JEB 5.31 ships with a generic SASS disassembler and experimental decompiler for GPU code compiled for Nvidia architectures Volta to Blackwell, that is, compute capabilities sm_70 to sm_121.
What is SASS Code
SASS 1 is the low-level, semi-documented machine code generated when compiling high-level CUDA 2 source code (C++ or higher-level languages) with nvcc or when translating PTX 3 intermediate code with ptxas.
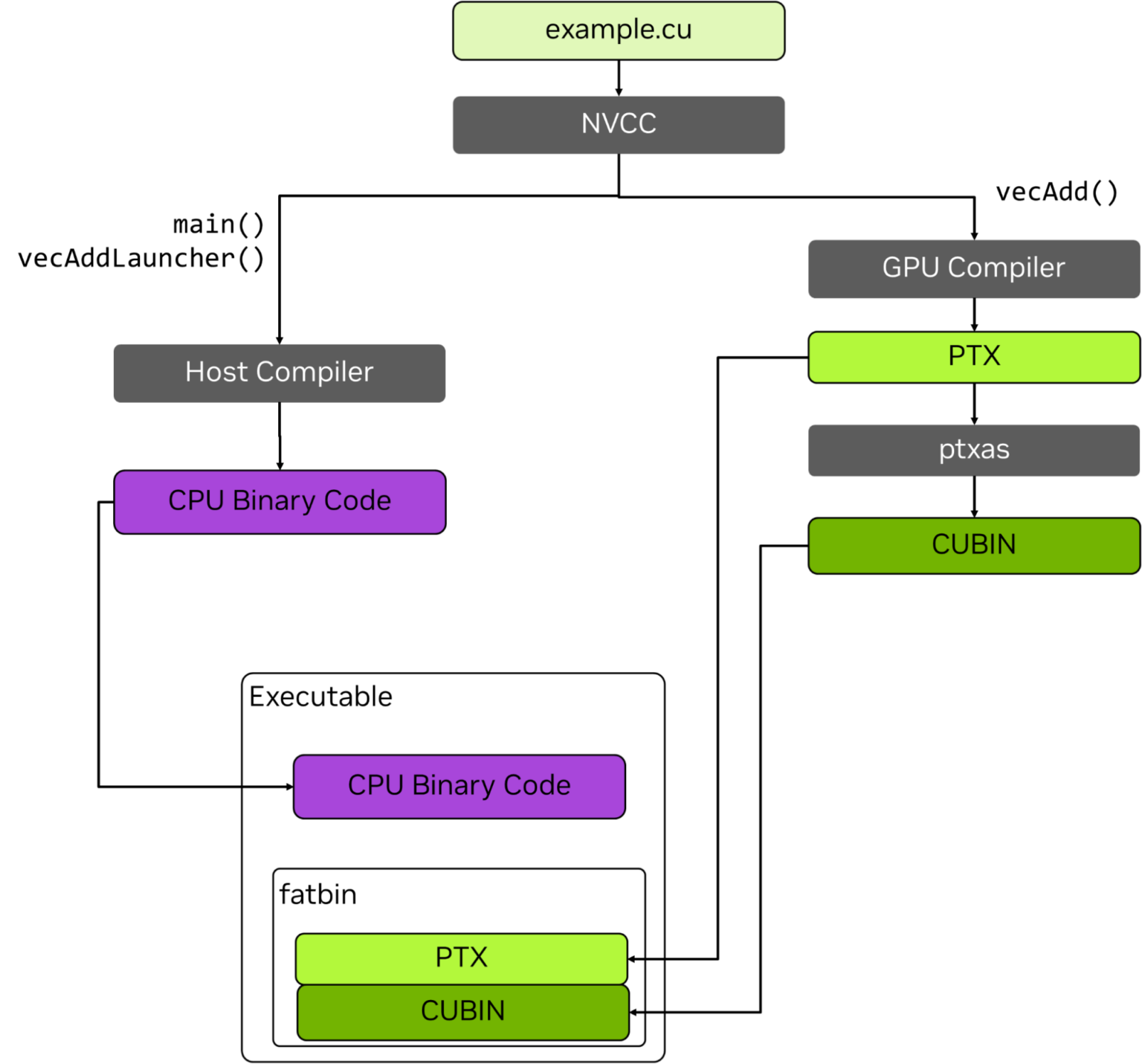
A simplified view of the compilation steps can be seen as follows:CUDA code (C/C++, etc.) => PTX IR (~LLVM bitcode) => SASS (assembly)
Practically, GPU code is embedded in an ELF container referred to as a cubin, for “CUDA binary”. One or more cubins are embedded in a host program to be executed on a CPU. When GPU code needs to be run, the host will retrieve the appropriate cubin and ask the GPU to load and execute it. The complete build process of some high-level example.cu file mixing general-purpose code and GPU code is as follows:
SASS Primer
Readers familiar with CUDA may not know about SASS or the details of the environment in which GPU code is executed. This section is a primer that will help make the remainder of this page more readable. If you are familiar with PTX and/or SASS, you may want to skip to the next section about disassembling code.
Execution Environment
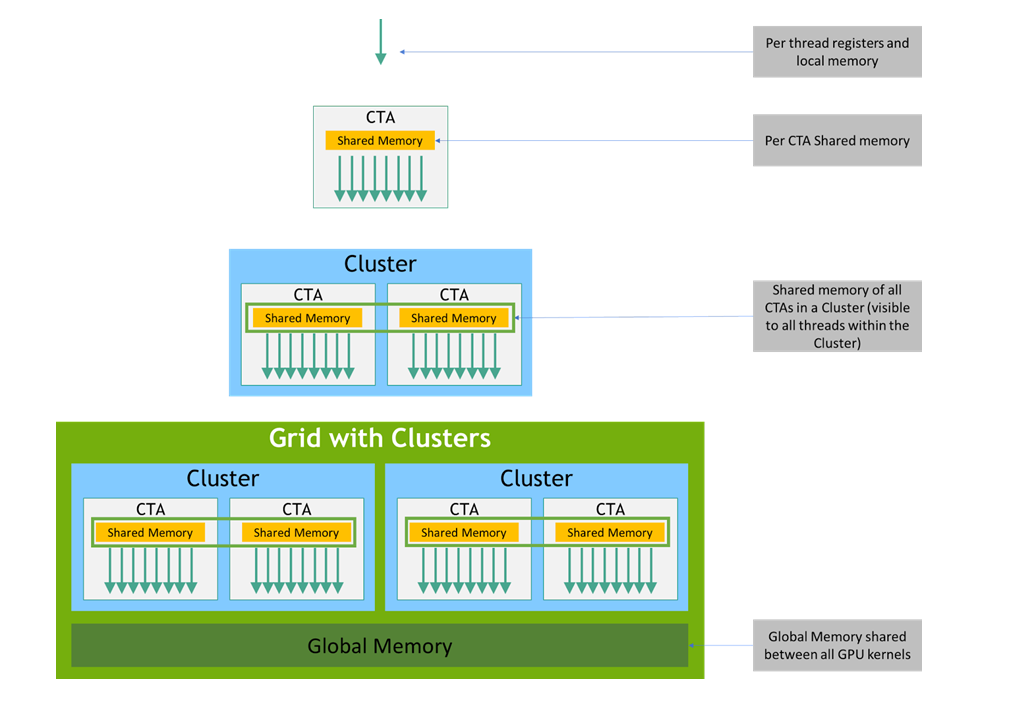
Concisely, the basic environment for execution of a GPU kernel K can be described as:
- K is executed on a streaming multiprocessor (SM).
- Threads for K are organized into warps. Each warp contains 32 threads executed in lockstep at the instruction-issue level (if the PC of a thread differs because of a branching instruction, divergence is handled by masking inactive threads until a reconvergence point.)
- Warps are grouped into Cooperative Thread Arrays (CTAs), also called thread blocks, each containing up to 1024 threads.
- Starting with Hopper, CTAs can be grouped into clusters.
- The full set of CTAs or clusters forms the compute grid for K.
