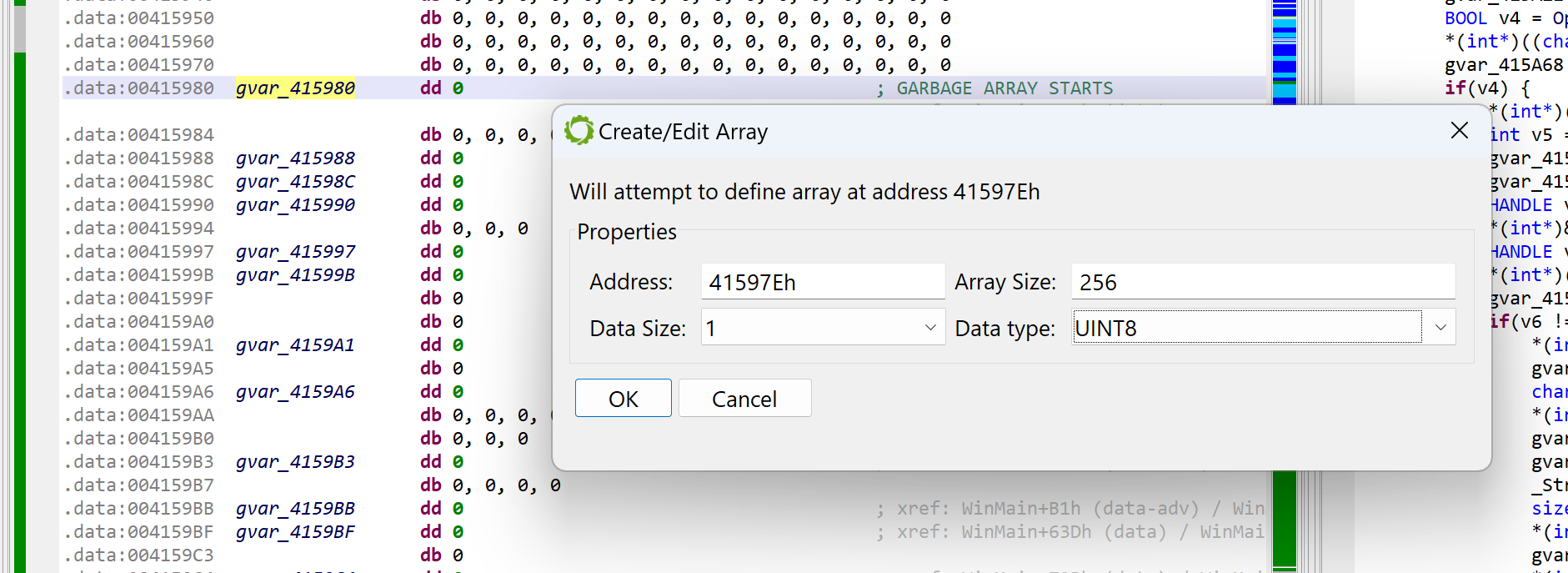
At this point, we need to determine where that array is. Some examination of the code leads to the following boundaries (roughly): start at 0x41597E, spans over 0x100 bytes. Navigate to the disassembly; create an array using the STAR key (menu: Native, Create/Edit Array…); specify its characteristics.
Creating a global array of 0x100 bytes. This is the garbage array.
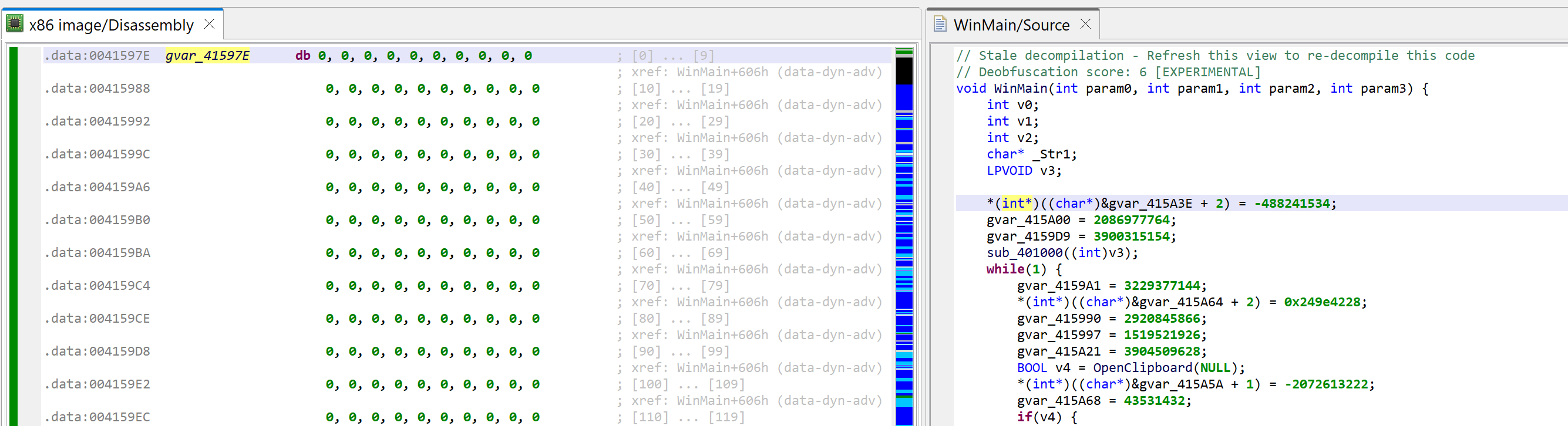
As soon as the array is created, the disassembly will change to what can be seen below. At the same time, the decompilations using that array will be invalidated; that is the case for WinMain. You may see that another extra-comment was added by the decompiler: “Stale decompilation – Refresh this view to re-decompile this code”. Such decompilations are read-only until a new one is generated.
The array is now created. The decompilation of WinMain becomes stale.
Before redecompiling, remember we need to rename our array with a label starting with “garbage”. Set the caret on the array, hit the key N (menu: Actions, Rename…) and set your new name, e.g., garbageArray1.
Now you may go back to the decompilation view of WinMain and hit F5 (menu: Windows, Refresh…) to regenerate a decompilation.
Decompiled WinMain after the garbage array-assigns were cleaned-up by the plugin
The code above is much nicer to look at – and much easier to work on!
Quick analysis
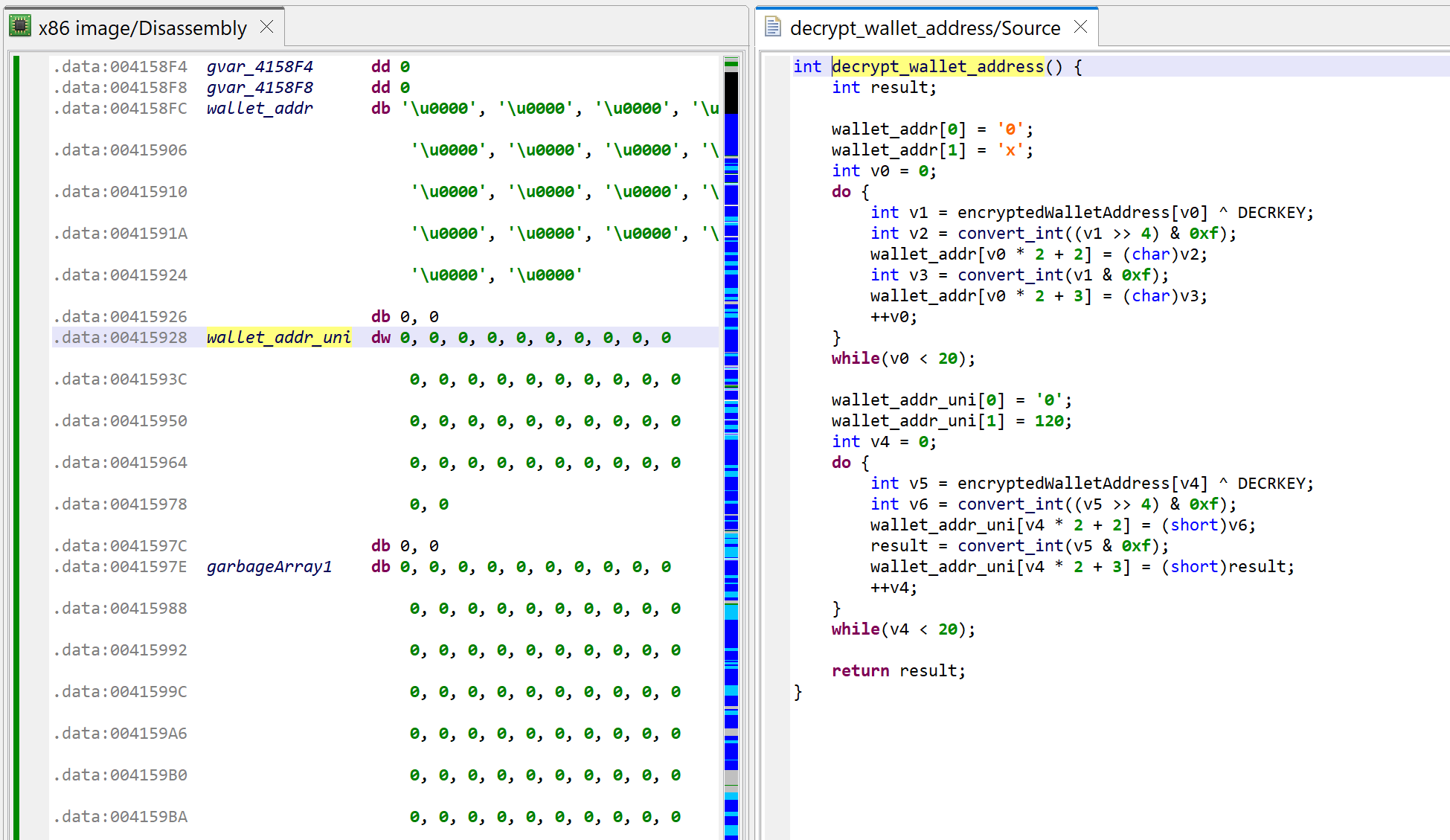
The method at 0x401000, called by WinMain, is decrypting the thief’s wallet address, and generating two hexstring versions of it (ascii and unicode).
Decrypting the target wallet address. The decompilation is shown after proper types were applied on the data structures accessed (encrypted wallet address, hexstrings, etc.) and better names given to those vars
The loop in WinMain is doing the following:
Every second, it queries the Windows clipboard with OpenClipboard
It checks if it contains text strings or unicode strings
If the string is 42 characters in length and starts with “0x”, it proceeds (an Ethereum wallet address is 20 bytes, therefore its hexadecimal representation would be 40 characters)
It checks if the string is not the attacker’s wallet address
If not, it replaces the contents of the clipboard data by the attacker’s wallet address using SetClipboardData
Finally, the other contents found in the clipboard is discarded
Well-known literals
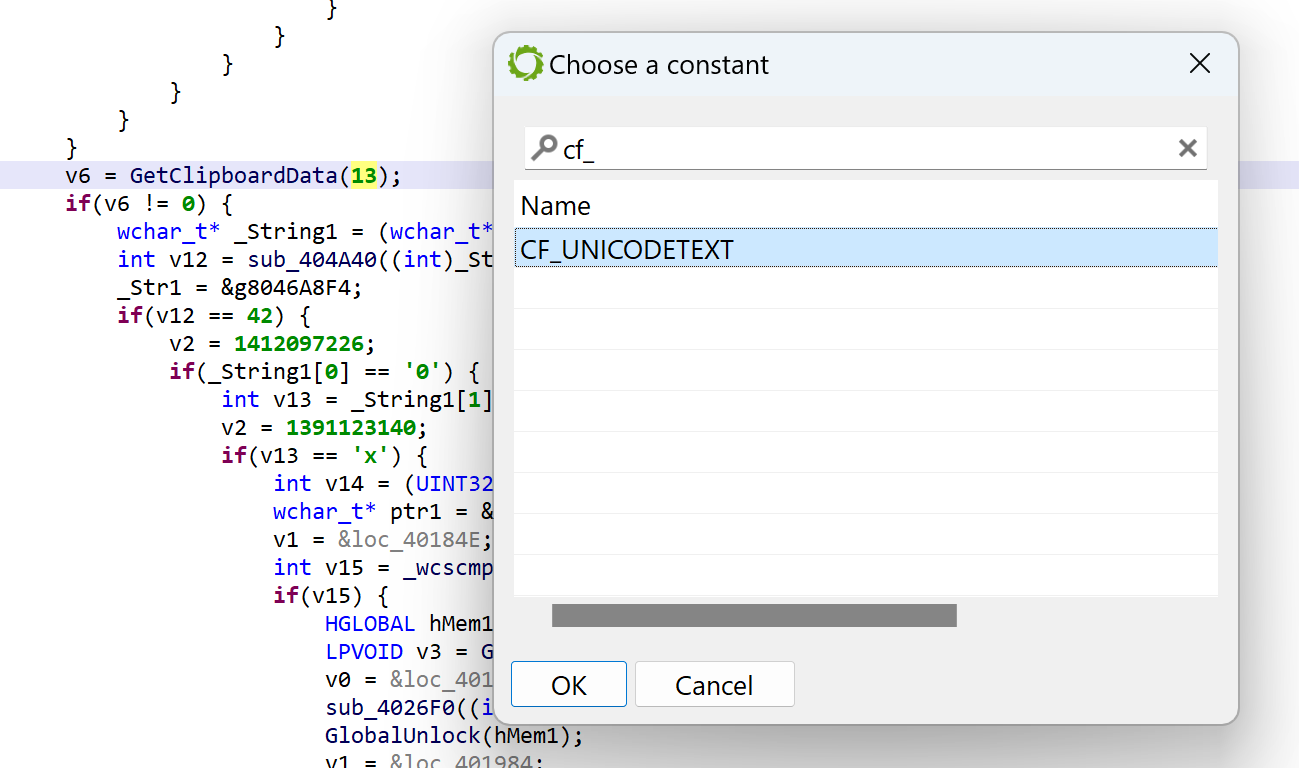
In JEB, you may replace immediates by well-known literals found in type libraries (aka typelibs, such as the win32 typelibs, which were automatically loaded when the analysis of the PE file started). To do that, select the immediate, then hit CTRL+N (menu: Action, Replace…), and select the desired literal 2
For example, per the MSDN, GetClipboardData uses CF_xxx constants to indicate the type of data. We can ask JEB to replace GetClipboardData(13) by GetClipboardData(CF_UNICODETEXT) using the Action/Replace handler:
Replacing 13 by CF_UNICODE in a call to GetClipboardData
Conclusion
That concludes the first blog in this “How to use JEB” series. In the next episodes, we will look at other features, dig deeper into writing IR plugins, look into types and types creation, and reverse other architectures, including exotic code.
To learn more, we encourage you to:
Explore this blog, as it contains many technical entries and how-to’s.
Look at the sample code (scripts and plugins) shipping with JEB, it will get you started on using the API to write your own extensions.
Join our Slack channel to engage with other users in the community and ask questions if you’re stuck on anything.
Thank you very much & Stay tuned 🙂 Happy Holiday to All 🎄
–
The plugin written to analyze this malware may ship in some upcoming version of JEB. ↩
In many cases, JEB will do that automatically, and it should be the case here. ↩
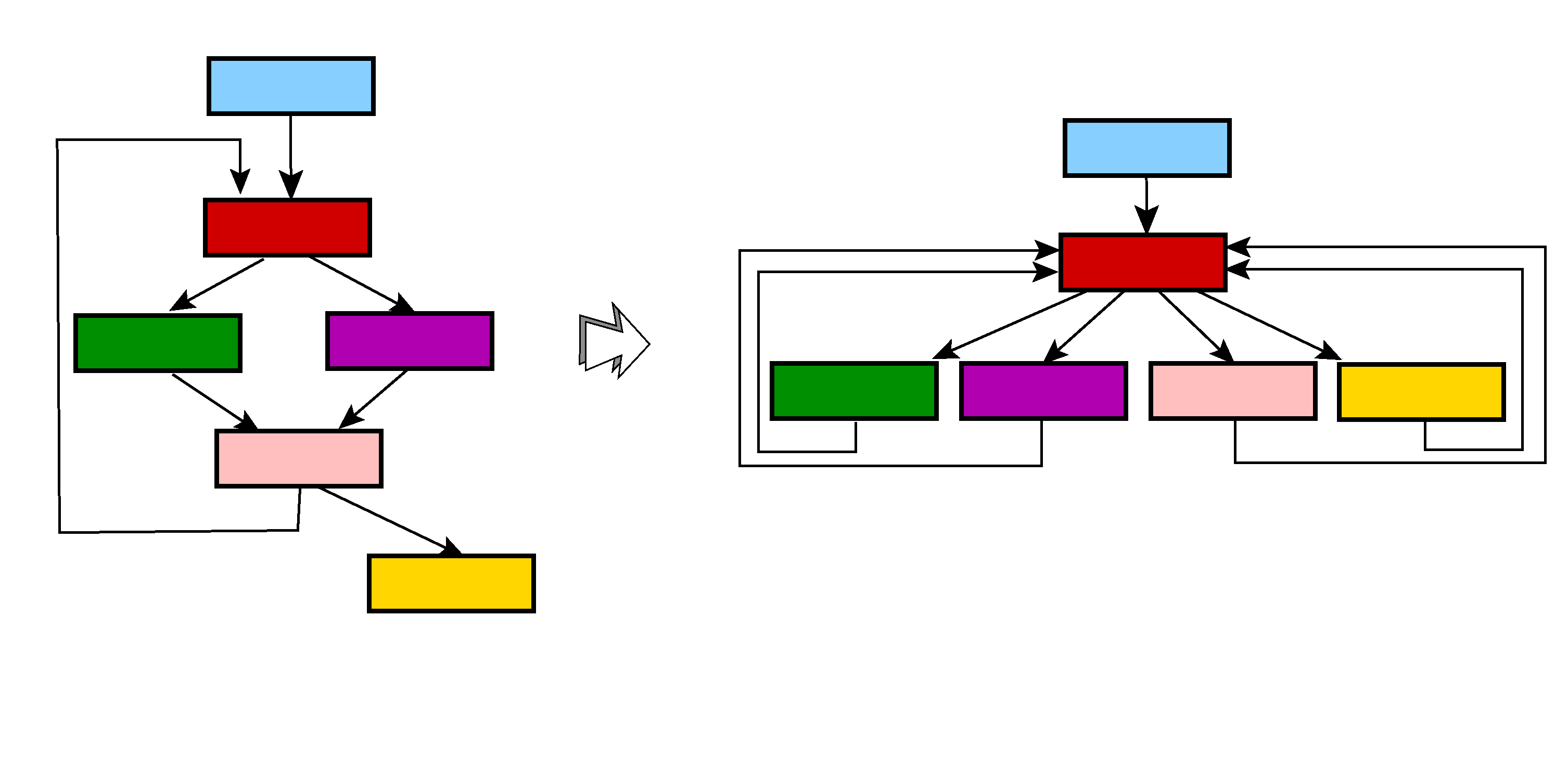
Control-flow flattening, sometimes referred to as chenxification2, is an obfuscation technique employed to destructure a routine control-flow. While a compiled routine is typically composed of a number of basic blocks having low ingress and egress counts, a flattened routine may exhibit an outlier node having high input and high output edge counts, and generally, a very high centrality in the graph (in terms of vertex betweenness). Practically speaking, the original method M is reduced to a many-way conditional block H evaluating an expression VPC, dispatching the flow of execution to units of code, each one performing a part of M, updating VPC, and looping back to H. In effect, the original structured code is reduced to a large switch-like block, whose execution is guided by a synthetic variable VPC. Therefore, the original flow of control, critical to infer meaning while performing manual reverse-engineering, is lost. 3
We upgraded dexdec‘s control flow unflattener earlier this year. 4 The v2 of the unflattener is more generic than our original implementation. It is able to cover cases in which the obfuscated does not map to the clean model presented above, e.g. cases where the dispatcher stands out.