Data Spaces
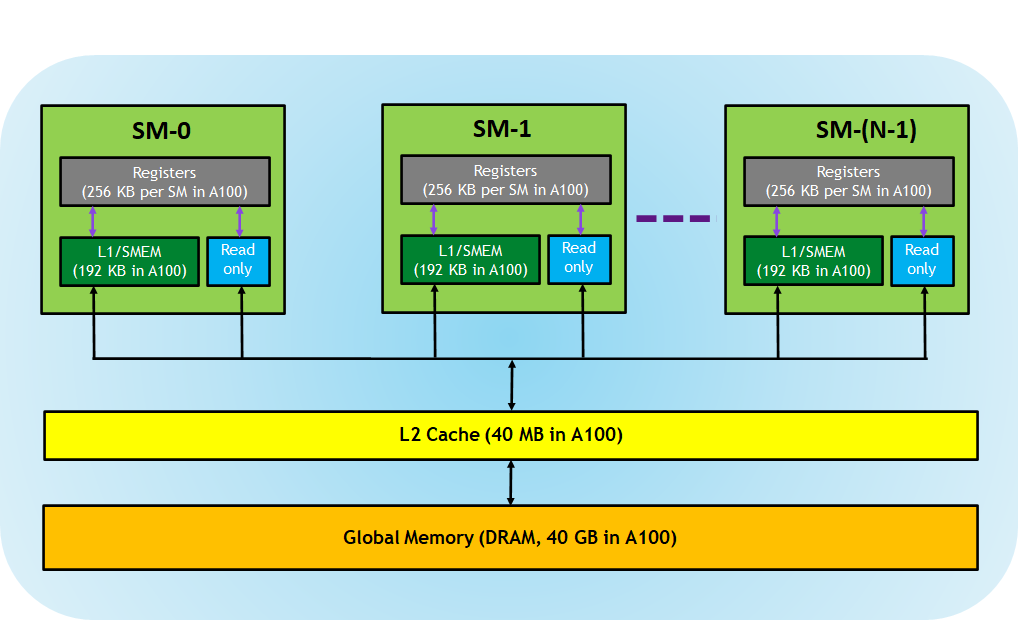
A kernel’s code can access several data spaces:
- Registers: per-thread, detailed in the following sub-section
- Local Memory: per-thread, in DRAM, accessed with LDL/STL
- Shared Memory: per-CTA, on-chip, accessed via LDS/STS
- Global Memory: global, in DRAM, accessed via LDG/STG
- Constant Memory: in DRAM, cached, accessed via LDC/ULDC
- Texture Memory: global, in DRAM, accessed via TLD/TSD
Registers
Let’s see what registers are available to a thread:
- General Registers (Rx): up to 256 32-bit registers; 64-bit values are represented by two contiguous registers; R255 is a zero-register (aliased RZ)
- Predicate Registers (Px): 8 boolean flags per thread; P7 is always true (aliased PT)
- Special Registers (SRx): 256 read-only registers, containing thread/block IDs, lane ID, clock values, performance counters, etc; most are 32-bit, some are 64-bit. 4
Uniform registers were added on Turing and above (sm_75+). Their values are the same for all threads of a warp:
- Uniform Registers (URx): 64 32-bit registers (increased to 256 registers on sm_100+); the last one in the bank is a zero-register (aliased URZ)
- Uniform Predicate Registers (UPx): 8 boolean flags; UP7 is always true (aliased UPT)
Classes of Instructions
SASS instructions can be grouped into high-level classes, also corresponding to different execution pipelines. A few examples:
- Integer: IMAD, IADD3, SHF, LOP3 (arbitrary 3-input bitwise operation backed by a look-up table)
- Floating-point: FADD, FFMA, FSET, F2F/F2I/I2F (conversion instructions), MUFU (multi-usage function, for sin, cos, reverse square-root, etc.)
- Load/Store: LDx/ STx for each memory space
- Control flow: BRA, BRX, CALL, RET, SSY, BSYNC, EXIT
- Uniform ops: many equivalent instructions prefixed by U will work on uniform registers, e.g. UIADD3, UIMAD, ULEA
Refer to this Nvidia documentation page for a brief description of the instruction classes as well as the instructions themselves. For convenience in JEB, the description of an instruction’s opcode will also be displayed when hovering over its mnemonic.
Finally, let’s note that:
- About the encoding: all Volta+ instructions are fixed size, 16-byte long.
- Most instructions have 1 to 4 operands; the destination operands go first, followed by the source operands. 5
- The opcode and operands can contain optional attributes and qualifiers that modify how the instruction behave (e.g. “.64” will specify a 64-bit operation on a pair of registers).
- All instructions can be predicated.
Example:@!P0 IMAD R0, R1, R2, R3
means: “perform R0=R1*R2+R3 if P0 is false“
Disassembling Volta+ Code
The JEB disassembler plugin can handle SASS code embedded in cubin files. They are ELF containers using the EM_CUDA (190) machine type. As for any JEB disassembler plugin, it can be used on standalone binary blobs as well.
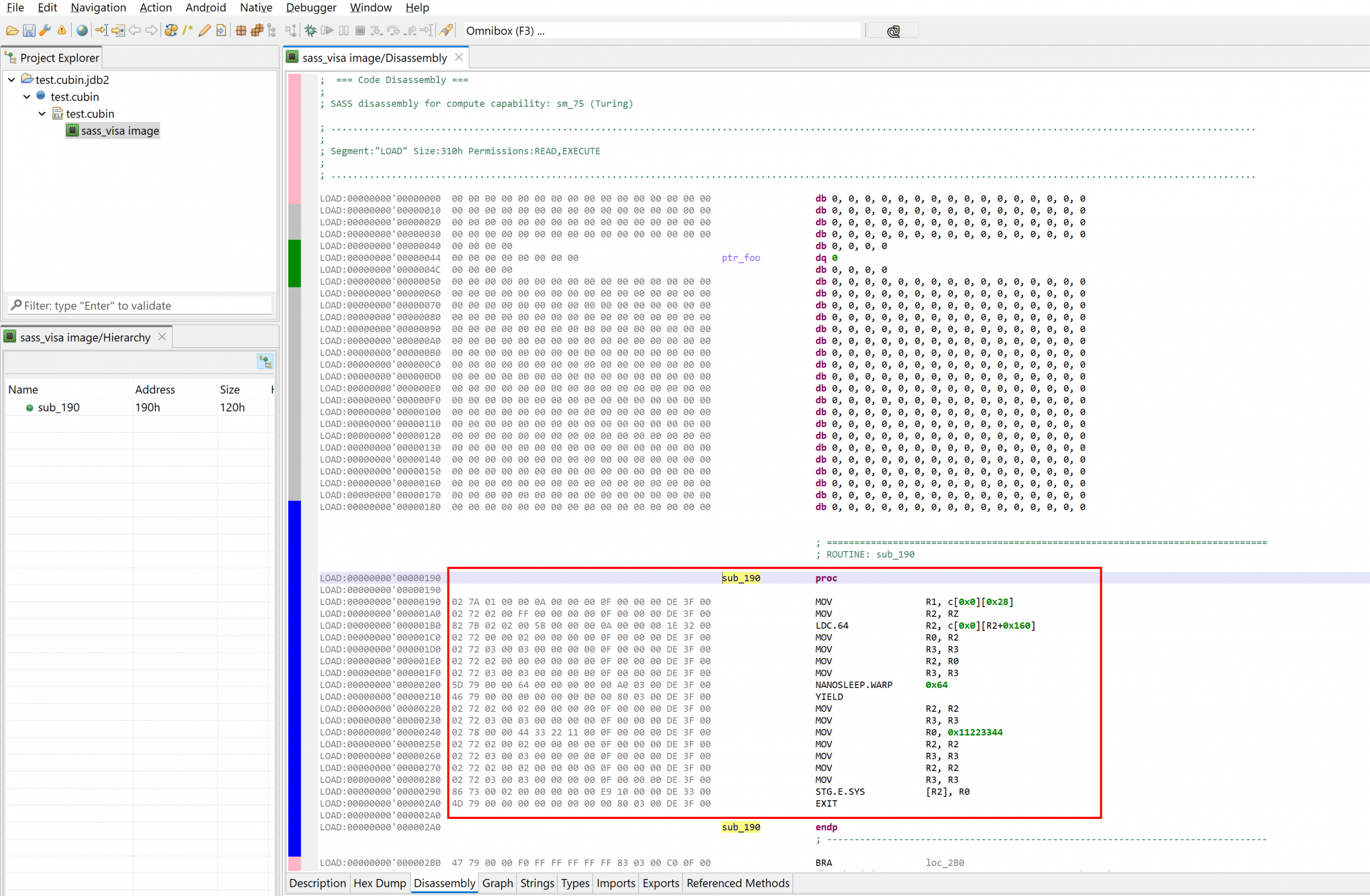
The disassembler uses the type name sass_visa, to mean “SASS Volta+ ISA”.
Pre-Volta (before sm_70) code is not supported by this plugin.
Two current limitations in terms of processing ELF CUDA files:
– The relocations are not supported and not applied.
– Relocatable files (ET_REL) are not supported at the moment (only executables and .so libs are processed)
Rendering
The disassembler offers an array of rendering options not provided by the official CUDA toolkit’s cuobjdump and nvdisasm tools. On top of the usual options common to all JEB disassembler plugins, the following additional options can be enabled (right-click, Rendering Options).
.DisplayImplicitDescriptors
This option is enabled by default on GUI clients (its default is false for headless clients, e.g. when scripting). If enabled, the implicit descriptor used to access memory will be displayed to avoid any ambiguity. Example:
Instruction bytes: 81 79 06 02 04 00 00 00 00 11 1E 0C 00 68 01 00
Standard rendering: LDG.E.U8 R6, [R2.64]
Rendering with desc: LDG.E.U8 R6, desc[UR4][R2.64]
.DisplayRegisterNumbers
If enabled, the disassembly will use number-based register names instead of their aliases (e.g. P7 instead of PT). Examples:
- R255: Register #255 is always zero and aliased RZ
- P7: Predicate Register #7 is always true and aliased PT
- SR0: Special Register #0 is the lane id and aliased SR_LANEID
- On architectures sm_75 to sm_90, the last (63rd) uniform register UR63 is always zero and aliased as URZ
- etc.
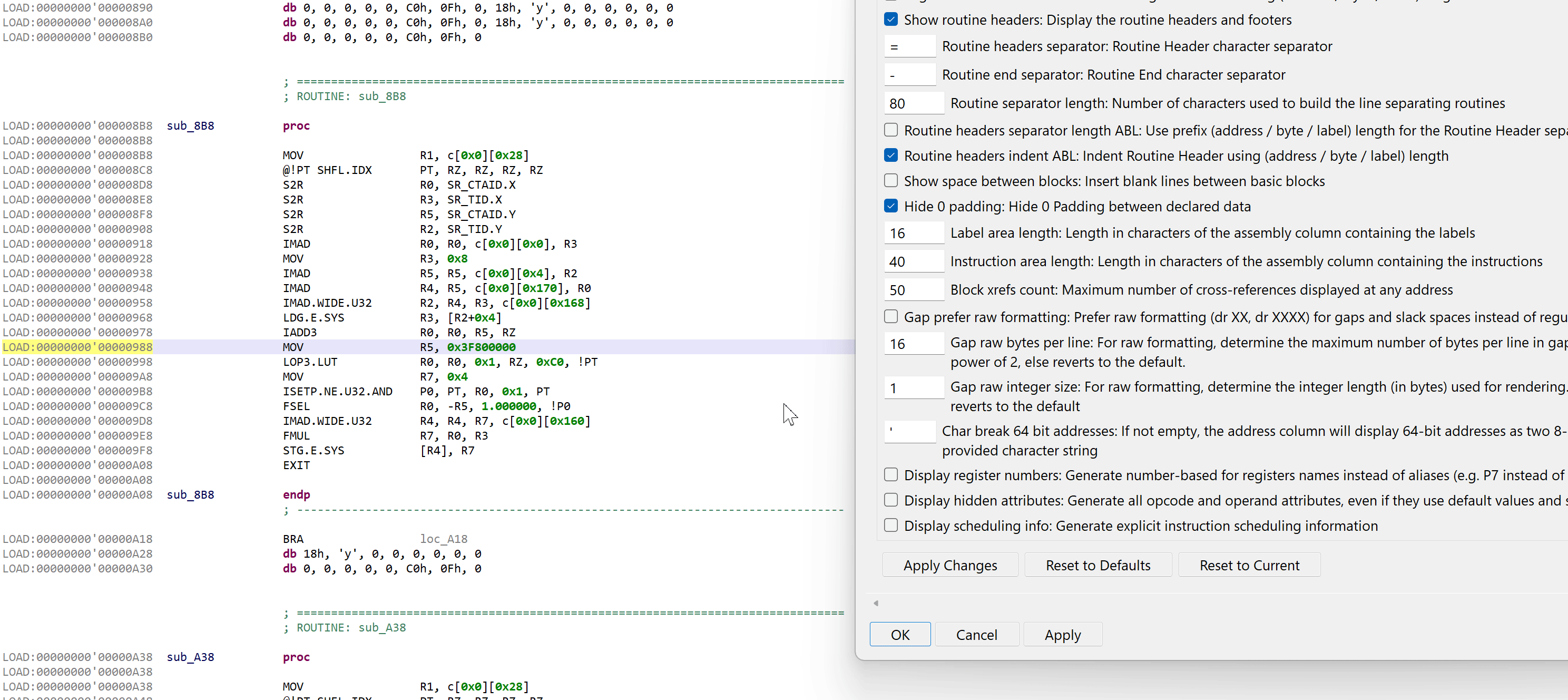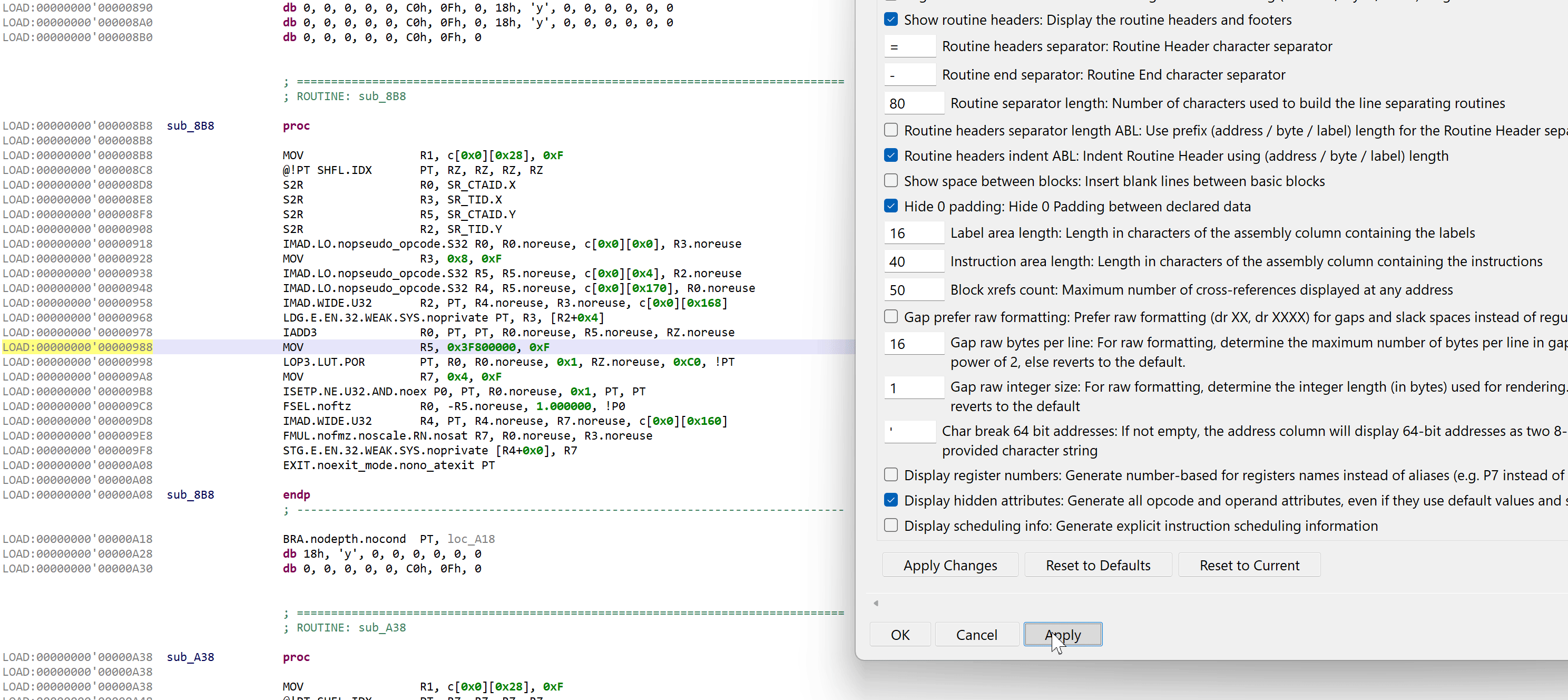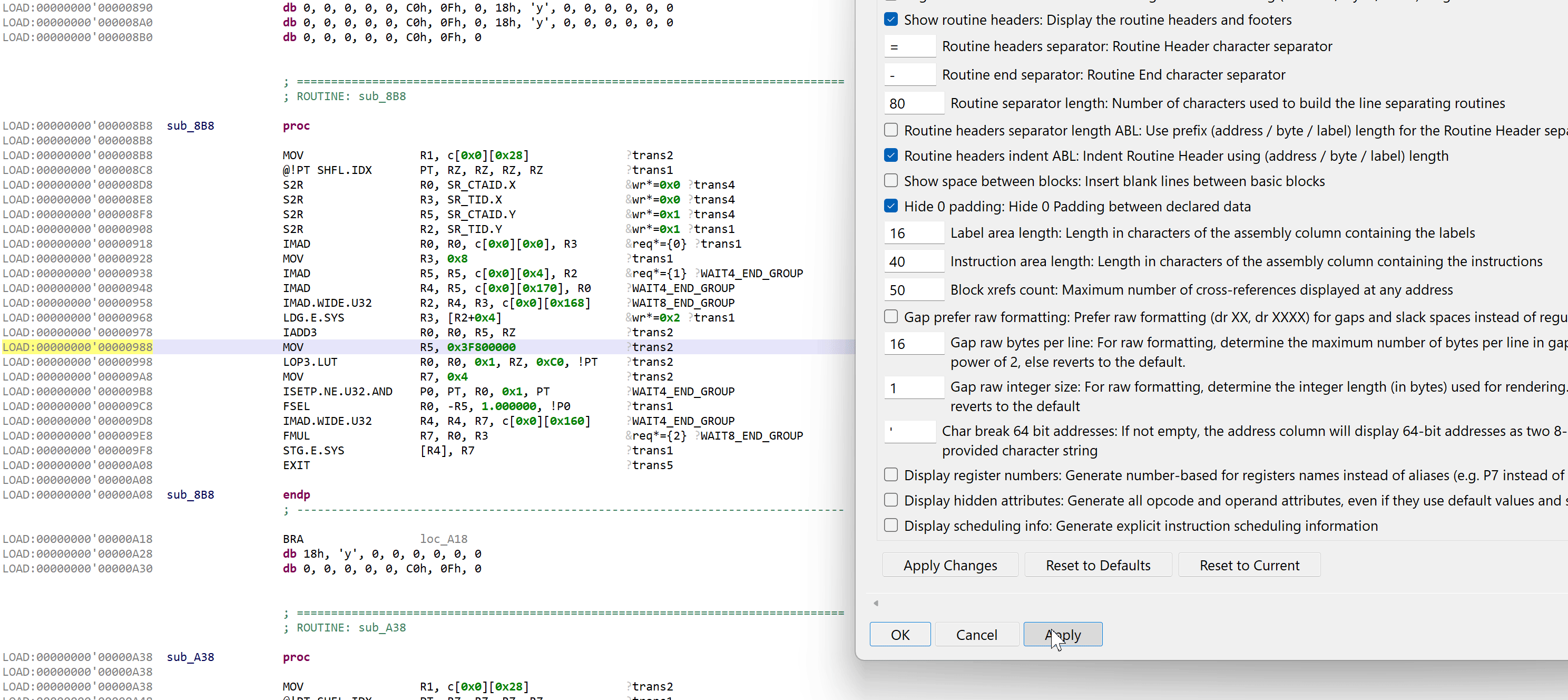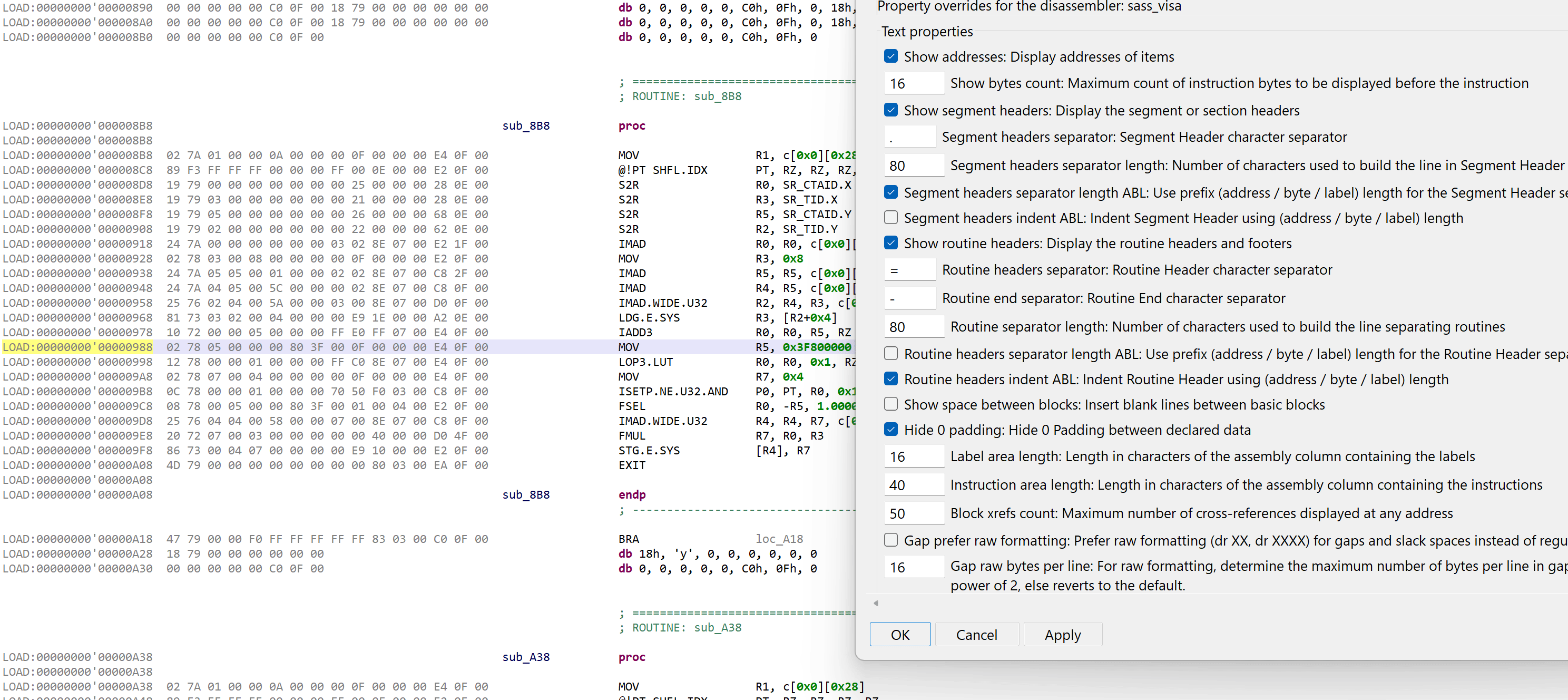
.DisplayHiddenAttributes
If enabled, opcode attributes, operands, and operand attributes that use default value will be explicitly rendered. Examples:
- Instruction bytes:
10 72 00 00 05 00 00 00 FF E0 FF 07 00 E4 0F 00
Standard rendering:IADD3 R0, R0, R5, RZ
Full rendering:IADD3 R0, PT, PT, R0.noreuse, R5.noreuse, RZ.noreuse - Instruction bytes:
81 73 03 02 00 04 00 00 00 E9 1E 00 00 A2 0E 00
Standard rendering:LDG.E.SYS R3, [R2+0x4]
Full rendering:LDG.E.EN.32.WEAK.SYS.noprivate PT, R3, [R2+0x4]
.DisplaySchedulingInfo
If enabled, extra scheduling information is explicitly generated and appended to the instruction. Examples:
IMAD R5, R5, c[0x0][0x4], R2 &req*={1} ?WAIT4_END_GROUPMOV R3, 0x8 ?trans1