This week, we encountered an instance of code that was auto-deobfuscated to clean code and thought it’d be a good example to show how useful generic deobfuscation of such code can be. It seems that the obfuscator that was used to protect the original code was BlackObfuscator, a project used by clean apps and malware alike.
If you encounter examples where the unflattener does not perform adequately, please let us know. We’ll see if they can be fixed or upgraded to cover obfuscation corner-cases.
Thank you & until next time — Nicolas.
—
dexdec is JEB’ dex/dalvik decompiler, gendec is JEB’s generic decompiler used for native code and any code other than dex/dalvik ↩
A term coined by University of Arizona’s Pr. Christian Collberg for the fact that an early description of this technique was presented by Dr. Chenxi Wang in her PhD thesis ↩
Control-flow flattening can be seen as a particular case of code virtualization, which was covered in previous blog entries. ↩
This is part 2 of the blog that introduced the major addition that shipped with JEB Pro 4.29: the ability for the dex decompiler to call into the native analysis pipeline, the generic decompiler and native code emulator.
Today, we demo how to use two plugins shipping with JEB 4.30, making use of the emulators to recover information protected by a native code library found in several APKs, libpairipcore.so.
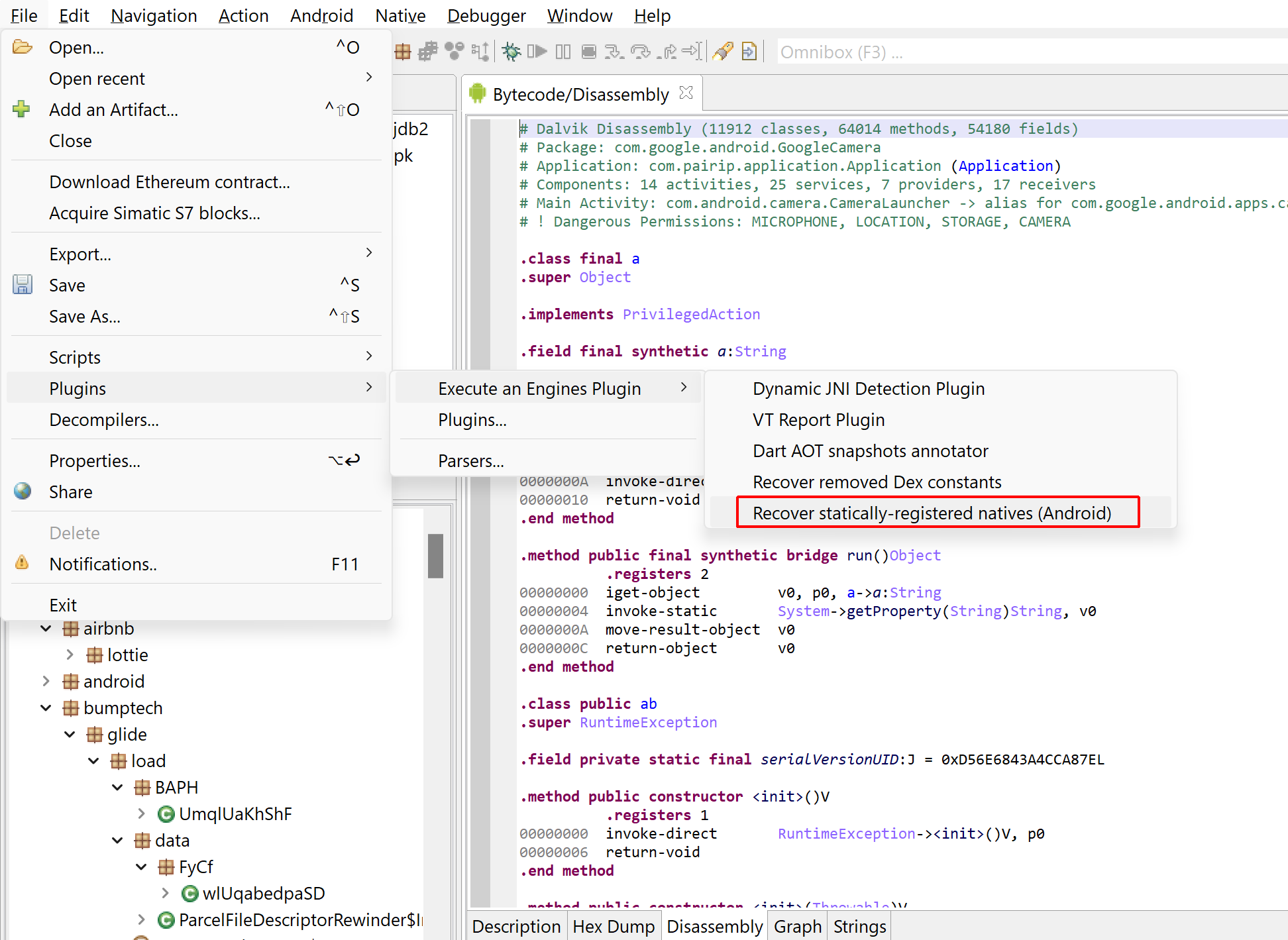
Recovering statically registered native routines
The first plugin can be used to discover native routines registered via JNI’s RegisterNatives. As a reminder, when calling a native method from Java, the JNI will see if exported routines with specific names derived from the Java method signature exist in the process. Alternatively, bindings between a Java native method and its actual body can be done with RegisterNatives. Typically, this is achieved in JNI_OnLoad, the primary entry-point. However, it does not need to; other techniques exist to further obfuscate the target call site of a Java native method, such as unregistration/re-registration, the obfuscation of JNI_OnLoad, etc. More information can be found here.
In its current state, the plugin will attempt to emulate a SO library’s JNI_OnLoad on its own, without the context of the app process it would normally run on. The advantage is that the plugin is useable on libraries recovered without their container app (APK or else). The drawback is that it may fail in complex cases, since the full app context is not available to this plugin. (Note that the second plugin does not suffer this limitation).
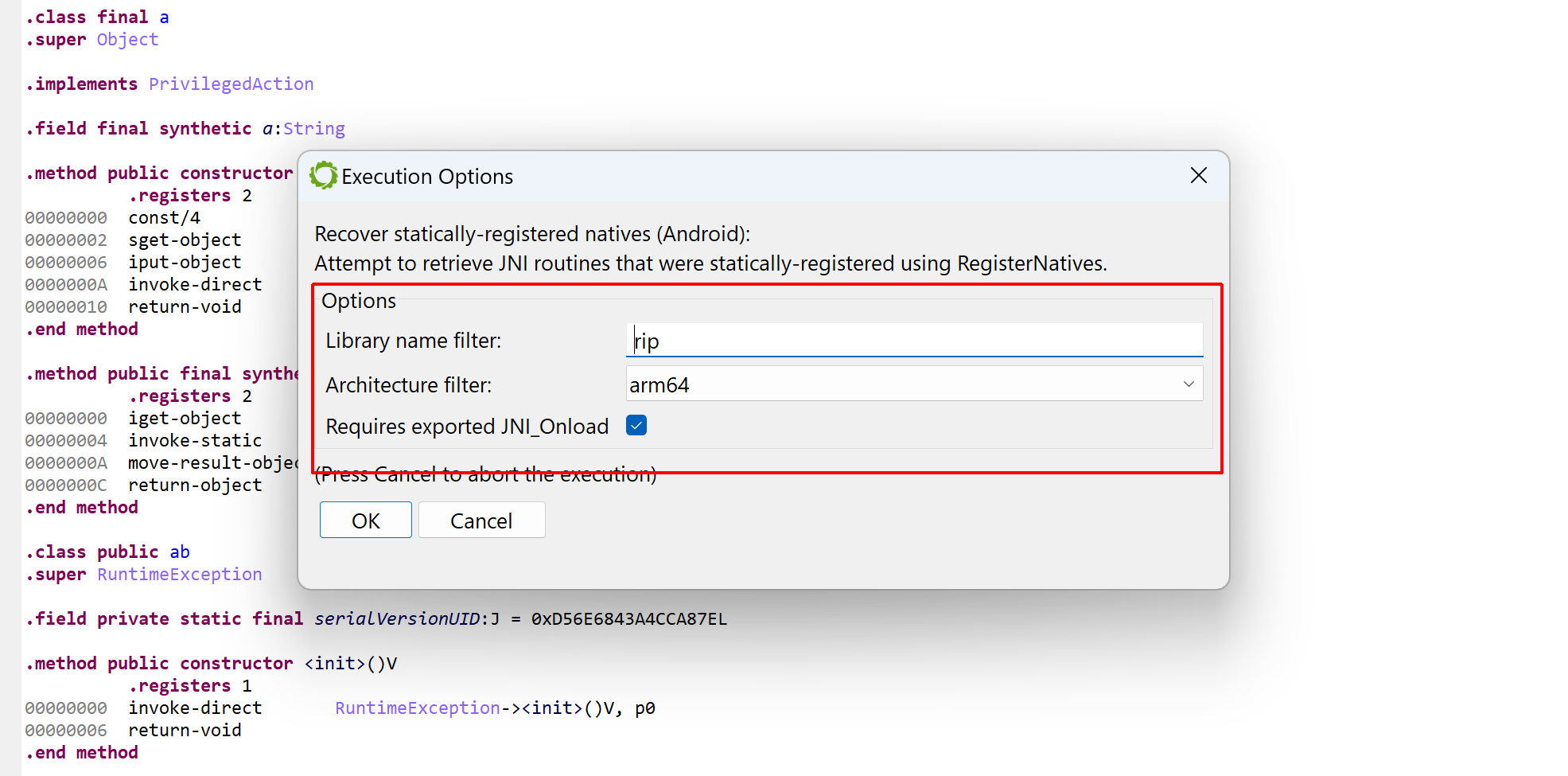
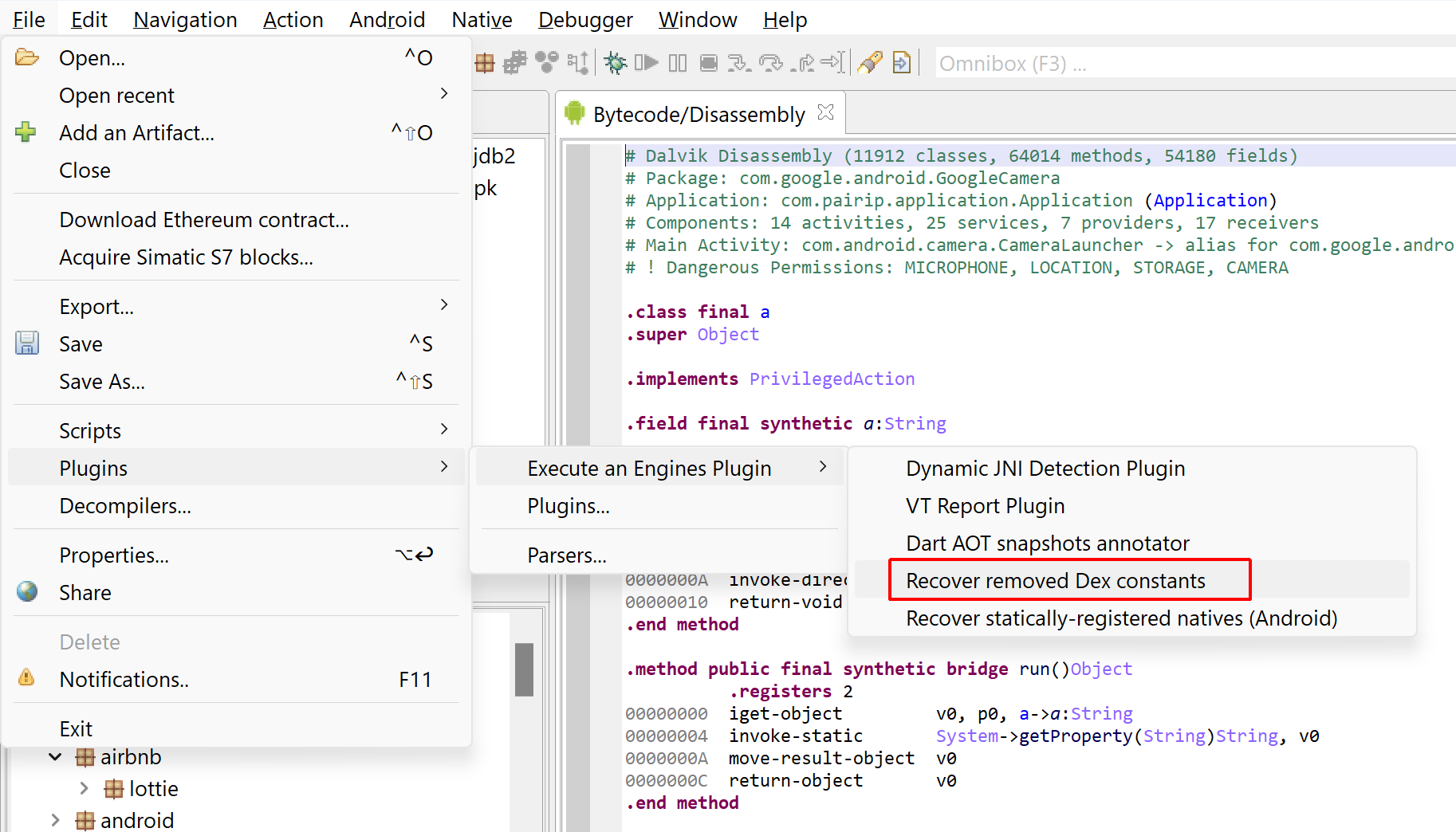
Open an APK or Elf SO file(s), run the “Recover statically-registered natives (Android)” plugin.Set optional name filters or architecture filters as needed.The results will be visible in the log. In this case, it looks like the aarch64 library libpairipcore.so registered one method for com.pairip.VMRunner.executeVM, and mapped it to a routine at 0x5F180.
Recovering constants removed from the Dex
The second plugin makes use of an IEmulatedAndroid object to simulate an execution environment and execute code that may be restoring static string constants removed from the Dex by code protection systems.
We can imagine that the code protection pass works as such:
String constants are being removed during a protection pass.
The implementation details of restore() are not relevant to this blog entry. In the case of that particular app, it involves calling into a highly obfuscated native library called libpairipcore.so.