Note that we do not provide instruction timing information (such as hardware-enforced latency to avoid data hazards) at this point, although it is likely we will add that as a rendering option in a future update.
Code analysis
The code analyzer breaks down the SASS code and rebuilds control flow. When doing so, internal __device__ sub-routines that were not inlined are recovered and displayed in the code hierarchy.
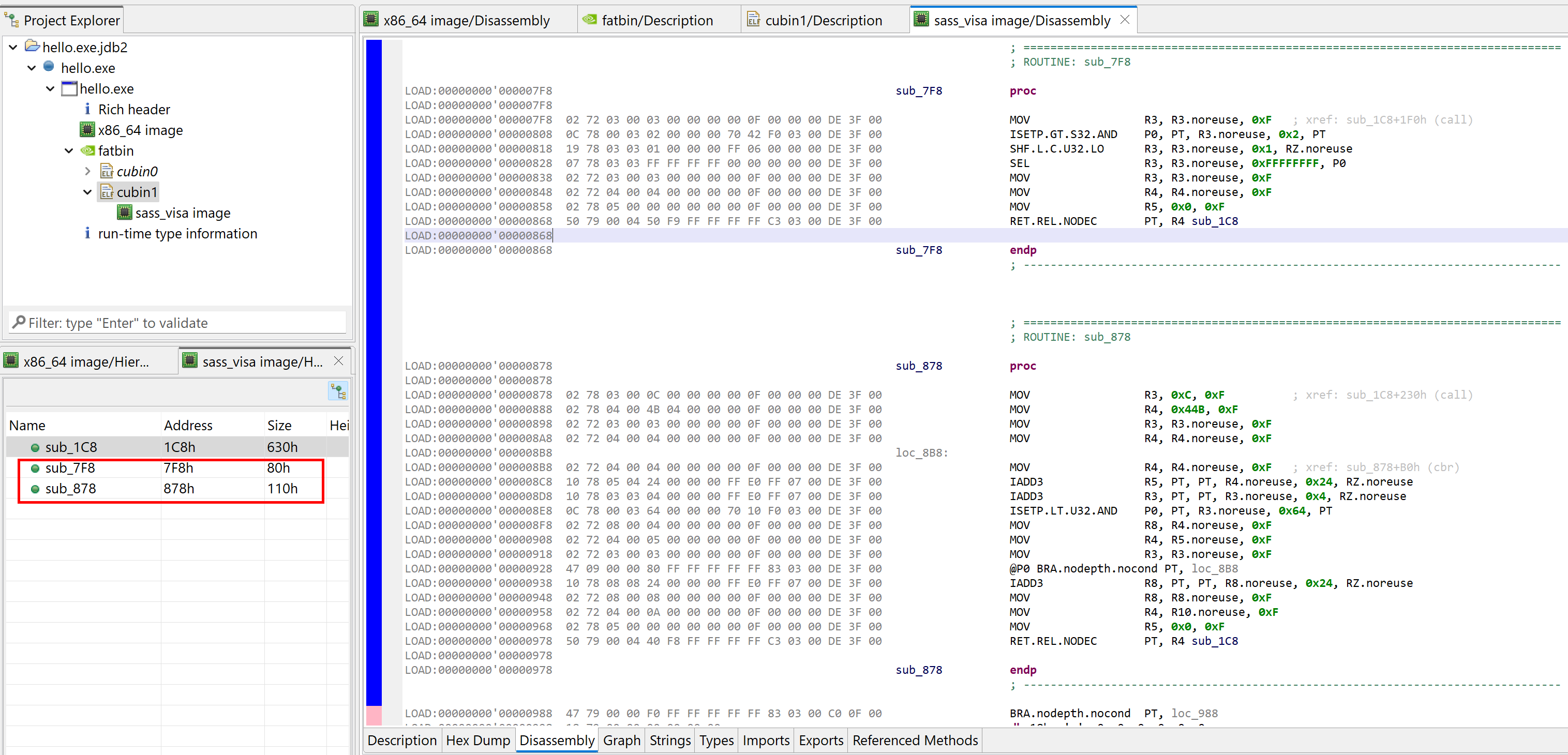
Per usual with code units in JEB, the disassembly listing can be annotated (e.g. comments: hotkey /), methods can be renamed (hotkey N), code can be navigated (e.g. cross-references: hotkey X), etc. All those actions are located in the Action and Native menus. 6
Extracting cubins
A secondary plugin retrieves and extract cubins from host executable files (ELF, PE, etc.). Extraction works on a best-effort basis, as the file format is not officially documented by Nvidia.
In the screenshot below, we opened the oceanFFT demo program shipping with the CUDA toolkit. A fatbin was retrieved, containing 17 cubins, as can be seen in the Project Explorer panel. The fatbin’s Description fragment provides more details:
- Type of fatbin code (SASS or PTX)
- Flags (e.g. whether the fatbin payload was compresed)
- The intended architecture
Individual cubin units are created and can be opened to analyze and annotate the code, as was shown in the previous section.
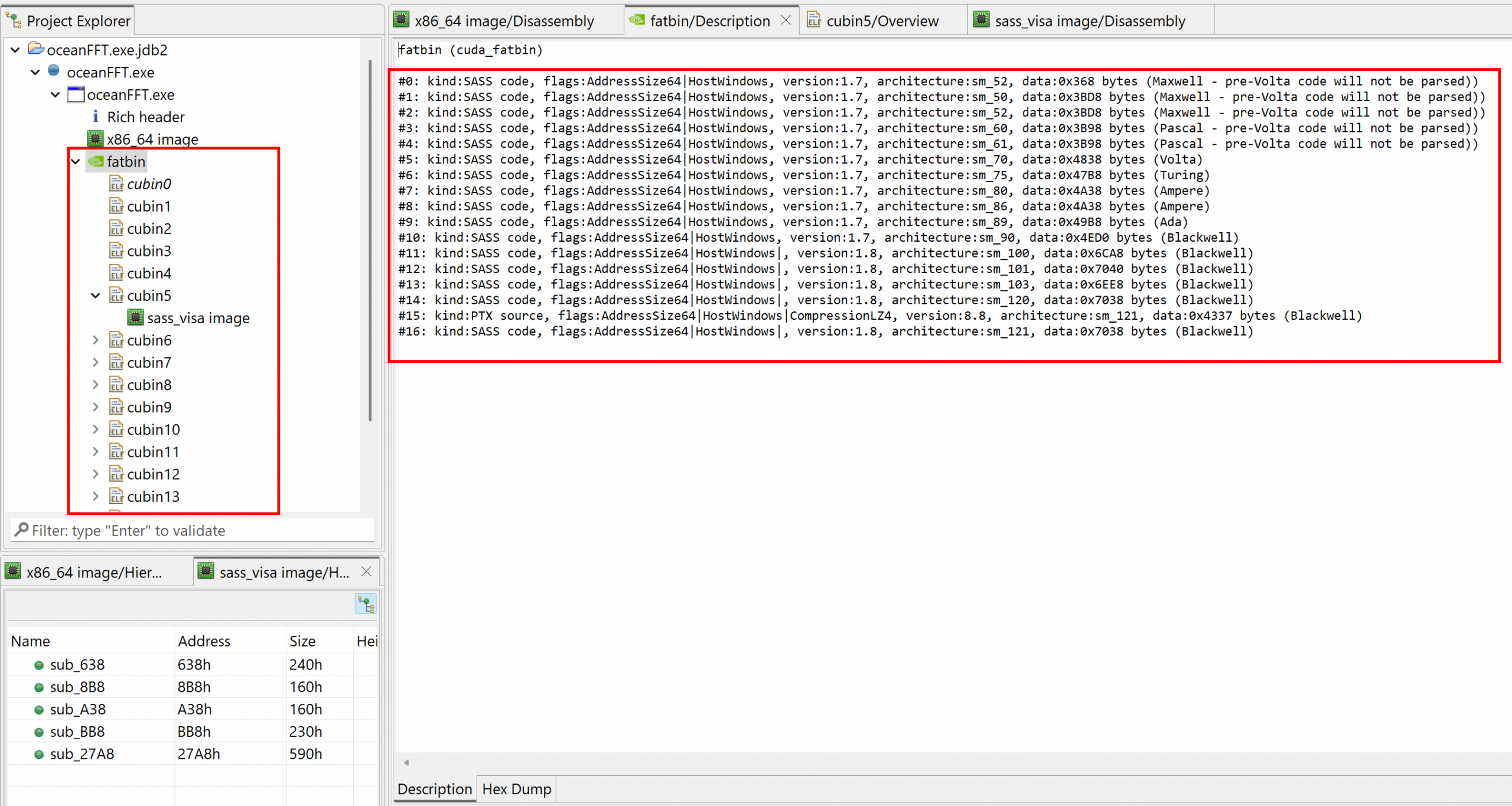
fatbin (cuda_fatbin)
#0: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_52, data:0x368 bytes (Maxwell - pre-Volta code will not be parsed))
#1: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_50, data:0x3BD8 bytes (Maxwell - pre-Volta code will not be parsed))
#2: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_52, data:0x3BD8 bytes (Maxwell - pre-Volta code will not be parsed))
#3: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_60, data:0x3B98 bytes (Pascal - pre-Volta code will not be parsed))
#4: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_61, data:0x3B98 bytes (Pascal - pre-Volta code will not be parsed))
#5: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_70, data:0x4838 bytes (Volta)
#6: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_75, data:0x47B8 bytes (Turing)
#7: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_80, data:0x4A38 bytes (Ampere)
#8: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_86, data:0x4A38 bytes (Ampere)
#9: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_89, data:0x49B8 bytes (Ada)
#10: kind:SASS code, flags:AddressSize64|HostWindows, version:1.7, architecture:sm_90, data:0x4ED0 bytes (Blackwell)
#11: kind:SASS code, flags:AddressSize64|HostWindows|0x1000000, version:1.8, architecture:sm_100, data:0x6CA8 bytes (Blackwell)
#12: kind:SASS code, flags:AddressSize64|HostWindows|0x1000000, version:1.8, architecture:sm_101, data:0x7040 bytes (Blackwell)
#13: kind:SASS code, flags:AddressSize64|HostWindows|0x1000000, version:1.8, architecture:sm_103, data:0x6EE8 bytes (Blackwell)
#14: kind:SASS code, flags:AddressSize64|HostWindows|0x1000000, version:1.8, architecture:sm_120, data:0x7038 bytes (Blackwell)
#15: kind:PTX source, flags:AddressSize64|HostWindows|CompressionLZ4, version:8.8, architecture:sm_121, data:0x4337 bytes (Blackwell)
#16: kind:SASS code, flags:AddressSize64|HostWindows|0x1000000, version:1.8, architecture:sm_121, data:0x7038 bytes (Blackwell)
Decompiling SASS to pseudo-C
This JEB release also includes an experimental/proof-of-concept decompiler plugin for SASS code. It will generate pseudo C code with many caveats, as described in the current section.