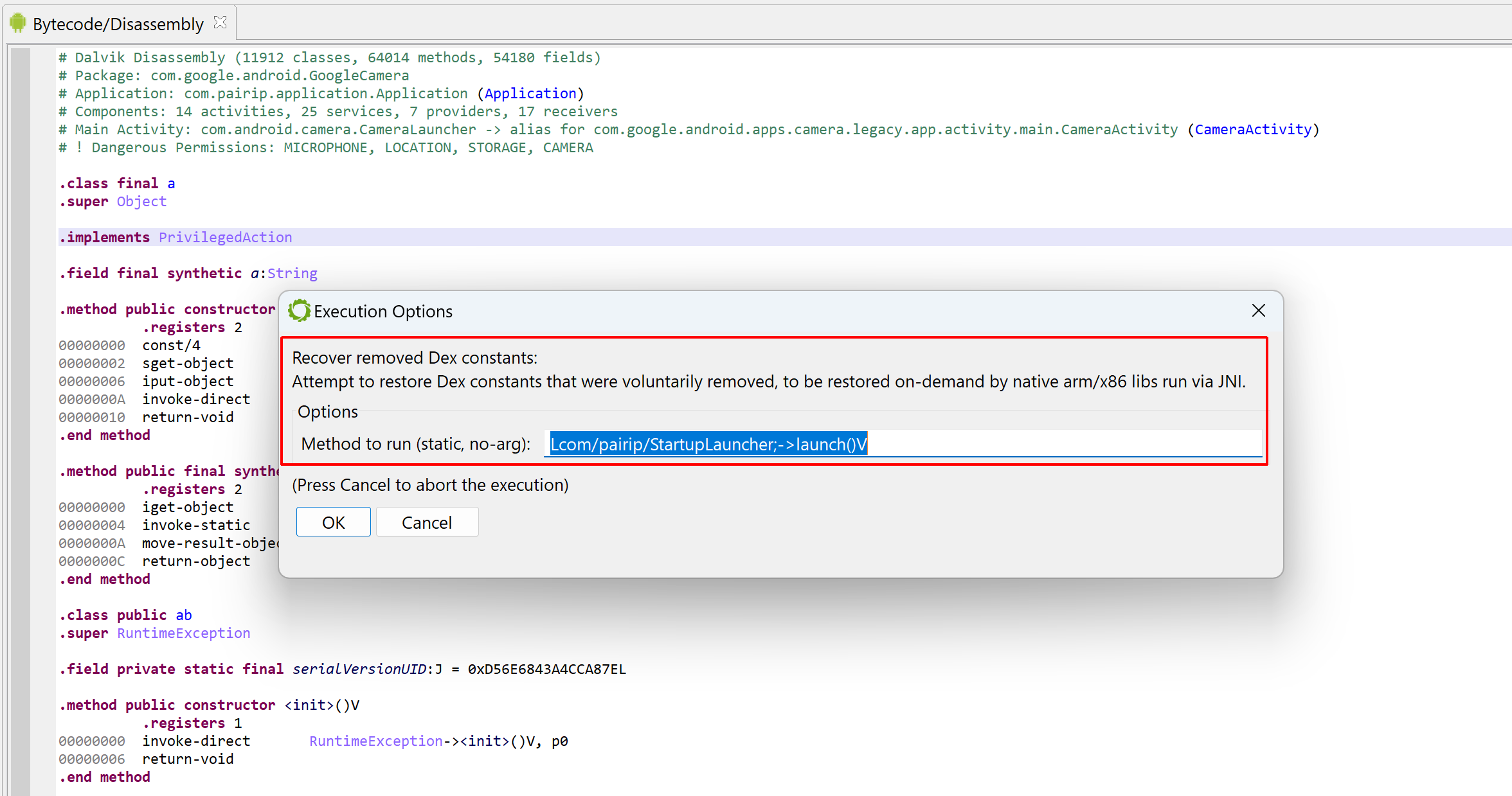
The plugin requires a full APK. It will emulate a static method selected by the user and let them know about the constants that were restored.
The plugin workflow is as follows:
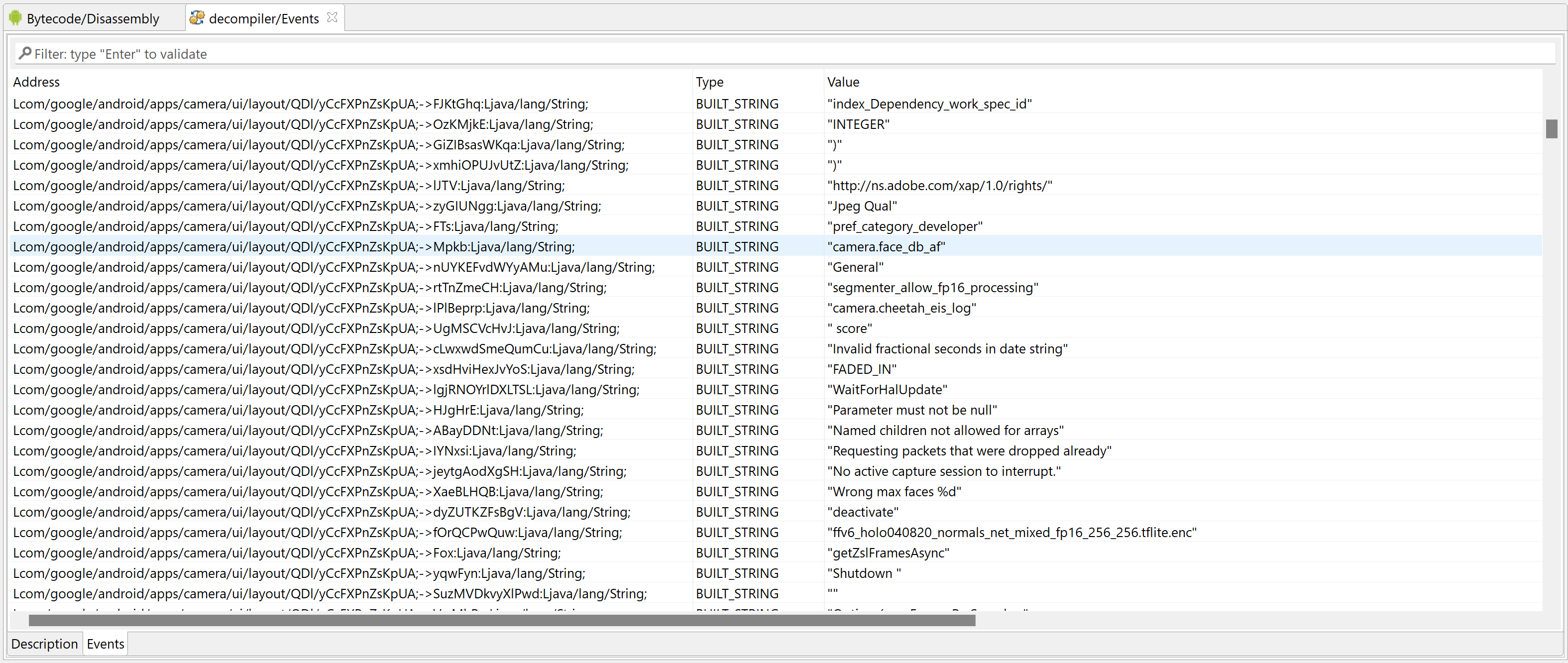
After loading an APK, the plugin may let the user know that the code was protected.Execute the “Recover removed Dex constants” plugin.The user will be asked to input the no-arg static method that should be simulated. If a suitable one is found, it may be pre-populated by the plugin.The execution can be lengthy, from several seconds to several minutes. Recovered strings are registered as fields comments as well as decompiler events in the relevant dexdec unit of your project.
Conclusion
That’s it for today. Make sure to update to JEB Pro 4.30 if you want to use those plugins.
I would encourage power-users to explore the JEB’s API, in particular IDState, EState/EEmulator and IEmulatedAndroid, if they want to experiment or work on code that requires specific hooks (dex hooks, jvm sandbox hooks, native emu hooks, native memory hooks – refer to the registerXxxHooks methods in IDState) for the emulators to operate properly.
In this post, we’re having a look at the first release of dProtect (v 1.0) by Romain Thomas. dProtect is a fork of ProGuard that provides four additional self-explanatory configuration flags:
-obfuscate-strings
-obfuscate-constants
-obfuscate-arithmetic
-obfuscate-control-flow (via flattening & opaque predicates — unfortunately, I was unable to get this flag to work, so it’s something we’ll have to revisit in the future.)
Let’s see how JEB’s dexdec’s built-in optimizers as well as custom IR plugins can be used to defeat some implementations of strings obfuscation, constants obfuscation, and arithmetic operations obfuscation.
Let’s disable dexdec’s built-in deobfuscators (CTRL+TAB to decompile, untick “Enable deobfuscators”) to get a chance to look at the obfuscated code. It decompiles to:
A decryptor method a(String):String was generated by dProtect. It performs various computations to decrypt the input string.
One built-in optimizer that ships with JEB’s dexdec uses the IDState object to perform emulation (explained in a previous blog). It cleans up such code automatically:
provideString() is auto-deobfuscated by JEB’s dexdec
Arithmetic Operations Obfuscation
The test method is as follows:
// targeted by: -obfuscate-arithmetic
public int calculate(int x) {
return 100 + x;
}
With standard JEB settings (re-tick “Enable deobfuscators” if you had disabled it), the obfuscated code decompiles to:
As can be seen, the constant 100 has been replaced by an arithmetic operation, here, a XOR operating on an immediate and a static array element set up in the class initializer.
JEB does not ship with overly complex deobfuscators operating on arrays, because it is near-impossible in the general case to assess their finality (i.e. answer the question “will values be changed during the program execution?” definitively). However, to solve particular cases of obfuscation, writing a custom IR plugin to tackle this obfuscation is an acceptable solution. (Have a look at this post to get started on dexdec IR plugins.)
Let’s check DOptUnsafeArrayAccessSubst.java, a sample IR plugin that ships with JEB (folder coreplugins/scripts/) and does does exactly what we need: detecting the use of static array elements and replacing them by their actual values. We can enable the plugin by removing the “.DISABLED” extension. Now redecompile (CTRL+TAB). And… well, nothing has changed! It is time to examine the plugin code carefully, maybe even use your favorite IDE to troubleshoot and augment it. Here is what prevented the original plugin from kicking in: the plugin was looking for IR elements such as: IDArrayElt ^ IDImm. However, the IR it got was: (<int>IDArrayElt) ^ IDImm, that is, the array element was cast to int, making the IR expression an IDOperation, not an IDArrayElt.
Now we can redecompile. and things were deobfuscated as expected:
calculate() is deobfuscated by DOptUnsafeArrayAccessSubstV2
Constants Scrambling
Finally, let’s have a look at how constants obfuscation is achieved. The documentation gives examples of cryptographic-like S-boxes being initialized. The test method is as follows:
Note that the use of synthetic static arrays is made, as was the case for the arithmetic operations obfuscation pass. Therefore, let’s try the DOptUnsafeArrayAccessSubstV2 plugin. As careful examination of the above code may give in, the plugin fails to deobfuscate this code on the first go. The reason: if you examine the IR produced while debugging the plugin, you will notice that the static array elements are accessed via a variable (v0, above). In IR, those elements are IDVar. Therefore, we need to check whether this variable references a static array. We will do that by using the data flow analysis facility made available to all dexdec plugins (public field dfa of optimizers sub-classing AbstractDOptimizer):
...
analyzeChains(); // initialize the `dfa` member field
Long defaddr = dfa.checkSingleDef(insnAddress, varid); // use-def chains
...
The obfuscated code is now processed as expected, and dexdec generates the following decompilation:
initArray() is deobfuscated by DOptUnsafeArrayAccessSubstV3
Conclusion and Future Work
dProtect is a great project to provide code obfuscation for the masses. Its compatibility with ProGuard makes integration into new and existing Android projects a breeze. I have little doubt many developers will try it out in the future. Let’s see how upcoming upgrades to the obfuscators fare against the decompiler!
In future blogs, we will have a look at dProtect’s control-flow obfuscation (once I’ve got it to work!) and we will see how O-MVLL, the LLVM-based native code obfuscator counterpart, does against JEB’s gendec (generic decompiler for native code).
Under some circumstances, JEB’s generic decompiler is able to detect inline decryptors, and subsequently attempt to emulate the underlying IR to generate plaintext data items, both in the disassembly view and, most importantly, decompiled views.1
This feature is available starting with JEB 4.0.3-beta. It makes use of the IREmulator object, available in the public API for scripting and plugins.
–
Here’s an example of a protected elf file2 (aarch64) that was encountered a few months ago:
Disassembly of the target routine
GENDEC’s unsafe optimizers are enabled by default. Let’s disable them before performing a first decompilation, in order to see what the inline decryptor looks like.
To bring up the decompilation options on-demand, use CTRL+TAB (or Command+TAB), or alternatively, menu Action, command Decompile with OptionsDecompilation #1: unsafe optimizers disabled
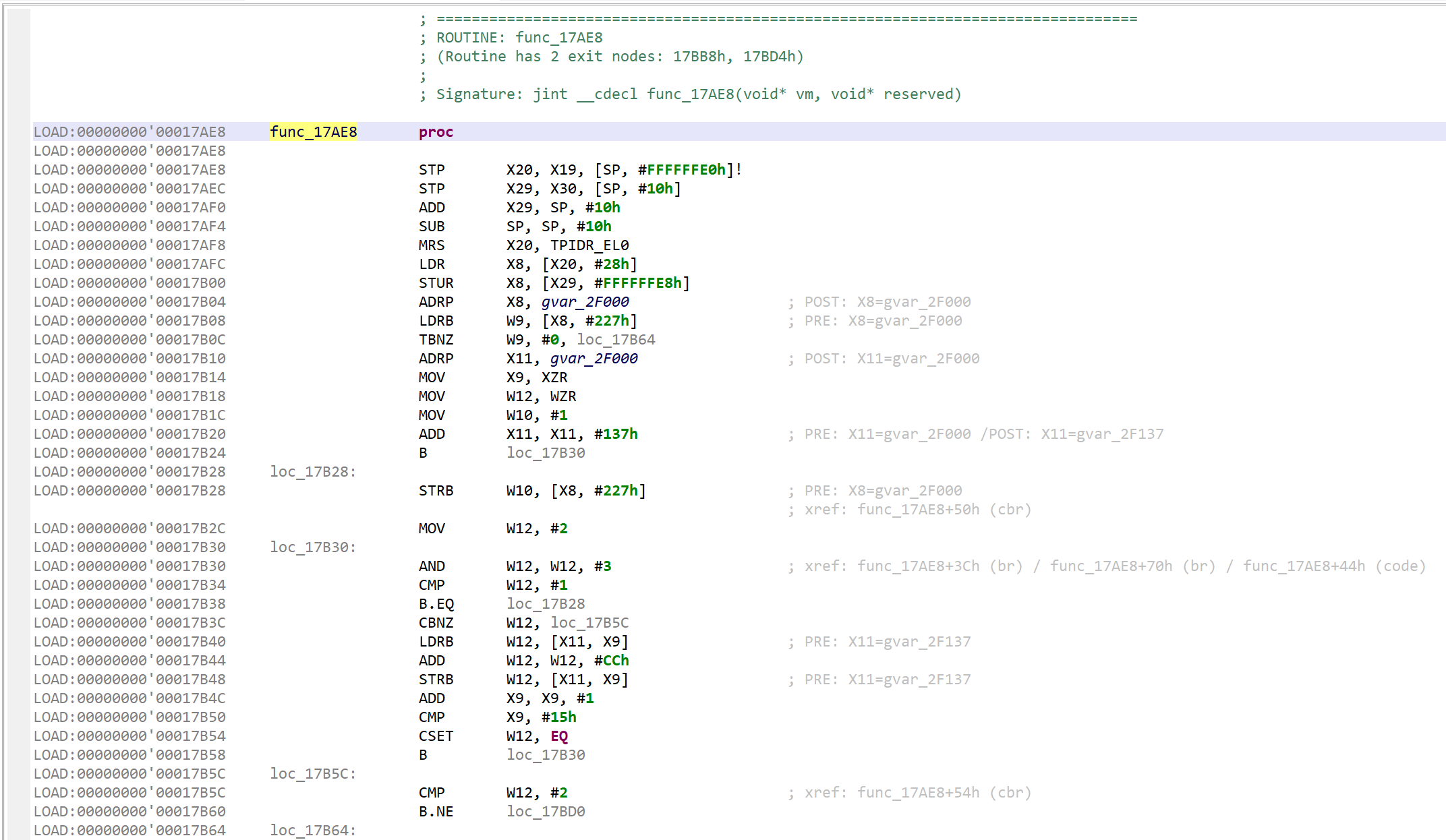
That decryptor’s control flow is obfuscated (flattened, controlled by the state variable v5). It is called once, depending on the boolean value at 0x2F227. Here, the decrypted contents is used by system_property_get.
Below, the contents in virtual memory, pre-decryption:
Encrypted contents.