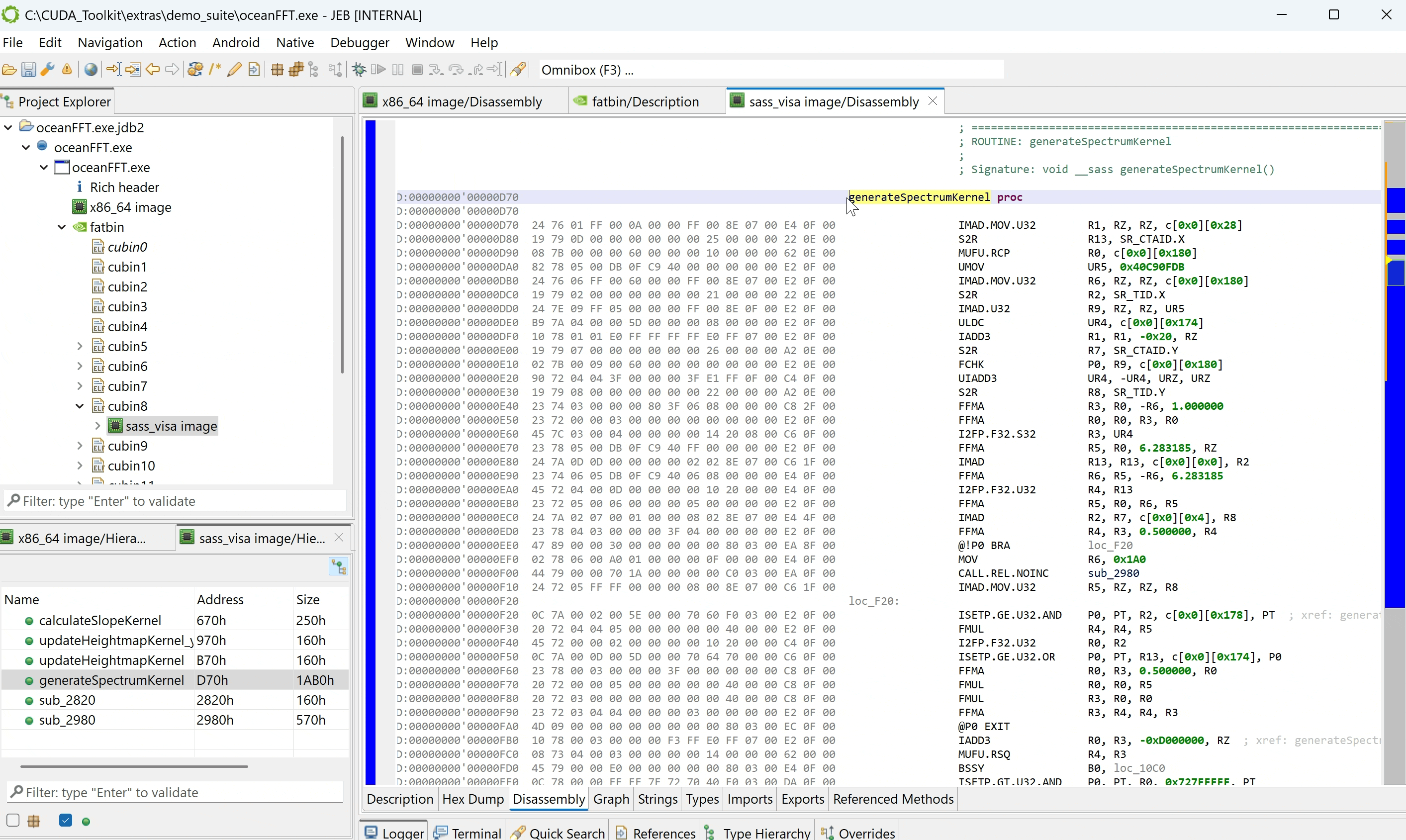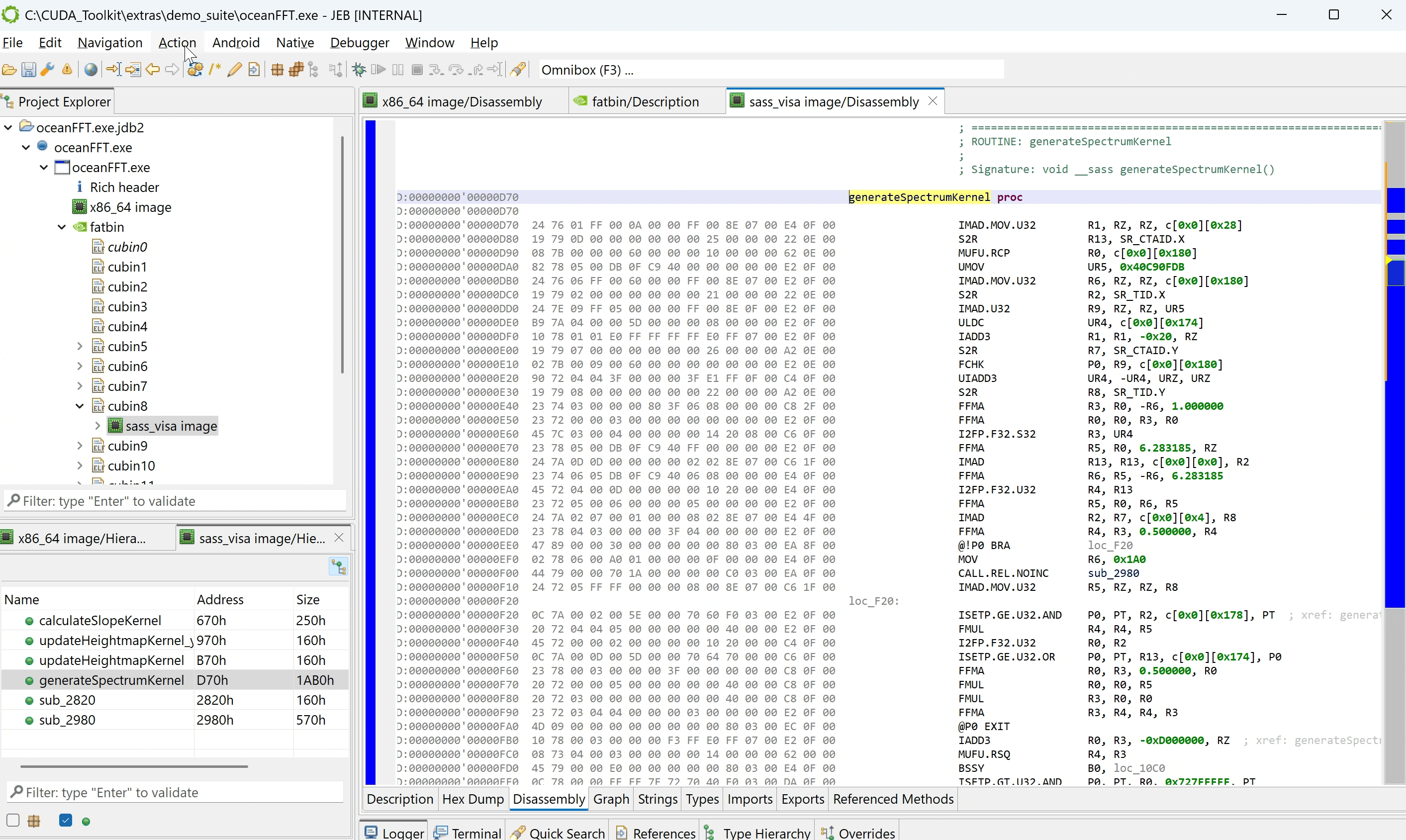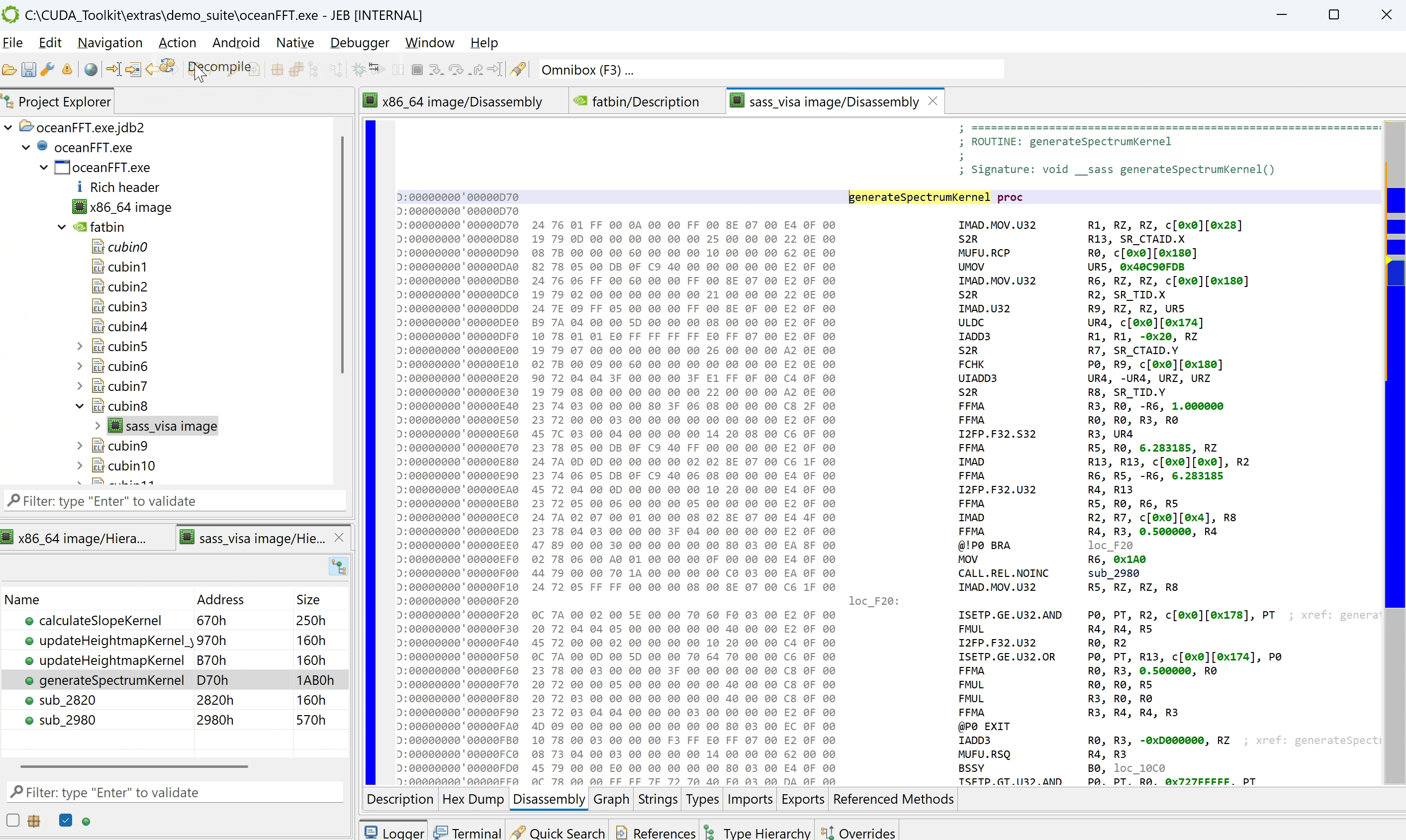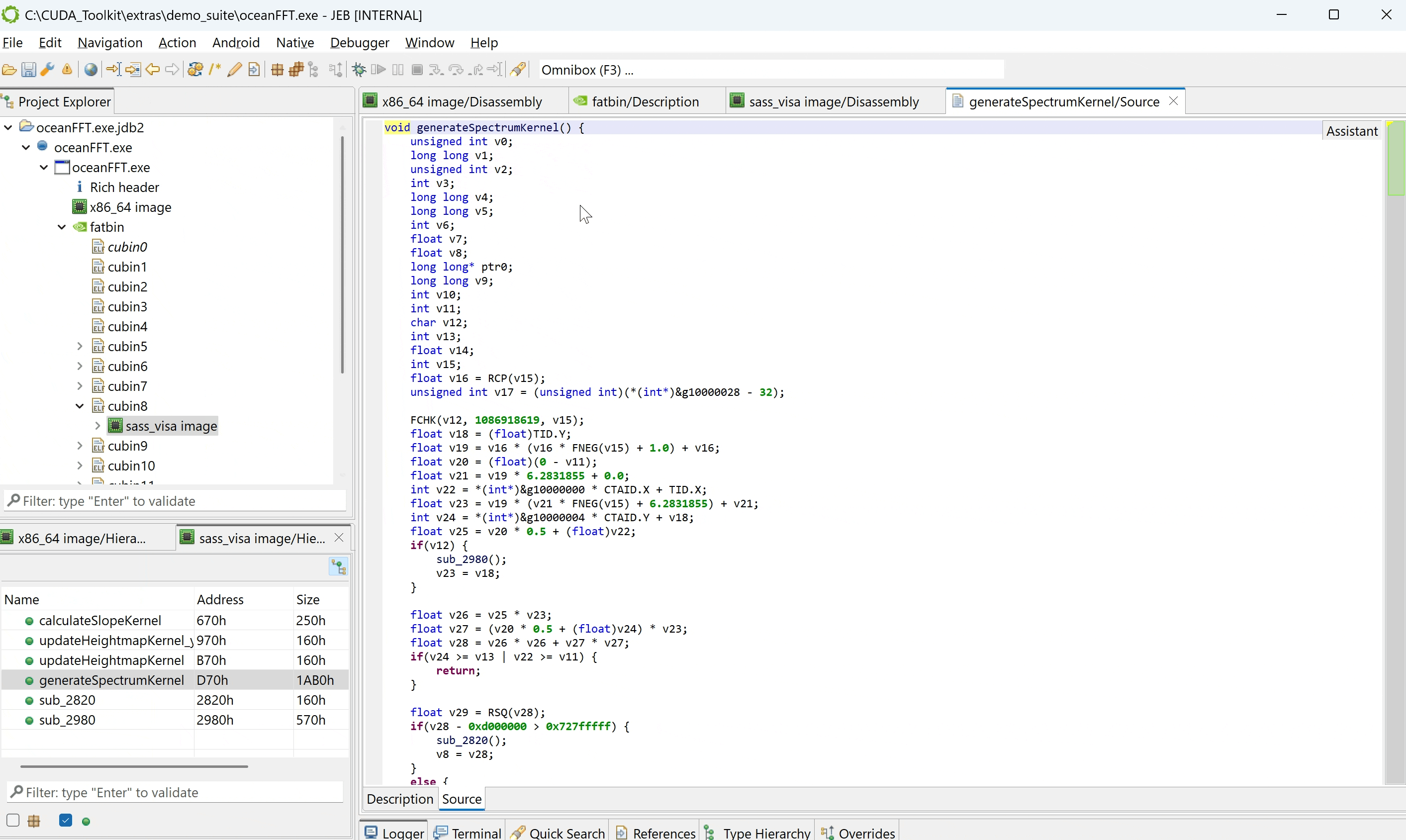
Sample decompilation
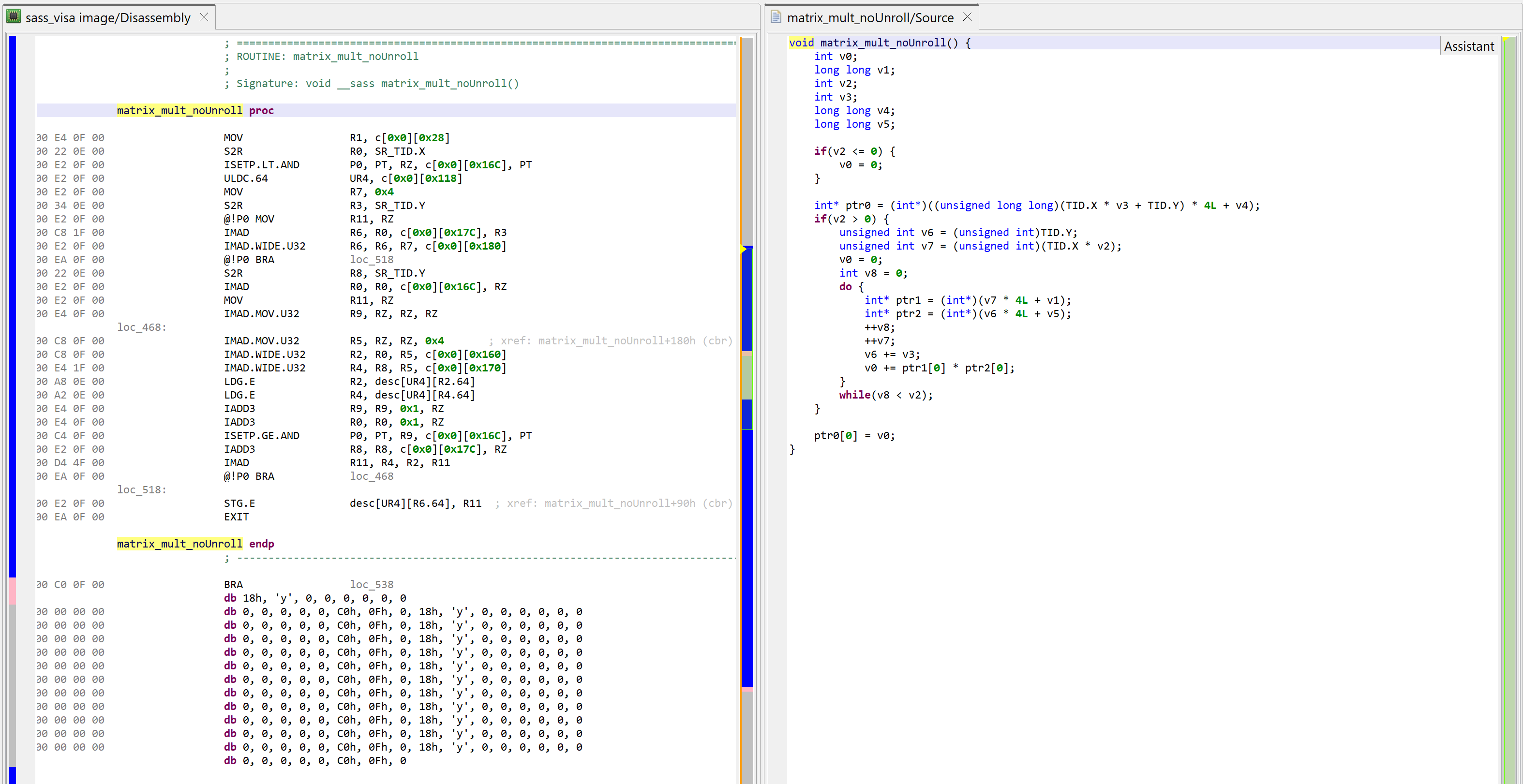
Have a look at the simple CUDA kernel below:
// matrix_mult.cu
__global__ void matrix_mult(int* m1, int m1_nrows, int m1_ncols, int* m2, int m2_nrows, int m2_ncols, int* mr) {
int v = 0;
for(int i = 0; i < m1_ncols; i++) {
v += m1[threadIdx.x * m1_ncols + i] * m2[i * m2_ncols + threadIdx.y];
}
mr[threadIdx.x * m2_ncols + threadIdx.y] = v;
}