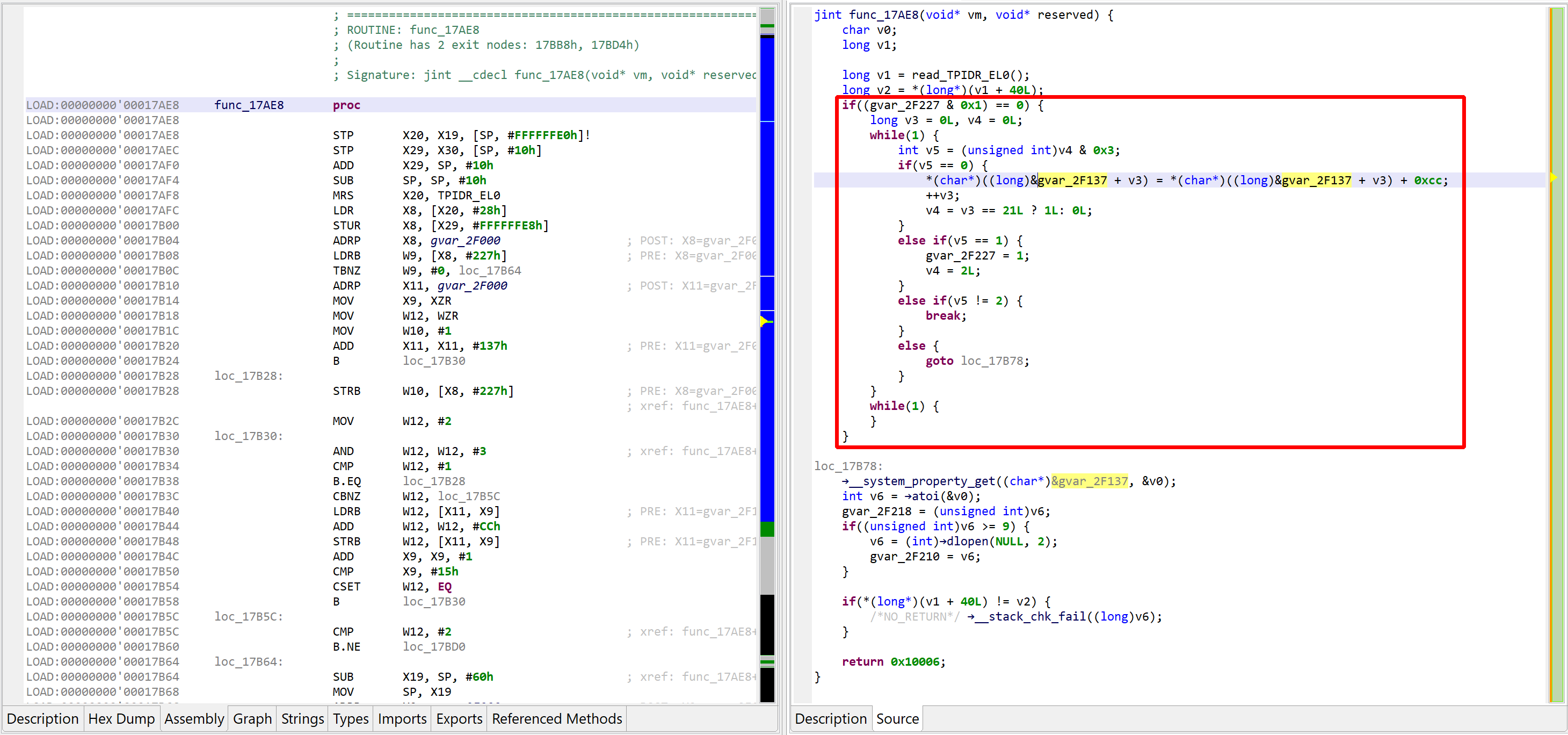
Let’s perform another decompilation of the same routine, with the unsafe optimizers enabled this time. GENDEC now will:
detect something that potentially could be decryption code
start emulating the underlying IR (not visible here, but you can easily read/write the Intermediate Representation via API) portion of code is emulated
collect and apply results
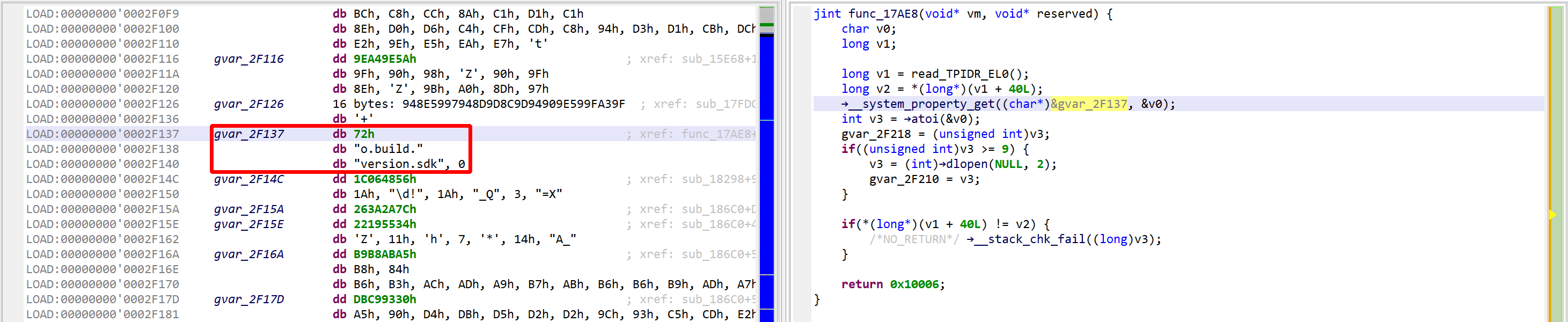
See the decrypted contents below. (An data item existed beforehand at 0x2F137, and the decompiler chose not to erase it.) The decompiled code on the right panel no longer shows the decryption loop: an optimizer has discarded it since it can no longer be executed.
Decompilation #2: unsafe optimizers enabled
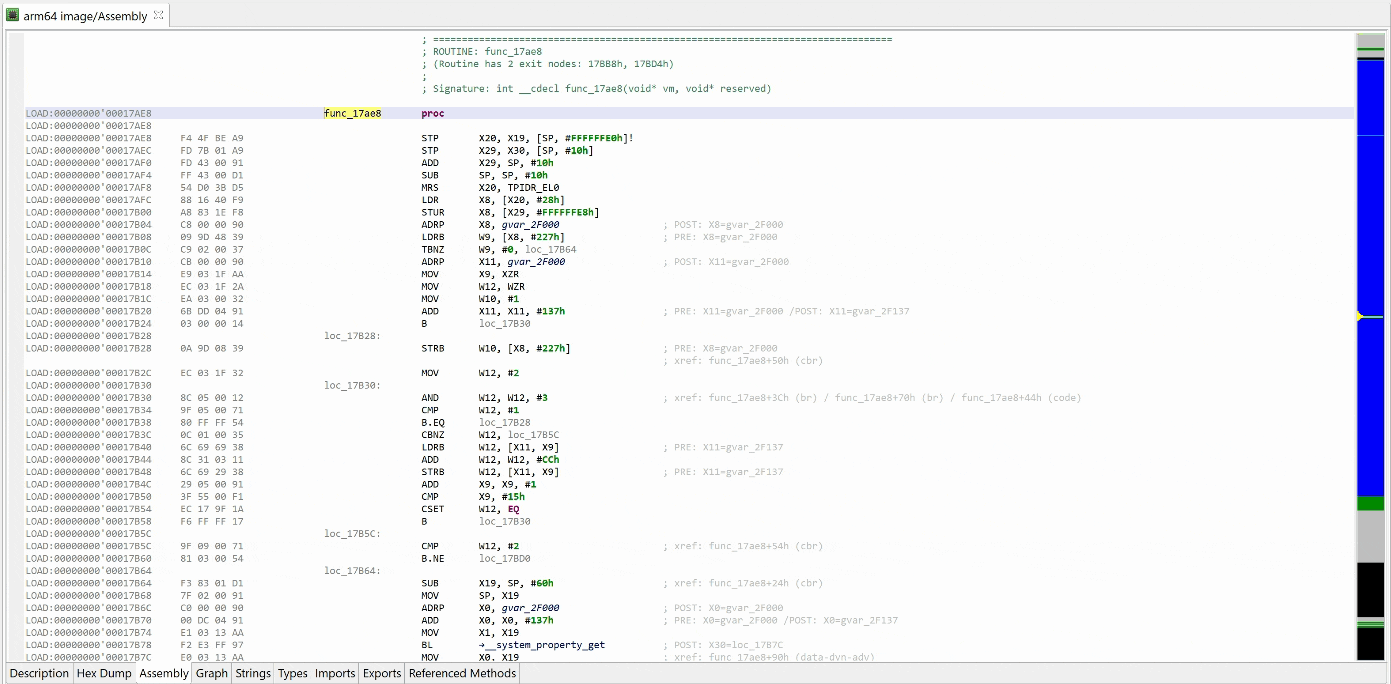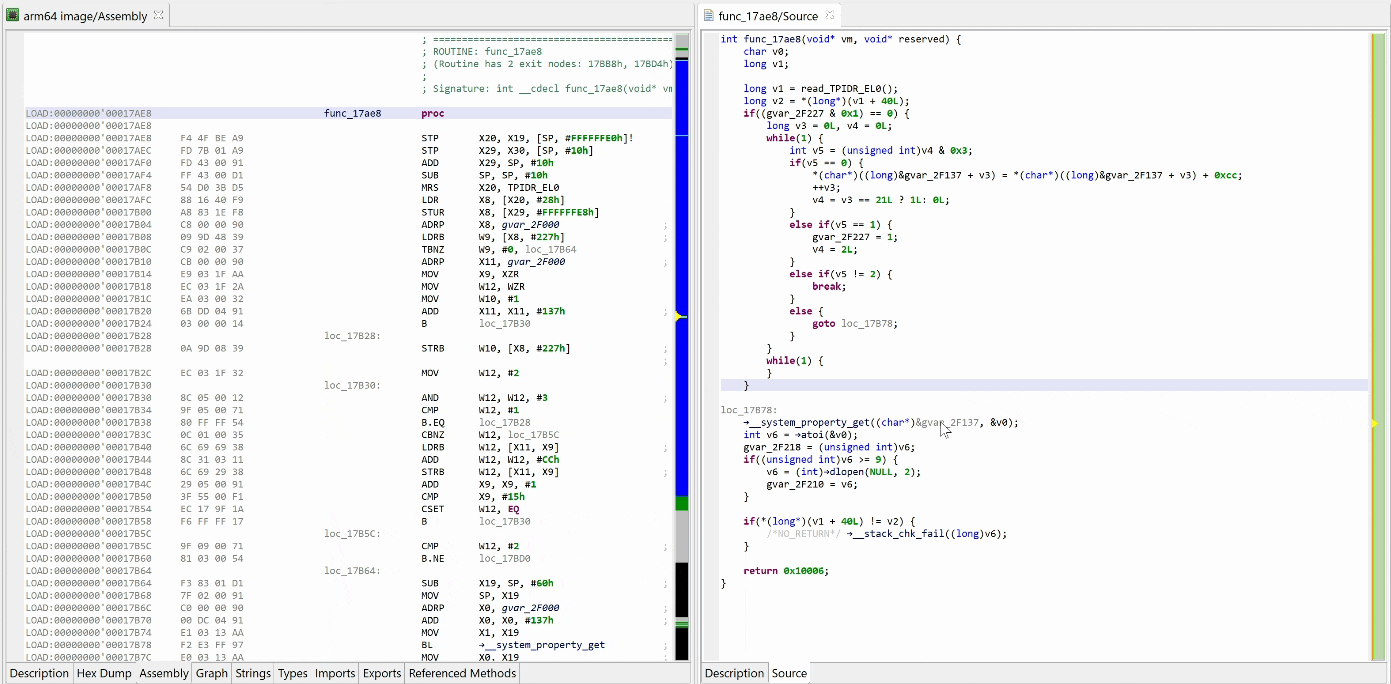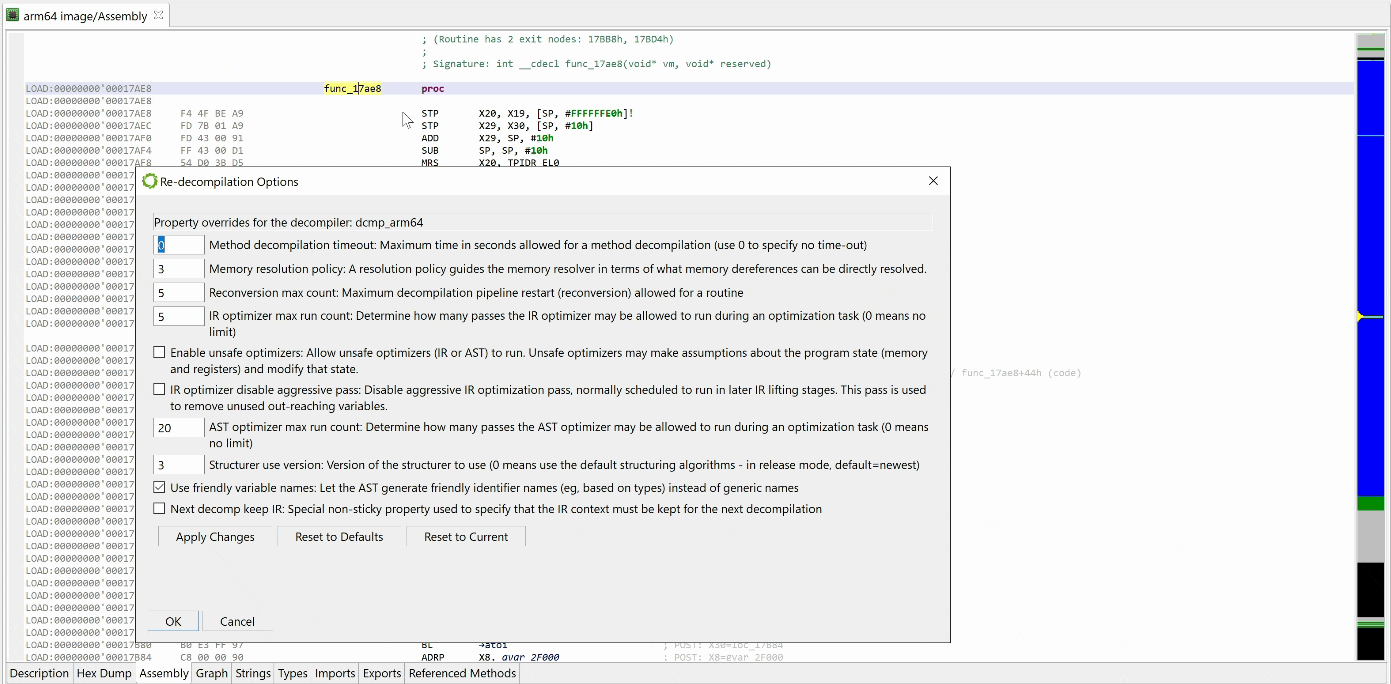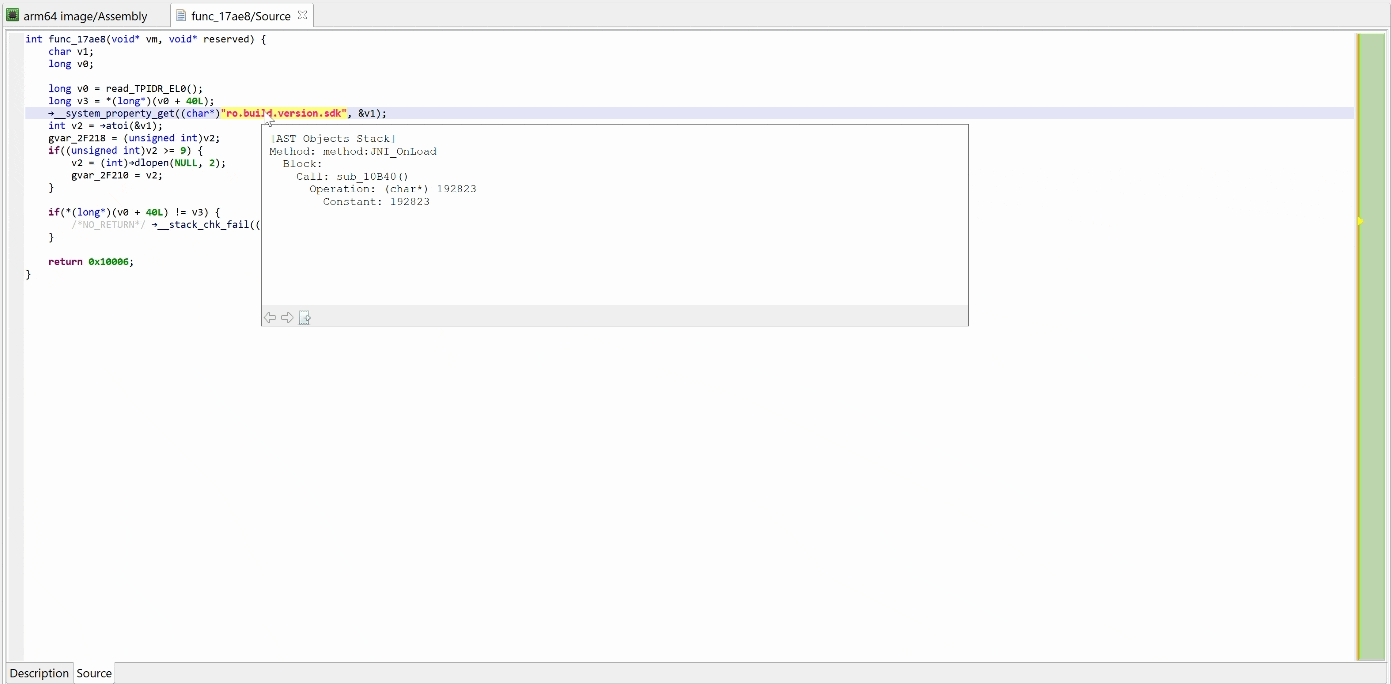
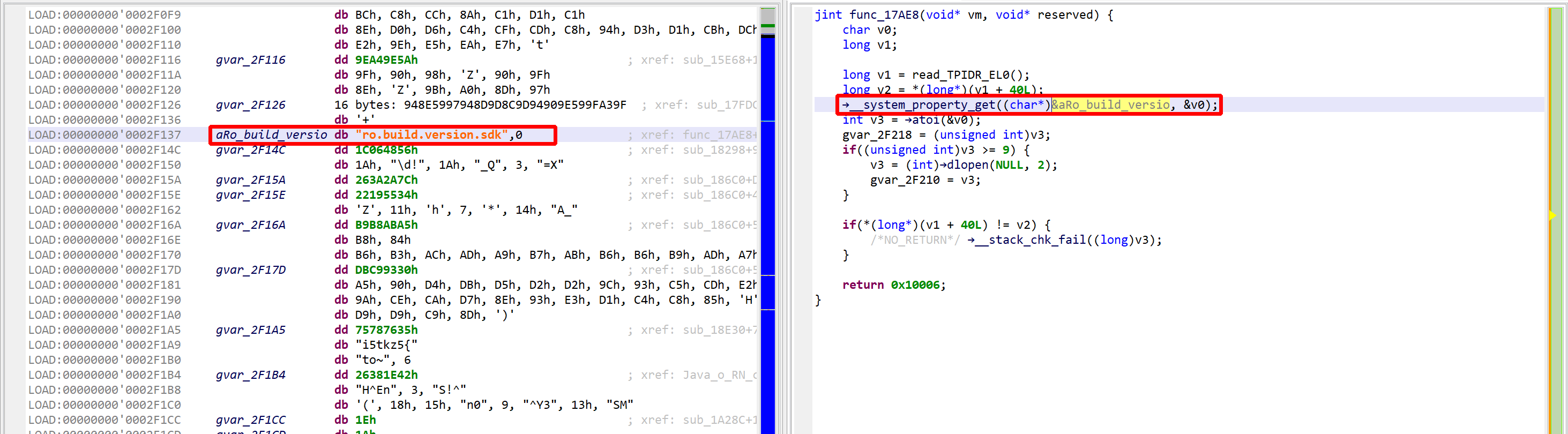
We may convert the data item (or bytes) to a string by pressing the A key (menu Native, command Create String). The decompiled code will pick it up and refresh the AST as well.
The final result looks like:
The VM and decompiled view show the decrypted code, “ro.build.version.sdk”
A few additional comments:
This optimizer is considered unsafe3because it is allowed to modify the VM of the underlying native code unit, as seen above.
The optimizer is generic (architecture-agnostic). It performs its work on the underlying IR mid-stage in the decompilation pipeline, when various optimizations are applied.
It makes use of public API methods only, mostly the IREmulator class. Advanced users can write similar optimizers if they choose to. (We will also publish the code of this optimizer on GitHub shortly, as it will serve as a good real-life example of how to use the IR emulator to write powerful optimizers. It’s slightly more than 100 lines of Java.)
We hope you enjoy using JEB 4 Beta. There is a license type for everyone, so feel free to try things out. Do not hesitate to reach out to us on Twitter, Slack, or privately over email! Thanks, and until next time 🙂
Users familiar with JEB’s Dex decompilers will remember that a similar feature was introduced to JEB 3 in 2020, for Android Dalvik code. ↩
sha256 43816c47315aab27e50e6f895774a7b86d591807179e1d3262446ab7d68a56ef also available as lib/arm64-v8a/libd.so in 309d848275aa128ebb7e27e570e5a2876977122625638630a6c61f7434b771c3 ↩
“unsafe” in the context of decompilation; unsafe here is not to be understood as, “could any code be executed on the machine”, etc. ↩
Disclaimer: a long time ago in our galaxy, we published part 1 of this blog post; then we decided to wait for the next major release of JEB decompiler before publishing the rest. A year and a half later, JEB 4.0 is finally out! So it is time for us to publish our complete adventure with MarsAnalytica crackme. This time as one blog covering the full story.
In this blog post, we will describe our journey toward analyzing a heavily obfuscated crackme dubbed “MarsAnalytica”, by working with JEB’s decompiled C code 1.
To reproduce the analysis presented here, make sure to update JEB to version 4.0+.
Part 1: Reconnaissance
MarsAnalytica crackme was created by 0xTowel for NorthSec CTF 2018. The challenge was made public after the CTF with an intriguing presentation by its author:
My reverse engineering challenge ‘MarsAnalytica’ went unsolved at #nsec18 #CTF. Think you can be the first to solve it? It features heavy #obfuscation and a unique virtualization design.
Given that exciting presentation, we decided to use this challenge mainly as a playground to explore and push JEB’s limits (and if we happen to solve it on the road, that would be great!).
The MarsAnalytica sample analyzed in this blog post is the one available on 0xTowel’s GitHub2. Another version seems to be available on RingZer0 website, called “MarsReloaded”.
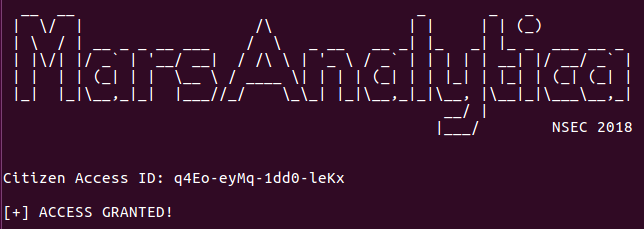
So, let’s examine the beast! The program is a large x86-64 ELF (around 10.8 MB) which, once executed, greets the user like this:
Inserting a dummy input gives:
It appears we have to find a correct Citizen ID! Now let’s open the executable in JEB. First, the entry point routine:
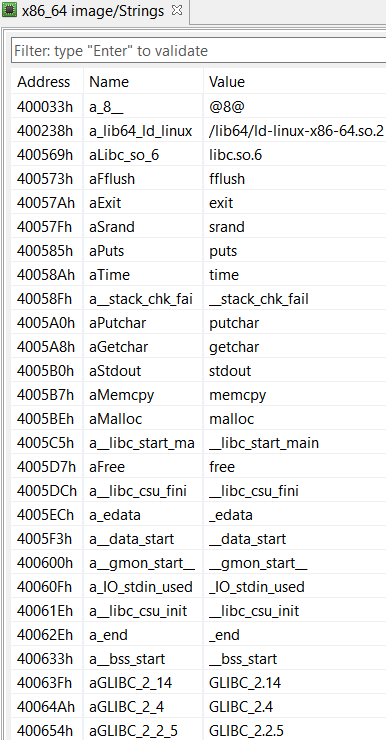
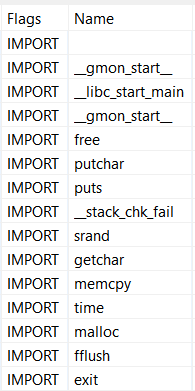
A few interesting imports: getchar() to read user input, and putchar() and puts() to write. Also, some memory manipulation routines, malloc() and memcpy(). No particular strings stand out though, not even the greeting message we previously saw. This suggests we might be missing something.
Actually, looking at the native navigation bar (right-side of the screen by default), it seems JEB analyzed very few areas of the executable:
Navigation Bar (green is cursor’s location, grey represents area without any code or data)
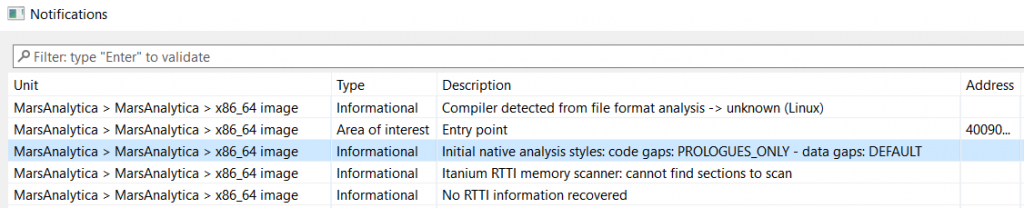
To understand what happened let’s first look at JEB’s notifications window (File > Notifications):
Notifications Window
An interesting notification concerns the “Initial native analysis styles”, which indicates that code gaps were processed in PROLOGUES_ONLY mode (also known as a “conservative” analysis). As its name implies, code gaps are then disassembled only if they match a known routine prologue pattern (for the identified compiler and architecture).
This likely explains why most of the executable was not analyzed: the control-flow could not be safely followed and unreferenced code does not start with common prologue patterns.
Why did JEB used conservative analysis by default? JEB usually employs aggressive analysis on standard Linux executables, and disassembles (almost) anything within code areas (also known as “linear sweep disassembly”). In this case, JEB went conservative because the ELF file looks non-standard (eg, its sections were stripped).
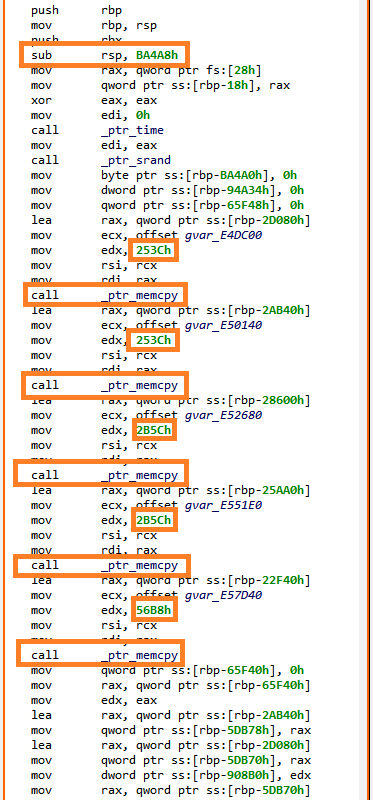
So, first a few memcpy() to copy large memory areas onto the stack, followed by series of “obfuscated” computations on these data. The main() routine eventually returns on an address computed in rax register. In the end, JEB disassembler was not able to get this value, hence it stopped analyzing there.
Let’s open the binary in JEB debugger, and retrieve the final rax value at runtime: 0x402335. We ask JEB to create a routine at this address (“Create Procedure”, P), and end up on very similar code. After manually following the control-flow, we end up on very large routines — around 8k bytes –, with complex control-flow, built on similar obfuscated patterns.
And yet at this point we have only seen a fraction of this 10MB executable… We might naively estimate that there is more than 1000 routines like these, if the whole binary is built this way (10MB/8KB = 1250)!
Most obfuscated routines re-use the same stack frame (initialized in main() with the series of memcpy()). In others words, it looks like a very large function has been divided into chunks, connected through each other by obfuscated control flow computations.
At this point, it seems pretty clear that a first objective would be to properly retrieve all native routines. Arguably the most robust and elegant way to do that would be to follow the control flow, starting from the entry point routine . But how to follow through all these obfuscated computations?
Explore The Code (At C Level)
Let’s now take a look at the pseudo-C code produced by JEB for those first routines. For example, here is main():
Decompiled main()
Overall, around 40 lines of C code, most of them being simple assignments, and a few others being complex operations. In comparison to the 200 non-trivial assembly instructions previously shown, that’s pretty encouraging.
What Do We Know
Let’s sum up what we noticed so far: MarsAnalytica’s executable is divided into (pretty large) handler routines, each of them passing control to the next one by computing its address. For that purpose, each handler reads values from a large stack, make a series of non-trivial computations on them, then write back new values into the stack.
As originally mentioned by 0xTowel, the crackme author, it looks like a virtual-machine style obfuscation, where bytecodes are read from memory, and are interpreted to guide the execution. It should be noted that virtual machine handlers are never re-executed: execution seems to go from lower to higher addresses, with new handlers being discovered and executed.
Also, let’s notice that while the executable is strongly obfuscated, there are some “good news”:
There does not seem to be any self-modifying code, meaning that all the code is statically visible, we “just” have to compute the control-flow to find it.
JEB decompiled C code looks (pretty) simple, most C statements are simple assignments, except for some lengthy expression always based on the same operations; the decompilation pipeline simplified away parts of the complexity of the various assembly code patterns.
There are very few subroutines called (we will come back on those later), and also a few system APIs calls, so most of the logic is contained within the chain of obfuscated handlers.
What Can We Do
Given all we know, we could try to trace MarsAnalytica execution by implementing a C emulator working on JEB decompiled code. The emulator would simulate the execution of each handler routine, update a memory state, and retrieve the address of the next handler.
The emulator would then produce an execution trace, and provide us access to the exact memory state at each step. Hence, we should find at some point where the user’s input is processed (typically, a call to getchar()), and then hopefully be able to follow how this input gets processed.
The main advantage of this approach is that we are going to work on (small) C routines, rather than large and complex assembly routines.
There are a few additional reasons we decided to go down that road:
– The C emulator would be architecture-independent — several native architectures are decompiled to C by JEB –, allowing us to re-use it in situations where we cannot easily execute the target (e.g. MIPS/ARM).
– It will be an interesting use-case for JEB public API to manipulate C code. Users could then extend the emulator to suit their needs.
– This approach can only work if the decompilation is correct, i.e. if the C code remains faithful to the original native code. In other words, it allows to “test” JEB decompilation pipeline’s correctness, which is — as a JEB’s developer — always interesting!
Nevertheless, a major drawback of emulating C code on this particular executable, is that we need the C code in the first place! Decompiling 10MB of obfuscated code is going to take a while; therefore this “plan” is certainly not the best one for time-limited Capture-The-Flag competitions.
Part 2: Building a (Simple) C Emulator
The emulator comes as a JEB back-end plugin, whose code can be found on our GitHub page. It starts in CEmulatorPlugin.java, whose logic can be roughly summarized as the following pseudo-code:
In this part we will focus on emulate()method. This method’s purpose is to simulate the execution of a given C routine from a given machine state, and to provide in return the final machine state at the end of the routine.
Decompiled C Code
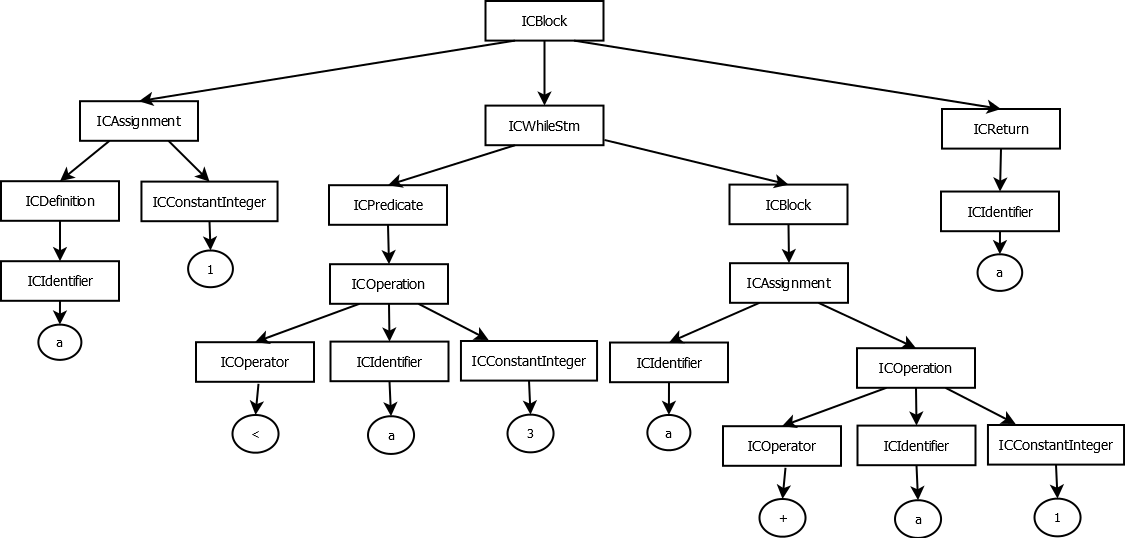
First thing first, let’s explore what JEB decompiled code looks like, as it will be emulate() input. JEB decompiled C code is stored in a tree-structured representation, akin to an Abstract Syntax Tree (AST).
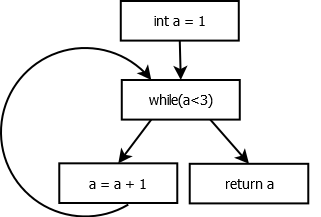
For example, let’s take the following C function:
int myfunction()
{
int a = 1;
while(a < 3) {
a = a + 1;
}
return a;
}
The JEB representation of myfunction body would then be:
AST Representation (rectangles are JEB interfaces, circles are values)
As of JEB 4.0, the hierarchy of interfaces representing AST elements (i.e. nodes in the graph) is the following:
AST ICElement Hierarchy
Two parts of this hierarchy are of particular interest to us, in the context of building an emulator:
ICExpression represents C expressions, for example ICIdentifier (a variable), or ICOperation (any operation). Our emulator is going to evaluate those expressions, i.e. assign concrete values to them.
While an AST provides a precise representation of C elements, it does not provide explicitly the control flow. That is, the order of execution of statements is not normally provided by an AST, which rather shows how some elements contain others from a syntactic point-of-view.
In order to simulate a C function execution, we are going to need the control flow. So here is our first step: compute the control flow of a C method and make it usable by our emulator.
To do so, we implemented a very simple Control-Flow Graph (CFG), which is computed from an AST. The code can be found in CFG.java, please refer to the documentation for the known limitations.
Here is for example the CFG for the routine previously presented myfunction():
myfunction() CFG
Why does JEB does not provide a CFG for decompiled C code? Mainly because at this point JEB decompiler does not need it. Most important optimizations are done on JEB Intermediate Representation — for which there is indeed a CFG. On the other hand, C optimizations are mainly about “beautifying” the code (i.e. pure syntactic transformations), which can be done on the AST only 3.
Before digging into the emulation logic, let’s see how emulator state is represented and initialized.
Emulator State
The emulator state is a representation of the machine’s state during emulation; it mainly comprehends the state of the memory and of the CPU registers.
The memory state is a IVirtualMemory object — JEB interface to represent virtual memory state. This memory state is created with MarsAnalytica executable initial memory space (set by JEB loader), and we allocate a large area at an arbitrary address to use as the stack during emulation:
// initialize from executable memory
memory = nativeUnit.getMemory();
// allocate large stack from BASE_STACK_POINTER_DEFAULT_VALUE (grows downward)
VirtualMemoryUtil.allocateFillGaps(memory, BASE_STACK_POINTER_DEFAULT_VALUE - 0x10_0000, 0x11_0000, IVirtualMemory.ACCESS_RW);
The CPU registers state is simply a Map from register IDs — JEB specific values to identify native registers — to values:
Update the state according to the statement semantic, i.e. propagate all side-effects of the statement to the emulator state.