For the sake of example, let’s compile this kernel with full optimizations except for loop unrolling (#pragma unroll 1 on the for-loop). The decompiled code looks as follows:
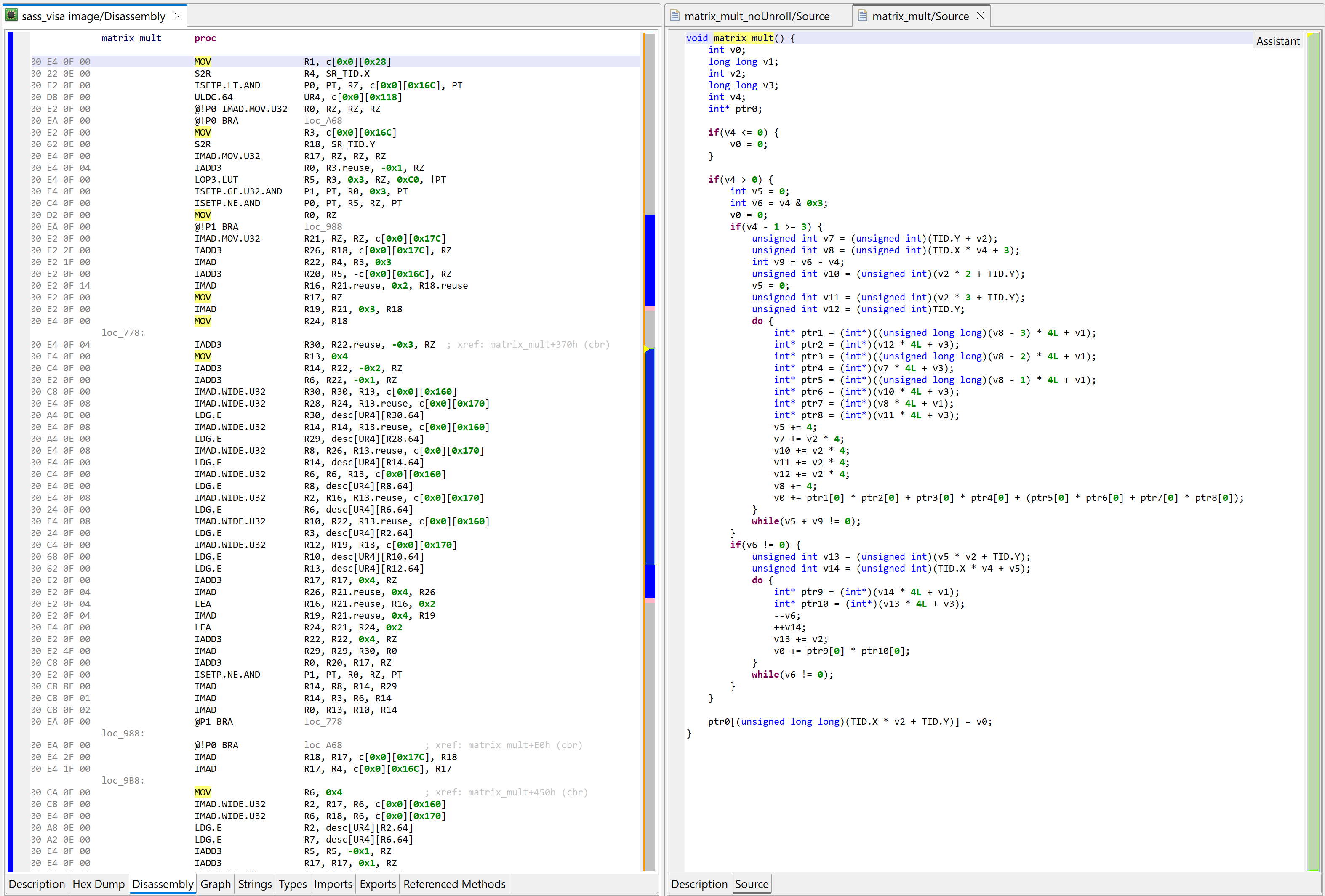
Below, the same matrix multiplication kernel compiled with full optimizations, including loop unrolling 7, which will increase the size of code substantially, and make readability much worse:
Limitations
The sub sections below describe some of the decompiler plugin’s design and implementation choices, as well as list some limitations and avenues of improvement that may be considered in future updates.