Determine which statement should be executed next; this might involve evaluating some predicates.
For example, let’s examine the logic to emulate a simple assignment like a = b + 0x174:
void evaluateAssignment(ICAssignment assign) {
// evaluate right-hand side
Long rightValue = evaluateExpression(assign.getRight());
// assign to left-hand side
state.setValue(assign.getLeft(), rightValue);
}
The method evaluateExpression() is in charge of getting a concrete value for a C expression (i.e. anything under ICExpression), which involves recursively processing all the subexpressions of this expression.
In our example, the right-hand side expression to evaluate is an ICOperation (b + 0x17). Here is the extract of the code in charge of evaluating such operations:
If b is a local variable, i.e. mapped in stack memory, the method ICIdentifier.getAddress() provides us its offset from the stack base address. Also note that an ICIdentifier has an associated ICType, which provides us the variable’s size (through the type manager, see emulator’s getTypeSize()).
Finally, evaluating constant 0x17 in the operation b + 0x17 simply means returning its raw value:
For statements with more complex control flow than an assignment, the emulator has to select the correct next statement from the CFG. For example, here is the emulation of a while loop wStm (ICWhileStm):
// if predicate is true, next statement is while loop body...
if(evaluateExpression(wStm.getPredicate()) != 0) {
return cfg.getNextTrueStatement(wStm);
}
// ...otherwise next statement is the one following while(){..}
else {
return cfg.getNextStatement(wStm);
}
In MarsAnalytica there are only a few system APIs that get called during the execution. Among those APIs, only memcpy() is actually needed for our emulation, as it serves to initialize the stack (remember main()). Here is the API emulation logic:
Long simulateWellKnownMethods(ICMethod calledMethod,
List<ICExpression> parameters) {
if(calledMethod.getName().equals("→time")) {
return 42L; // value does not matter
}
else if(calledMethod.getName().equals("→srand")) {
return 37L; // value does not matter
}
else if(calledMethod.getName().equals("→memcpy")) {
ICExpression dst = parameters.get(0);
ICExpression src = parameters.get(1);
ICExpression n = parameters.get(2);
// evaluate parameters concrete values
[...REDACTED...]
state.copyMemory(src_, dst_, n_);
return dst_;
}
}
}
Demo Time
The final implementation of our tracer can be found in our GitHub page. Once executed, the plugin logs in JEB’s console an execution trace of the emulated methods, each of them providing the address of the next one:
Good news everyone: the handlers addresses are correct (we double-checked them with a debugger). In other words, JEB decompilation is correct and our emulator remains faithful to the executable logic. Phew…!
Part 3: Solving The Challenge
Plot Twist: It Does Not Work
The first goal of the emulator was to find where user’s input is manipulated. We are looking in particular for a call to getchar(). So we let the emulator run for a long time, and…
…it never reached a call to getchar().
The emulator was correctly passing through the obfuscated handlers (we regularly double-checked their addresses with a debugger), but after a few days the executed code was still printing MarsAnalytica magnificent ASCII art prompt (reproduced below).
MarsAnalytica Prompt
After investigating, it appears that characters are printed one by one with putchar(), and each of these calls is in the middle of one heavily obfuscated handler, which will be executed once only. More precisely, after executing more than one third of the whole 10MB, the program is still not done with printing the prompt!
As mentioned previously, the “problem” with emulating decompiled C code is that we need the decompiled code in the first place, and decompiling lots of obfuscated routines takes time…
Let’s Cheat
Ok, we cannot reach in a decent time the point where the user’s input is processed by the program. But the execution until this point should be deterministic. What if… we start the emulation at the point where getchar() is called, rather than from the entry-point?
In other words, we are going to assume that we “found” the place where user’s input starts to be processed, and use the emulator to analyze how this input is processed.
To do so, we used GDB debugger to set a breakpoint on getchar() and dumped both stack and heap memories at this point 5. Then, we extended the emulator to be able to initialize its memory state from stack/heap memory dumps, and change emulation start address to be the first call to getchar().
What Now?
At this point getchar() is called to get the first input character, so we let the emulator simulate this API by returning a pseudo-randomly chosen character, such that we can follow the rest of the execution. After 19 calls to getchar() we finally enter the place where user’s input is processed. Hooray…
Then, we let the emulator run for a whole day, which provided the execution trace we will be working on for the rest of this blog. After digging into the trace we noticed that input characters were passed as arguments to a few special routines.
Introducing The Stack Machine
When we first skimmed through MarsAnalytica code, we noticed a few routines that seemed specials for two reasons:
While obfuscated routines are executed only once and in a linear fashion (i.e. from low to high memory addresses), these “special” routines are at the very beginning of the executable and are called very often during the execution.
These routines’ code is not obfuscated and seems to be related with memory management at first sight.
For example, here is JEB decompiled code for the first of them (comments are ours):
long sub_400AAE(unsigned long* param0, int param1) {
long result;
unsigned long* ptr0 = param0;
int v0 = param1;
if(!ptr0) {
result = 0xffffffffL;
}
else {
// allocate new slot
void* ptr1 = →malloc(16L);
if(!ptr1) {
/*NO_RETURN*/ →exit(0);
}
// set value in new slot
*(int*)((long)ptr1 + 8L) = v0;
// insert new slot in first position
*(long*)ptr1 = *ptr0;
*ptr0 = ptr1;
result = 0L;
}
return result;
}
What we have here is basically a “push” operation for a stack implemented as a chained list (param0 is a pointer to the top of the stack, param1 the value to be pushed).
Each slot of the stack is 16 bytes, with the first 8 bytes being a pointer to the next slot and the next 4 bytes containing the value (remaining 4 bytes are not used).
It now seemed clear that these special routines are the crux of the challenge. So we reimplemented most of them in the emulator, mainly as a way to fully understand them. For example, here is our “push” implementation:
/** PUSH(STACK_PTR, VALUE) */
if(calledMethod.getName().equals("sub_400AAE")) {
Long pStackPtr = evaluateExpression(parameters.get(0));
Long pValue = evaluateExpression(parameters.get(1));
long newChunkAddr = allocateNewChunk();
// write value
state.writeMemory(newChunkAddr + 8, pValue, 4);
// link new chunk to existing stack
Long stackAdr = state.readMemory(pStackPtr, 8);
state.writeMemory(newChunkAddr, stackAdr, 8);
// make new chunk the new stack head
state.writeMemory(pStackPtr, newChunkAddr, 8);
}
Overall, these operations are implementing a custom data-structure that can be operated in a last-in, first-out fashion, but also with direct accesses through indexes. Let’s call this data structure the “stack machine”.
Here are the most used operators:
Address
Operator (names are ours)
Argument(s)
0x400AAE
PUSH
VALUE
0x4009D7
POP
VALUE
0x400D08
GET
INDEX
0x400D55
SET
INDEX,VALUE
Stack Machine’s Main Operators
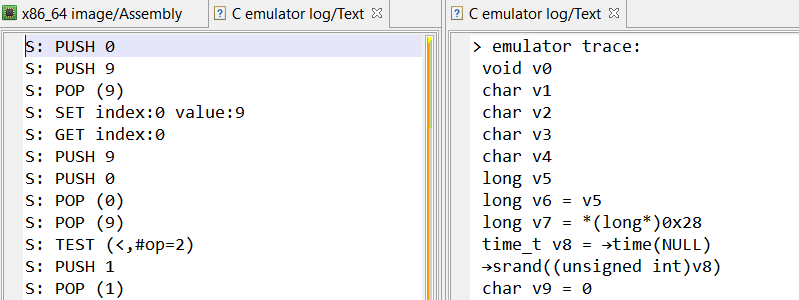
Tracing The Stack Machine
At this point, we modified the emulator to log only stack operations with their arguments, starting from the first call to getchar(). The full trace can be found here, and here is an extract:
S: SET index:7 value:97
S: SET index:8 value:98
S: SET index:13 value:99
S: SET index:15 value:100
S: SET index:16 value:101
[...REDACTED...]
S: PUSH 2700
S: POP (2700)
S: SET index:32 value:2700
S: GET index:32
S: PUSH 2700
S: PUSH 2
S: POP (2)
S: POP (2700)
S: PUSH 2702
[...REDACTED...]
The trace starts with a long series of SET operations, which are storing the result of getchar() at specific indexes in the stack machine (97, 98, 99,… are characters provided by the emulator).
And then, a long series of operations happen, combining the input characters with some constant values. Some interesting patterns appeared at this point, for example:
S: POP (2)
S: POP (2700)
S: PUSH 2702
Here an addition was made between the two popped values, and the result was then pushed. Digging into the trace, it appears there are also handlers popping two values and pushing back a subtraction, multiplication, exclusive or, etc.
Another interesting pattern appears at several places:
S: POP (16335)
S: POP (1234764)
S: PUSH 1
Looking at the corresponding C code, it is actually a comparison between the two popped values — “greater than” in this case –, and the boolean result (0 or 1) is then pushed. Once again, different comparison operators (equal, not equal, …) are used in different handlers.
Finally, something suspicious also stood out in the trace:
S: PUSH 137
S: PUSH 99
S: POP (137)
S: POP (99)
The popped values do not match the order in which they were pushed!
Our objective here is to understand how input characters are manipulated, and what tests are done on them. In other words,we want to know for each POP/POP/PUSH pattern if it is an operation (and which operation — addition, subtraction …–), or a test (and which test — equal, greater than …–).
Again, note that routines implementing POP/POP/PUSH patterns are executed only once. So we cannot individually analyze them and rely on their addresses.
This is where working on decompiled C code becomes particularly handy. For each POP/POP/PUSH series:
We search in the method’s decompiled code if a C operator was used on the PUSH operand. To do so, it is as simple as looking at the operand itself, thanks to JEB decompiler’s optimizations! For example, here is a subtraction:
...
long v1 = pop(v0 - 0x65f48L); long v2 = pop(v0 - 0x65f48L); push(v0 - 0x65f48L, v1 - v2);
...
When a C operator is found in push() second operand, the emulator adds the info (with the number of operands) in the trace:
S: POP (137)
S: POP (99)
S: PUSH 38
| operation: (-,#op=2)
Also, we check if there is a “if” statement following a POP in the C code. For example, here is a “greater-than” check between popped values:
...
long v2 = pop(v0 - 0x65f48L); long v3 = pop(v0 - 0x65f48L); if(v2 > v3) {
...
If so, the emulator extracts the C operator used in the if statement and logs it in the trace (as a pseudo stack operator named TEST):
S: POP (16335)
S: POP (1234764)
S: TEST (>,#op=2)
S: PUSH 0
It should be noted that operands are always ordered in the same way: first poped value is on left side of operators. So operators and operands are the only thing we need to reconstruct the whole operation.
Time To Go Symbolic
At this point, our execution trace shows how the user’s input is stored onto the stack, and which operations and tests are then done. Our emulator is providing a “bad” input, so they are certainly failed checks in our execution trace. Our goal is now to find these checks, and then the correct input characters.
At this point, it is time to introduce “symbolic” inputs, rather than using concrete values as we have in our trace. To do so, we made a quick and dirty Python script to replay stack machine trace using symbolic variables rather than concrete values.
First, we initialize a Python “stack” with symbols (the stack is a list(), and the symbols are strings representing each character “c0“, “c1“, “c2“…). We put those symbols at the same indexes used by the initial SET operations:
# fill stack with 'symbolic' variables (ie, characters)
# at the initial offset retrieved from the trace
stack = [None] * 50 # arbitrary size
charCounter = 0
stack[7] = 'c' + str(charCounter) # S: SET index:7 value:c0
charCounter+=1
stack[8] = 'c' + str(charCounter) # S: SET index:8 value:c1
[... REDACTED ...]
We also need a temporary storage for expressions that get popped from the stack.
Then, we read the trace file and for each stack operation we execute the equivalent operation on our Python stack:
if operator == "SWAP":
last = stack.pop()
secondToLast = stack.pop()
stack.append(last)
stack.append(secondToLast)
elif operator == "GET":
index = readIndexFromLine(curLine)
temporaryStorage.append(stack[int(index)])
elif operator == "SET":
index = readIndexFromLine(curLine)
stack[int(index)] = temporaryStorage.pop()
elif operator == "POP":
value = stack.pop()
temporaryStorage.append(value)
[... REDACTED ...]
Now here is the important part: whenever there is an operation, we build a new symbol by “joining” the symbol operands and the operator. Here is an example of an addition between symbols “c5” and “c9“, corresponding respectively to the concrete input characters initially stored at index 26 and 4:
Concrete Trace
Symbolic Trace
... GET index:26
PUSH 102
GET index:4
PUSH 106
POP (106)
POP (102)
PUSH 208 | operation: (+,#op=2) ...
... GET index:26
PUSH "c5"
GET index:4
PUSH "c9"
POP ("c9")
POP ("c5")
PUSH "c9+c5"
...
Concrete execution trace, and its corresponding symbolic trace; on the symbolic side, rather than pushing the actual result of 106 + 102, we build an addition between the two symbols corresponding to the two concrete values
Note that our symbolic executor starts with a clean stack, containing only input symbols. All constants used during the computation are indeed coming from the bytecode (the large memory area copied on the (native) stack at the beginning of the execution), and not from the stack machine.
We can then observe series of operations on input symbols getting build by successive POP/POP/PUSH patterns, and being finally checked against specific values. Here is an extract of our stack at the end:
Here is another advantage to work with C code: the expressions built from our emulator’s trace are using high-level operators, which are directly understood by Z3.
Finally, we ask Z3 for a possible solution to the constraints, and we build the final string from c0, c1,… values:
m = s.model()
result = ''
result += chr(m[c0].as_long())
result += chr(m[c1].as_long())
result += chr(m[c2].as_long())
result += chr(m[c3].as_long())
...
And…
Hurray!
Conclusion
We hope you enjoy this blog post, where we used JEB C decompiled code to analyze a heavily obfuscated executable.
Please refer to our GitHub page for emulator code. While it has been tailored for MarsAnalytica crackme, it can be extended to emulate any executable’s decompiled C code (MarsAnalytica’s specific emulation logic is constrained in subclass MarsAnalyticaCEmulator).
You can run the plugin directly from JEB UI (refer to README):
By default, it will show emulation traces as text subunits in JEB project (stack machine trace in MarsAnalytica mode, or just C statements trace):
Plugin output: left panel is MarsAnalytica stack machine trace (when MarsAnalytica specific emulation logic is enabled), while right panel shows C statements emulation trace
Alternatively, the plugin comes with a headless client, more suitable to gather long running emulation traces.
Finally, kudo to 0xTowel for the awesome challenge! You can also check the excellent Scud’s solution.
Feel free to message us on Slack if you have any questions. In particular, we would be super interested if you attempt to solve complex challenges like this one with JEB!
While JEB’s default decompiled code follows (most of) C syntactic rules and their semantics, some custom operators might be inserted to represent low-level operations and ease the reading; hence strictly speaking JEB’s decompiled code should be called pseudo-C. The decompiled output can also be variants of C, e.g. the Ethereum decompiler produce pseudo-Solidity code. ↩
SHA1 of the UPX-packed executable: fea9d1b1eb9d3f93cea6749f4a07ffb635b5a0bc ↩
Implementing a complete CFG on decompiled C code will likely be done in future versions of JEB, in order to provide more complex C optimizations. ↩
The actual implementation is more complex than that, e.g. it has to deal with pointers dereferencement, refer to emulateStatement() for details. ↩
Dumping memory was done with peda for GDB, and commands dumpmem stack.mem stack and dumpmem heap.mem heap↩
The third part of this series is about bytecode virtualization. The analyses that follow were done statically.
Bytecode virtualization is the most interesting and technically challenging feature of this protector.
TL;DR: – JEB Pro can un-virtualize protected methods. – A Global Analysis (Android menu) will point you to p-code VM routines. – Make sure to disable Parse Exceptions when decompiling such methods. – For even clearer results, rename opaque predicates of the method to guard0/guard1 (refer part 1 of this blog for details)
What Is Code Virtualization
Relatively novel, code virtualization is possibly one of the most effective protection technique there is 1. With it come relatively heavy disadvantages, such as hampered speed of execution 2 and the difficulty to troubleshoot production code. The advantages are heightened reverse-engineering hurdles over other more traditional software protection techniques.
Virtualization in the context of code protection means:
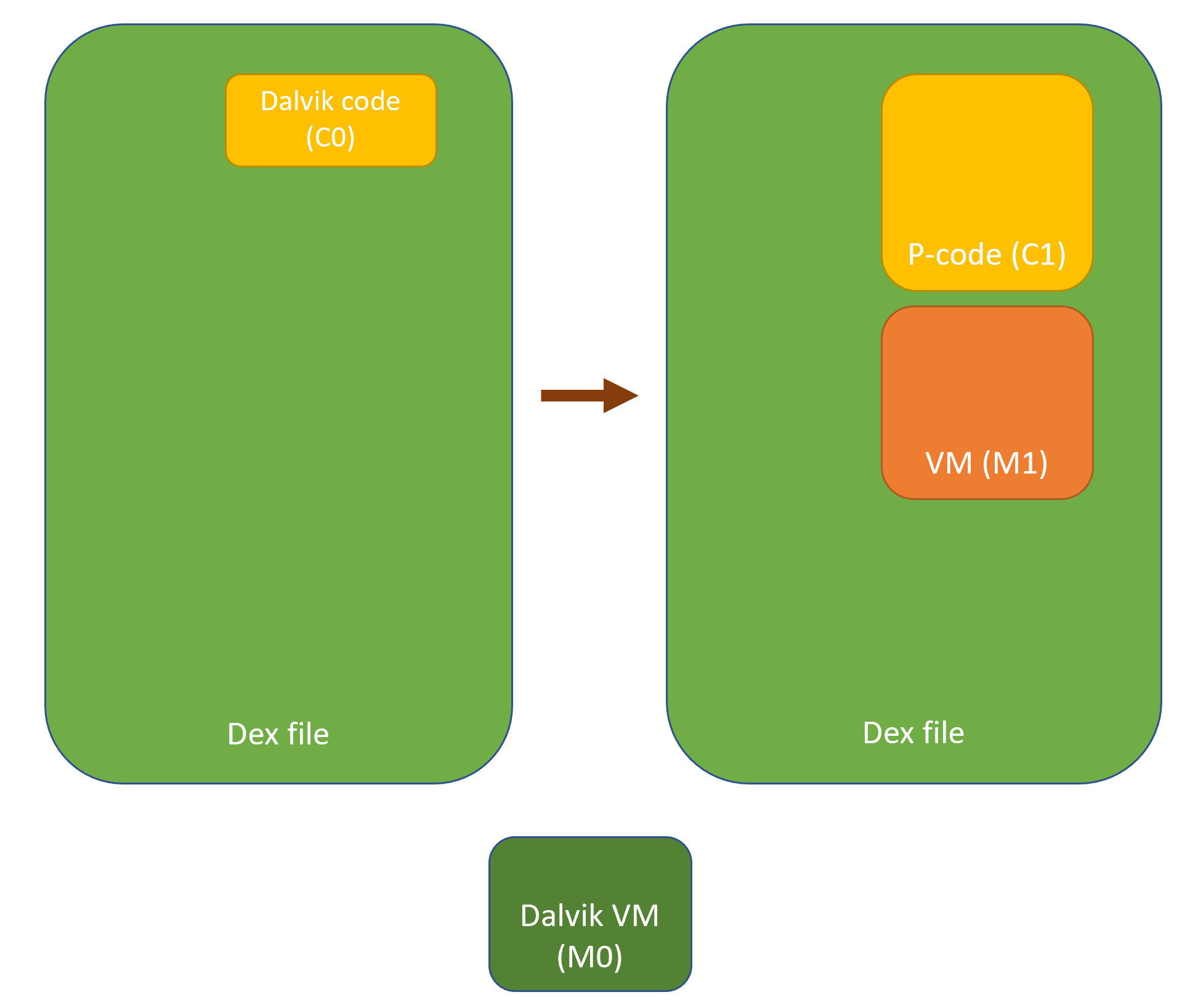
Generating a virtual machine M1
Translating an original code object C0 meant to be executed on a machine M03, into a semantically-equivalent code object C1, to be run on M1.
While the general features of M1 are likely to be fixed (e.g., all generations of M1 are stack machines with such and such characteristics), the Instruction Set Architecture (ISA) of M1 may not necessarily be. For example, opcodes, microcodes and their implementation may vary from generation to generation. As for C1, the characteristics of a generation are only constrained by the capabilities of the converter. Needless to say, standard obfuscation techniques can be applied on C1. The virtualization process can possibly be recursive (C1 could be a VM implementing the specifications of a machine M2, executing a code object C2, emulating the original behavior of C0, etc.).
All in all, in practice, this makes M1 and C1 unique and hard to reverse-engineer.
Before and after virtualization of a code object C0 into C1
Example of a Protected Method
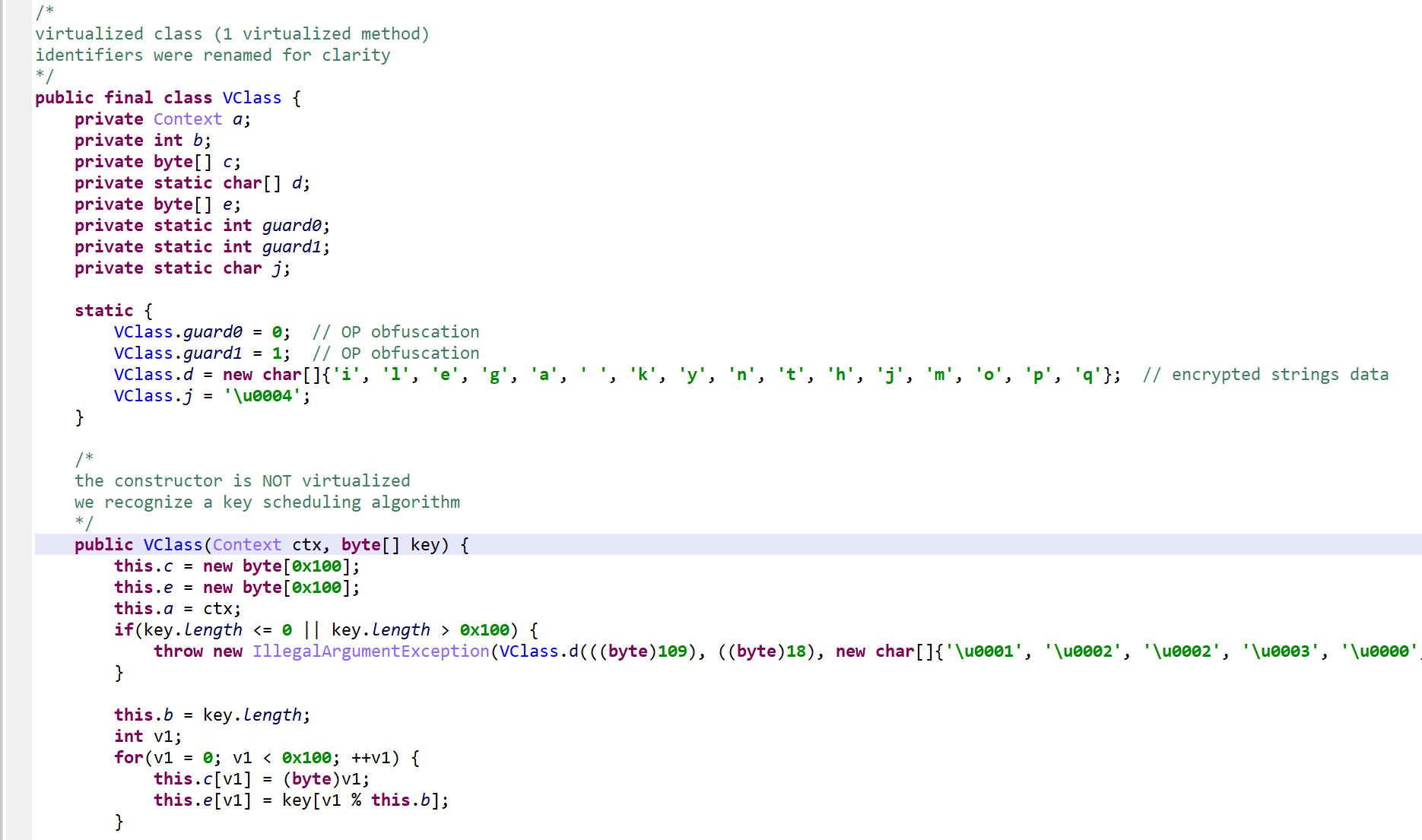
Note: all identifier names had been obfuscated. They were renamed for clarity and understanding.
Below, the class VClass was found to be “virtualized”. A virtualized class means that all non-constructor (all but <init>(*)V and <clinit>()V) methods were virtualized.
Interestingly, the constructors were not virtualized
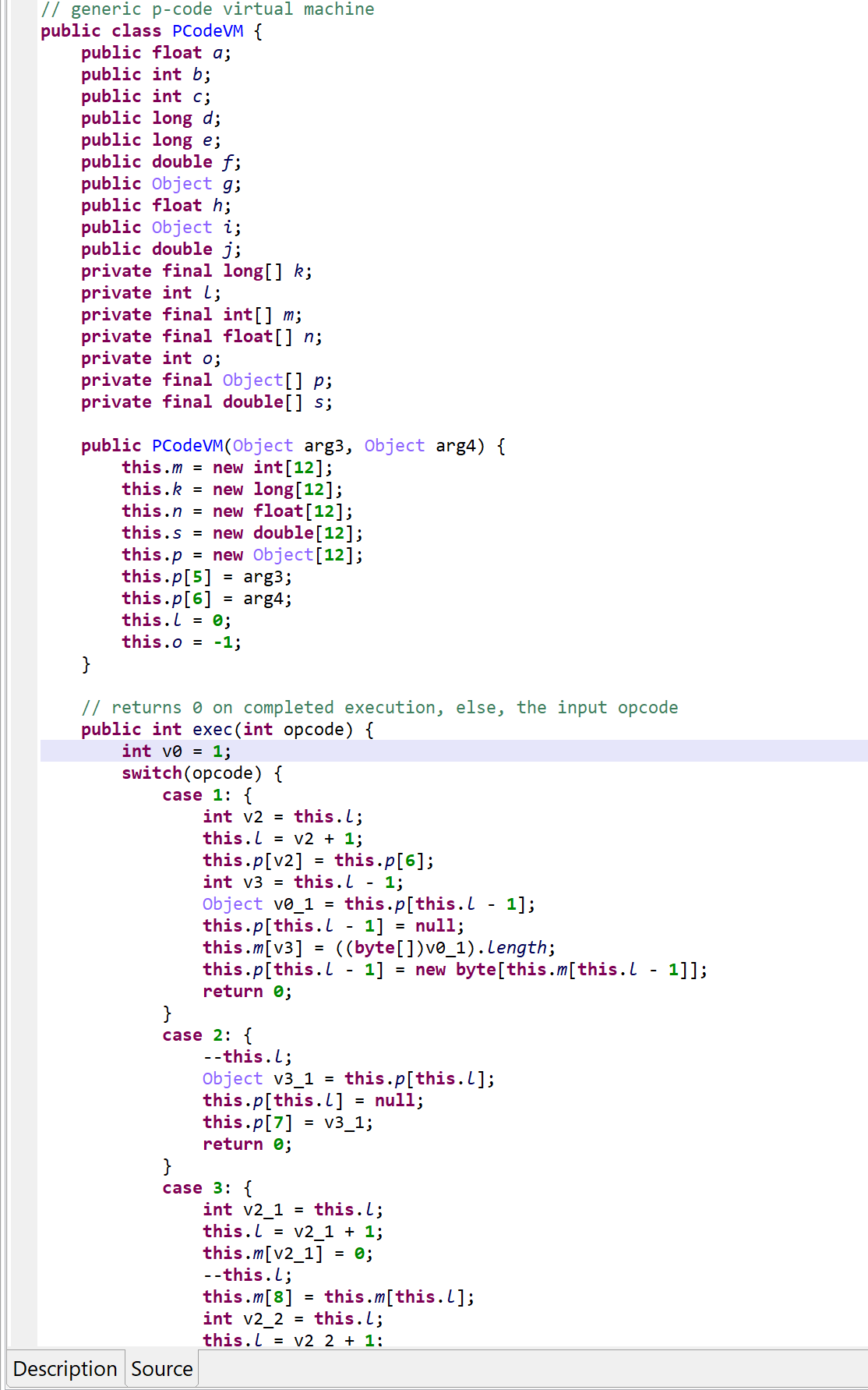
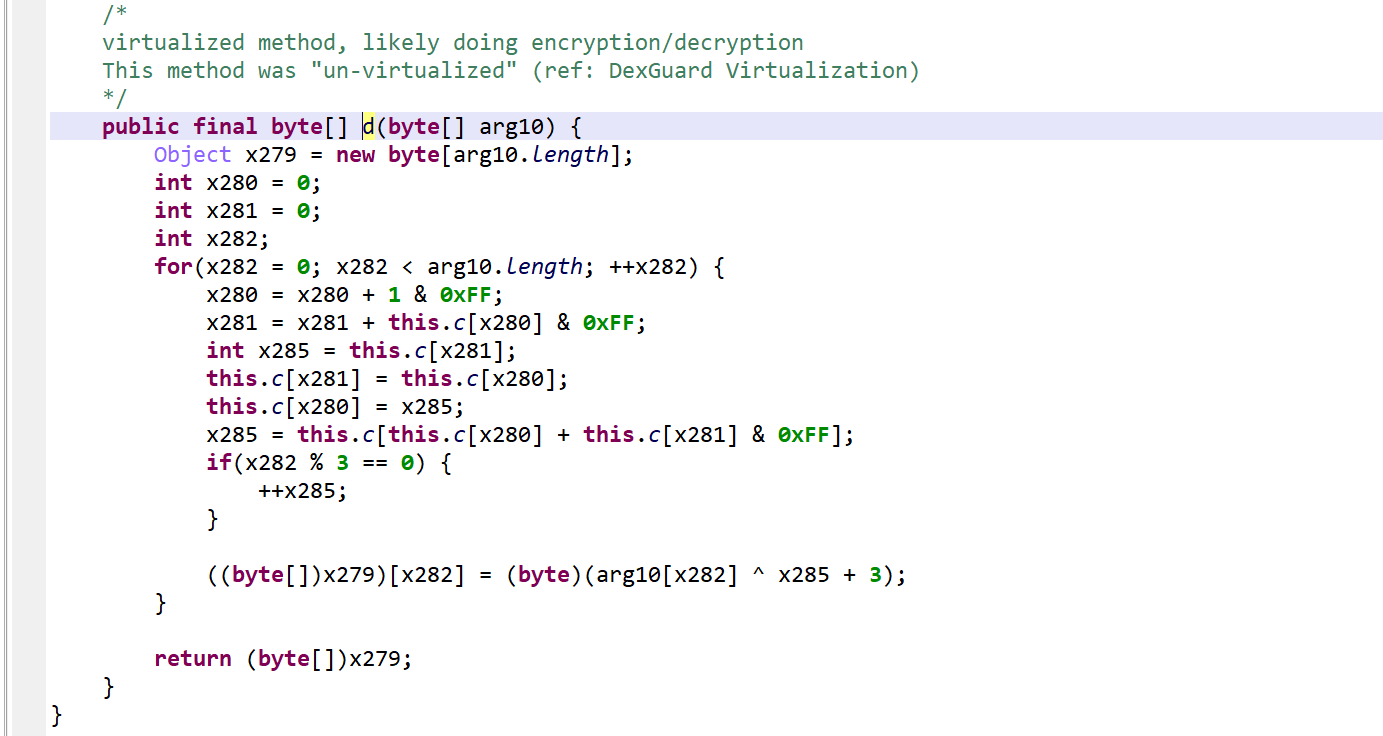
The method d(byte[])byte[] is virtualized:
It was converted into an interpreter loop over two large switch constructs that branch on pseudo-code entries stored in the local array pcode.
A PCodeVM class was added. It is a modified stack-based virtual machine (more below) that performs basic load/store operations, custom loads/stores, as well as some arithmetic, binary and logical operations.
Virtualized method. Note the pcode array. The opcode handlers are located in two switches. This picture shows the second switch, used to handle specific operations and API calls.
A snippet of the p-code VM class. Full code here, also contains the virtualized class.
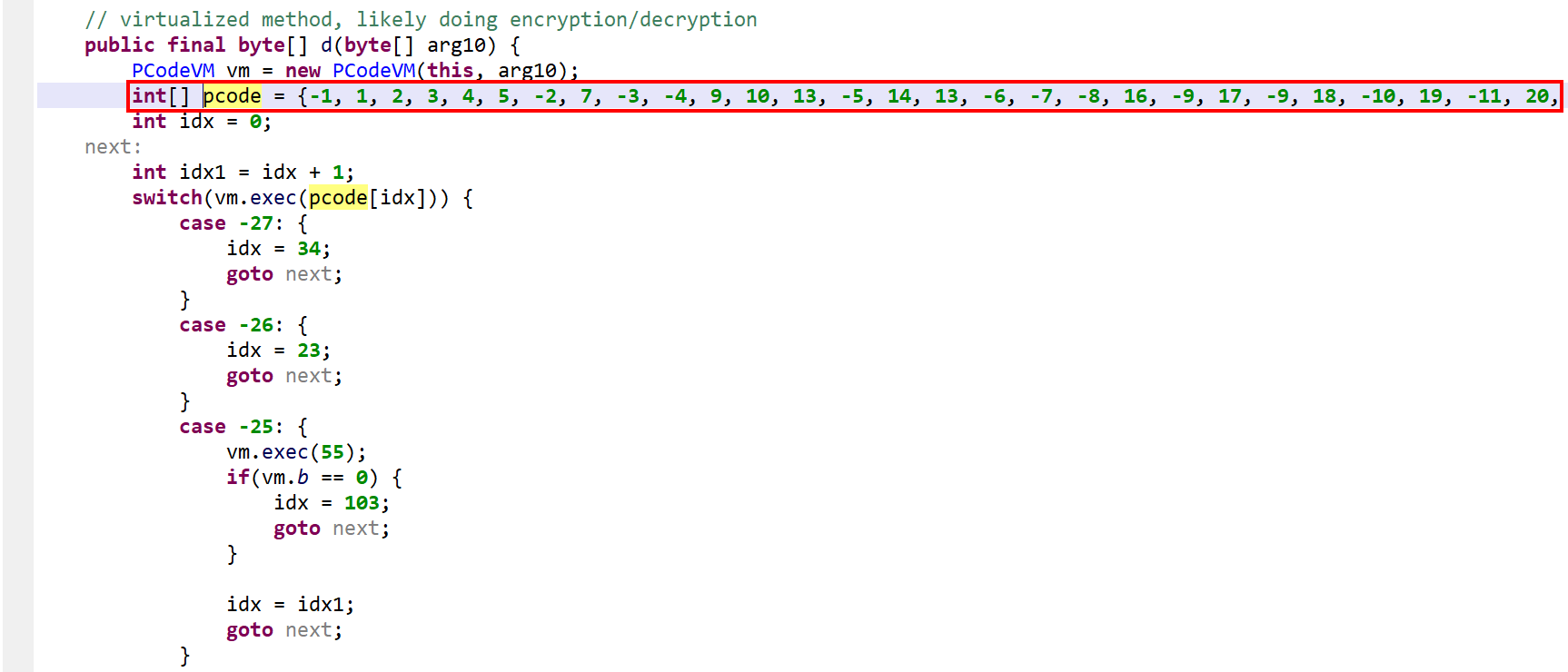
The generic interpreter is called via vm.exec(opcode). Execution falls back to a second switch entry, in the virtualized method, if the operation was not handled.