IR Conversion
Many classes of instructions are fully converted to precise IR. However, not all SASS instructions’ semantics are clearly understood or have been figured out. In some cases, the decompiler won’t be able to generate precise low-level IR to represent an instruction.
- Partial conversion: some instructions are only partially converted. For instance, at the time of writing, only the 4-operand version of
FMNMXis converted to precise IR. The 5-operand variant is not, and will yield an “untranslated IR” statement, eventually represented as pseudo-C code such asFMNMX(inputs, outputs). - Missing conversion: some instructions are not converted at all. For instance, synchronization primitives such as
ELECTorVOTEwill be mapped to untranslated IR statements.
Future updates: Another limitation regards the handling of BRX branching instruction, which relies on a fixed-size jump table to perform a jump. Currently, the table (located in the cubin) is not processed, potentially yielding sub-par results regarding the actual targets of such instructions.
Memory Mapping
GPU kernels execute in environments that do not match how JEB’s gendec abstracts code and memory. When processing an artifact, JEB places all code and data in a unified, potentially arbitrarily-long virtual memory. By contrast, GPU codes are run in isolation, and can access several memory areas that are also isolated from each other. In order to reconcile those views, the plugin organizes bytes as follows:
- Kernel codes will be found in the first 256 Mb of the VM. Each kernel (included its private sub-routines, when they have been identified) starts at the nearest 8-byte rounded address, following the previous kernel.
- The constant memory, represented in SASS as
c[bankId][offset]is mapped at address 0x1000’0000. Each bank has an arbitrary max size of 0x0100’0000 bytes. - The shared and local memory (e.g. accessed by
STS/LDSorSTL/LDL) is mapped at 0x3000’0000. - There is no explicit stack pointer.
Future updates: The values of global constants are located in specific segments of the cubin. Currently, those segments are ignored by the decompiler plugin. Similarly, resolved global symbols to e.g. external API routines such as libc’s, are located in constant pools.
Calling Conventions
A kernel entry-point (__global__ methods) has a well-defined calling convention — though not well-documented. Kernels return void, and all output data is written through pointers passed as arguments. The arguments are mapped to the constant memory bank 0, at the following offsets:
– sm_70 to sm_89: 0x160
– sm_90: 0x210
– sm_100 to sm_12x: 0x380
Currently, the plugin generates no-output/no-input prototypes (i.e., void kernel()) for all kernels, and replaces memory accesses to mapped parameters by synthetic variables. Some simplified example: a 32-bit memory access to c[0][0x160] (resulting in *(int32*)(0x10000160) at the IR level) will be replaced by an EVar named “arg0”.
Future updates: Special calling convention may be created to allow the definition and customization of such vars at the prototype level.
Kernel sub-routines (__device__ methods that have not been inlined) do not have well-defined calling conventions. The compiler is free to save and use whatever registers it sees fit before invocation. The SASS decompiler plugin does not handle such methods very well at the time of writing, since it does not know which registers are written to provide the return value.
Future updates: A global pass may examine the callers of kernel sub-routines to infer which registers are saved, which are used to provide arguments, and which hold return values.
Optimizations
The matrix multiplication example above highlighted the importance of loop unrolling in the compilation process to obtain better performance for GPU code. However, this compiler-level optimization produces lengthy and difficult pseudo C decompilations.
Future updates: Having a special IR optimizer that attempts to re-roll some loops will be an important step toward producing readable decompiled code for large kernels. 8
API and headless processing
The usual JEB APIs can be used to access container units (IELFUnit, IPECOFFUnit), code units (INativeCodeUnit), and decompiler units (INativeDecompilerUnit).
The CUDA fatbin units, of type cuda_fatbin, is represented by the newly-added interface ICudaFatbinUnit. The getCubinEntries() method provides ICudaCubinEntry objects. That interface offers an easy way to retrieve flags or architecture information about a cubin. The code itself (in the case of a SASS entry) is located in ELF units that are children (sub-units) of a fatbin unit.
Conclusion
This plugin provides flexible and robust disassembly and analysis for Nvidia code generated for Volta and above classes of GPUs. It was tested on 100+ millions unique instructions making up approximately 620,000 kernels (from sm_70 to sm_121) to ensure full compatibility with the outputs of cuobjdump and nvdisasm.
The experimental decompiler plugin can be used to examine a higher-level representation of the underlying SASS code. At the time of writing, the output is quite rough and will require more source binary information extraction and code optimization in order to match the one of mature decompiler plugins.
⚠ Improvement to this plugin will mostly depend on user feedback! If you find it useful, please reach out to us (email, Slack) and let us know your requirements, use-cases, and areas where you’d like to see improvements.
I want to extend a special thank you note to the author of DocumentSass, which was a great help during the early weeks of this research project.
Thank you & until next time 🙂 Nicolas.
Annex 1: Instructions Distribution
To create the SASS disassembler, we examined 62,000 kernels shipping with the CUDA toolkit as well as other commercial applications. It made up for about 1.1 million unique instructions. It is unlikely this set is representative of all commercial GPU code, but we provide those numbers for the most curious readers:
# Top distributions, per-kernel
# Example: BRA is seen in all kernels,
# whereas BAR is seen in about every other kernel
BRA 100.00%
EXIT 98.35%
NOP 98.08%
IMAD 96.85%
ISETP 96.81%
S2R 95.75%
LDG 93.75%
IADD3 93.19%
STG 88.71%
SHF 82.59%
LOP3 79.81%
LEA 79.35%
BSYNC 74.03%
BSSY 74.03%
MOV 67.91%
SEL 59.34%
ULDC 58.22%
LDS 53.43%
STS 53.41%
BAR 51.81%
# ...
# full list: sass_insn_per_kernel_distribs.txt
# Most common, in descending order
# Example: IMAD (integer multiply-and-add) is by far
# the most common instruction encountered
IMAD
ISETP
IADD3
FFMA
LDG
BRA
LEA
NOP
LDS
LOP3
MOV
SHF
FMUL
STS
FADD
DFMA
PRMT
SEL
# ...
# full list: sass_insn_most_common.txt
—
- SASS= Streaming Assembly, the hybrid RISC/NISC/VLIW-like proprietary instruction set used by Nvidia GPUs ↩
- CUDA= Compute Unified Device Architecture, a computing platform and set of APIs to write and run code on GPUs ↩
- PTX= Parallel Thread Execution, a medium-level intermediate representation of GPU code ↩
- A compiled list of all special registers gathered from sm_70 to sm_121 can be consulted here: sass_special_registers.txt. Not all registers are available on all architectures. Many can be accessed in PTX through similarly-named variables, e.g.
%tid.xforSR_TID.X. ↩ - SASS instructions do not use a mixed operand (src+dst) such as on the x86 architecture. ↩
- JEB “actions” are not specific to the SASS plugin. New users are encouraged to read the Manual pages if they are not familiar with JEB’s commands and workflow. ↩
- ptxas does a lot of loop unrolling to maximize instruction-level parallelism and achieve better throughput. ↩
- On its own, a generic re-roller is quite an endeavor and will make for a great research project that would benefit both gendec and its Dex counterpart, dexdec. ↩