Please refer to the gist linked above for a full list of “generic” VM operations. Three examples, including one showing that the operations are not as generic as the term implies:
(specific to this VM) opcode 6, used to peek the most recently pushed object(specific to this VM) opcode 8, a push-int operation(specific to this VM) opcode 23 is relatively specialized, it implements an add-xor stack operation (pop, pop, push). It is quite interesting to see that the protection system does not simply generate one-to-one, dalvik-to-VM opcodes. Instead, the target routine is thoroughly analyzed, most likely lifted, high-level (compounded) arithmetic operations isolated, and pseudo-generic (in PCodeVM) or specialized (in the virtualized method) opcodes generated.
As said, negative opcodes represent custom operations specific to a virtualized method, including control flow changes. An example:
opcode -25: a if(a >=b) goto LABEL operation (first, call into opcode 55 to do a GE operation on the top two integers; then, use the result to do conditional branching)
Characteristics of the P-code VM
From the analysis of that code as well as virtualized methods found in other binaries, the characteristics of the p-code VM generated by the app protector can be inferred:
The VM is a hybrid stack machine that uses 5 parallel stacks of the same height, stored in arrays of:
java.lang.Object (accommodating all objects, including arrays)
int (accommodating all small integers, including boolean and char)
long
float
double
For each one of the 5 stack types above, the VM uses two additional registers for storing and loading
Two stack pointers are used: one indicates the stack TOP, the other one seems to be used more liberally, and is akin to a peek register
The stack has a reserved area to store the virtualized method parameters (including this if the method is non-static)
The ISA encoding is trivial: each instruction is exactly one-word long, it is the opcode of the p-code instruction to be executed. There is no concept of register, index, or immediate value embedded into the instruction, as most stack machine ISA’s have.
Because the ISA is so simple, the implementation of the semantics of an instruction falls almost entirely on the p-code handler. For this reason, they were grouped into two categories:
Semi-generic VM operations (load/store, arithmetic, binary, tests) are handled by the VM class and have a positive id. (A VM object is used by every virtualized method in a virtualized class.)
Operations specific to a given virtualized method (e.g., method invocations) use negative ids and are handled within the virtualized method itself.
While the PCodeVM opcodes are all “useful”, many specific opcodes of a virtualized method (negative ids) achieve nothing but the execution of code semantically equivalent to NOP or GOTO.
opcodes -2, -1: essentially branching instructions. A substantial amount of those can be found, including some branching to blocks with no other input but that source (i.e., an unnecessary GOTO – =spaghetti code -, or a NOP operation if the next block is the follow.)
Rebuilding Virtualized Methods
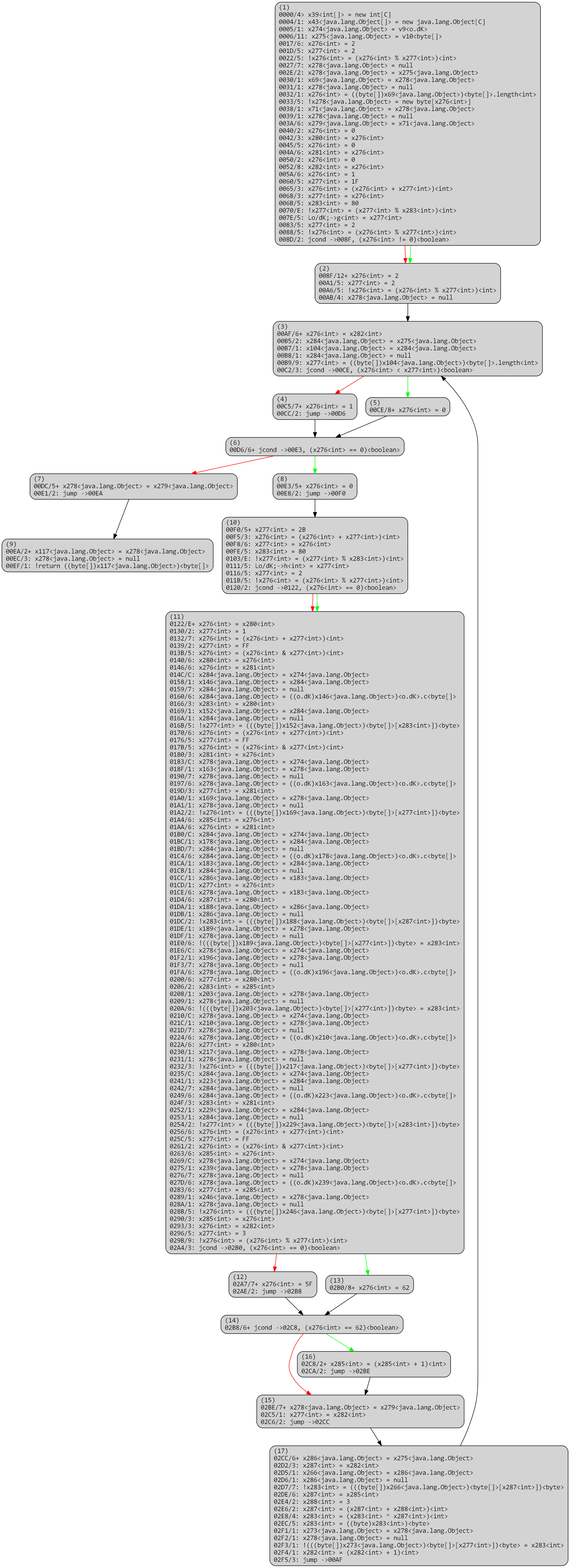
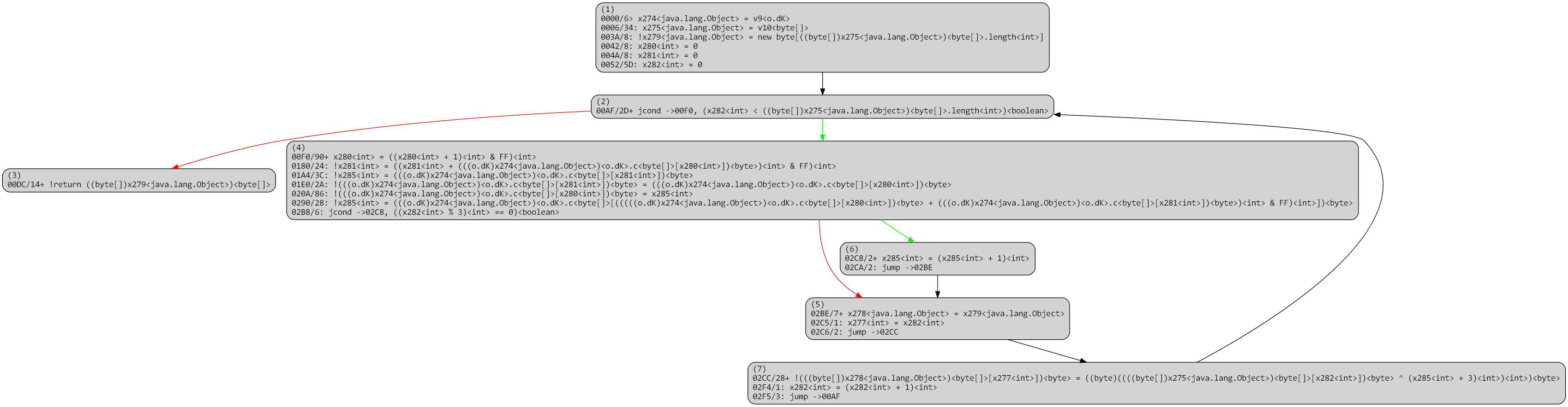
Below, we explain the process used to rebuild a virtualized method. The CFG’s presented are IR-CFG’s (Intermediate Representations) used by the dexdec4 pipeline. Note that unlike gendec‘s IR 5, dexdec‘s IR is not exposed publicly, but its textual representation is mostly self-explanatory.
Overall, a virtualized routine, once processed by dexdec like any other routine, looks like the following: A loop over p-code entries (stored in x8 below), processed by a() at 0xE first, or by the large routine switch.
Virtualized method, optimized, virtualized
The routine a() is PCodeVM.exec(), and its optimized IR boils down to a large single switch. 6
PCodeVM.exec()
The unvirtualizer needs to identify key items in order to get started, such as the p-code entries, identifiers used as indices into the p-code array, etc. Once they have been gathered, concolic execution of the virtualized routine becomes possible, and allows rebuilding a raw version of the original execution flow. Multiple caveats need to be taken care of, such as p-code inlining, branching, or flow termination. In its current state, the unvirtualizer disregards exceptional control flow.
Below, a raw version of the unflattened CFG. Note that all operations are stack-based; the code itself has not been modified at this point, it still consists of VM stack-based operations.
Virtualized method after unflattening, raw
dexdec’s standard IR optimization passes (dead-code removal, constant and variable propagation, folding, arithmetic simplification, flow simplifications, etc.) clean up the code substantially:
Virtualized method after unflattening and IR optimizations (opt1)
At this stage, all operations are stack-based. The high-level code generated from the above would be quite unwieldy and difficult to analyze, although substantially better than the original double-switch.
The next stage is to analyze stack-based operations to recover stack slots uses and convert them back to identifiers (which can be viewed as virtual registers; essentially, we realize the conversion of stack-based operations into register-based ones). Stack analysis can be done in a variety of ways, for example, using fixed-point analysis. Again, several caveats apply, and the need to properly identify stacks as well as their indices is crucial for this operations.
Virtualized method after unflattening, IR optimizations, VM stack analysis (opt2)
After another round of optimizations:
Virtualized method after unflattening, IR optimizations, VM stack analysis, IR optimizations (opt2_1)
Once the stack analysis is complete, we can replace stack slot accesses by identifier accesses.
Virtualized method after unflattening, IR optimizations, VM stack analysis, IR optimizations, virtual registers insertion (opt3)
After a round of optimizations:
Virtualized method after unflattening, IR optimizations, VM stack analysis, IR optimizations, virtual registers insertion, IR optimizations (opt3)
At this point, the “original” CFG is essentially reconstructed, and other advanced deobfuscation passes (e.g., emulated-based deobfuscators) can be applied.
The high-level code generation yields a clean, unvirtualized routine:
High-level code, unvirtualized, unmarked
After reversing, it appears to be a modified RC4 algorithm. Note the +3/+4 added to the key.
High-level code, unvirtualized, marked
Detecting Virtualized Methods
All versions of JEB detect virtualized methods and classes: run Global Analysis (GUI menu: Android) on your APK/DEX and look for those special events:
JEB Pro version 3.22 7 ships with the unvirtualizer module.
Tips:
Make sure to enable the Obfuscators, and enable Unvirtualization (enabled by default in the options).
The try-blocks analysis must be disabled for the class to unvirtualize. (Use MOD1+TAB to redecompile, untick “Parse Exception Blocks”).
After a first decompilation pass, it may be easier to identify guard0/guard1, rename, and recompile, else OP obfuscation will remain and make the code unnecessarily difficult to read. (Refer to part 1 of this series to learn about what renaming those fields to those special names means and does when a protected app is detected.)
Conclusion
We hope you enjoyed this third installment on code (un)virtualization.
There may be a fourth and final chapter to this series on native code protection. Until next time!
—
On a personal note, my first foray into VM-based protection dates back to 2009 with the analysis of Trojan.Clampi, a Windows malware protected with VMProtect ↩
Although one could argue that with current hardware (fast x64/ARM64 processors) and software (JIT’er and AOT compilers), that drawback may not be as relevant as it used to be. ↩
Machine here may be understood as physical machine or virtual machine ↩
Note the similarities with CFG flattened by chenxification and similar techniques. One key difference here is that the next block may be determined using the p-code array, instead of a key variable, updated after each operation. I.e., is the FSM – controlling what the next state (= the next basic block) is – embedded in the flattened code itself, or implemented as a p-code array. ↩
JEB Android and JEB demo builds do not ship the unvirtualizer module. I initially wrote this module as a proof-of-concept not intended for release, but eventually decided to offer it to our professional users who have legitimate (non malicious) use cases, e.g. code audits and black-box assessments. ↩
The second part of this series focuses on encryption:
Asset encryption
Class encryption
Full application encryption
Those analyses were done statically using JEB 3.21.
Asset Encryption
Assets can be encrypted, while combining other techniques, such as class encryption (seen in several high-profile apps), and bytecode obfuscation (control-flow obfuscation, string encryption, reflected API access). With most bytecode obfuscation being automatically cleaned up, Assets are being accessed in the following way:
Purple and cyan tokens represent auto-decrypted code. The assets decryptor method was renamed to ‘dec’, it provides a FilterInputStream that transparently decrypts contents.The DecryptorFilterStream (renamed) factory method
The DecryptorFilterStream object implements a variant of TEA (Tiny Encryption Algorithm), known for its simplicity of implementation and great performance 1.
Note the convoluted generation of Q_w, instead of hard-coding the immediate 0x9E37. Incidentally, a variant of that constant is also used by RC5 and RC6.read() decrypts and buffers 64 bits of data at a time. The decryption loop consists of a variable number of rounds, between 5 and 16. Note that Q_w is used as a multiplier instead of an offset, as TEA/XTEA normally does.
It seems reasonable to assume that the encryption and decryption algorithms may not always be the same as this one. This app protector making extensive use of polymorphism throughout its protection layers, it could be the case that during the protection phase, the encryption primitive is either user-selected or selected semi-randomly.
JEB can automatically emulate throughout this code and extract assets, and in fact, this is how encrypted classes, described in the next section, were extracted for analysis. However, this functionality is not present in current JEB Release builds. Since the vast majority of uses are legitimate, we thought that shipping one-click auto-decryptors for data and code at this time was unnecessary, and would jeopardize the app security of several high-profile vendors.
Class Encryption
Class encryption, as seen in multiple recent apps as well, works as follows:
The class to be protected, CP, is encrypted, compressed, and stored in a file within the app folder. (The filename is random and seems to be terminated by a dot, although that could easily change.) Once decrypted, the file is a JAR containing a DEX holding CP and related classes.
CL is also encrypted, compressed, and stored in a file within the app folder. Once decrypted, the file is a JAR containing a DEX holding the custom class loader CL.
Within the application, code using CP (that is, any client that loads CP, invokes CP methods, or accesses CP fields) is replaced by code using CM, a class manager responsible for extracting CP and CL, and loading CL. CM offers bridge methods to the clients of CP, in order to achieve the original functionality.
The following diagram summarizes this mechanism:
Class encryption mechanism
Since protected applications use the extensive RASP (Runtime Application Self-Protection) facility to validate the environment they’re running on, the dynamic retrieval of CL and CP may prove difficult. In this analysis, it was retrieved statically by JEB.
Below, some client code using CM to create an encrypted-class object CP and execute a method on it. Everything is done via reflection. Items were renamed for enhanced clarity.
Encrypted class loading and virtual method invocation
CM is a heavy class, highly obfuscated. The first step in understanding it is to:
disable rendering of catch-blocks that clutter the view.
With auto-decryption and auto-unreflection enabled, the result is quite readable. A few snippets follow:
Decrypted files are deleted after loading. On older devices, loading is done with DexFile; on newer devices, it is done using InMemoryDexClassLoader.In this case, the first encrypted JAR file (holding CL) is stored as “/e.”.In this case, the second encrypted JAR file (holding CP and related) is stored as “/f.”. The application held two additional couples, (“/a.”, “/b.”) and (“/c.”, “/d.”)
Once retrieved, those additional files can easily be “added” to the current DEX unit with IDexUnit.addDex() of your JEB project. Switch to the Terminal fragment, activate the Python interpreter (use py), and issue a command like:
Using Jython’s to add code to an existing DEX unitThe bnz class (CL) is a ClassLoader for the protected class (CP).
The protected class CP and other related classes, stored in “/f.” contained… anti-tampering verification code, which is part of the RASP facility! In other instances that were looked at, the protected classes contained: encrypted assets manager, custom code, API key maps, more RASP code, etc.
Full Application Encryption
“Full” encryption is taking class encryption to the extreme by encrypting almost all classes of an application. A custom Application object is generated, which simply overloads attachBaseContext(). On execution, the encrypted class manager will be called to decrypt and load the “original” application (all other protections still apply).
Custom application object used to provide full program encryption.
Note that activities can be encrypted as well. In the above case, the main activity is part of the encrypted jar.
Conclusion
That’s it for part 2. We focused on the encryption features. Both offer relatively limited protection for reverse-engineers willing to go the extra mile to retrieve original assets and bytecodes.
In Part 3, we will present what I think is the most interesting feature of this protector, code virtualization.
Until next time!
—
The TEA encryption family is used by many win32 packers ↩